






Kafka自0.9.0.0版本引入了配额管理(quota management),旨在broker端对clients发送请求进行限流(throttling)。目前Kafka支持两大类配额管理:
- 网络带宽(network bandwidth)配额管理:定义带宽阈值来限制请求发送速率,阈值单位是字节/秒,即bytes/s。该功能是0.9.0.0版本引入的
- CPU配额管理:定义CPU使用率阈值来限制请求发送速率,阈值以百分比的形式给出,如quota = 50表示50%的CPU使用率上限。该功能是0.11.0.0版本引入的
目录
配额能做什么
设置了基于带宽的配额之后,Kafka能够做到:
1. 限制follower副本拉取leader副本消息的速率
2. 限制producer的生产速率
3. 限制consumer的消费速率
为什么需要配额
生产者和消费者的可能生产/消费非常大量的数据,从而垄断了broker的资源,引起网络饱和,配额可防止这个问题。在大型多节点集群中更加重要。其中有一小部分不良行为的用户将被降权。事实上,当kafka作为服务运行时,可以根据约定好的协议执行API限制。
配额的作用域
Kafka配额管理所能配置的对象(或者说粒度)有3种:
1、user + clientid
2、user
3、clientid
这3种都是对接入的client的身份进行的认定方式。其中,clientid是每个接入kafka集群的client的一个身份标志,在ProduceRequest和FetchRequest中都需要带上;user只有在开启了身份认证的kafka集群才有。即如果kafka客户端是认证的,那么可以使用userId和clientId两种认证方式。如果没有认证只能使用clientId限流。
可配置的选项包括:
producer_byte_rate。发布者单位时间(每秒)内可以发布到单台broker的字节数。
consumer_byte_rate。消费者单位时间(每秒)内可以从单台broker拉取的字节数。
优先级
首先,我们需要明白,kafka在管理配额的时候,是以“组”的概念来管理的。而管理的对象,则是producer或consumer到broker的一条条的TCP连接。那么在进行额度管理的时候,kafka首先需要确认,这条连接属于哪个“组”,进而确定当前连接是否超过了所属“组”的总额度。
为user和client-id分组定义配额配置。可根据自身需要去覆盖默认的配置,这个机制类似于topic日志配置覆盖。用户和(user, client-id)配额覆盖写在ZooKeeper的/config/users下,client-id配额覆盖写在/config/clients下。这些配置被所有broker读取,并立即生效。并且我们更改配置而无需重启整个集群。点击这里查看更多细节。每个分组默认的配额也可使用相同的机制来动态地更新。
在进行“组”判定的时候,依照以下的优先级从高到低顺序依次判定:
1. /config/users/<user>/clients/<client-id>
2. /config/users/<user>/clients/<default>
3. /config/users/<user>
4. /config/users/<default>/clients/<client-id>
5. /config/users/<default>/clients/<default>
6. /config/users/<default>
7. /config/clients/<client-id>
8. /config/clients/<default>
一旦找到了符合的“组”,即中止判定过程。
当多条配额规则冲突时我们可以根据以上规则确定应用的是哪一条。举个例子,我们为user = 'user1'的用户配置了100MB/s的配额,同时为[user='user1', client id = 'producer-1']设置配额为50MB/s,那么当user1用户使用名为‘producer-1’的producer发送消息时Kafka保证它的请求处理速率不会超过50MB/s,即第二条规则覆盖了第一条规则。
如何配额设置
可以通过两种方式来作配额管理:
- 在配置文件中指定所有client-id的统一配额。
设置broker端参数quota.consumer.default。比如quota.consumer.default=15728640表示将连入该broker的所有consumer的TPS降到15MB/s以下。此参数的好处在于全局生效简单易用,对broker上所有consumer都是”一视同仁“;缺陷也在于此,无法单独为个别consumer限速,故该方法在0.11.0.0版本之后已经不推荐使用。
- 动态修改zookeeper中相关znode的值,可以配置指定user,client-id等三种纬度设置
配额的配额。
使用第一种方式,必须重启broker,而且还不能针对特定client-id设置。所以,推荐大家使用第二种方式。
第二种方式可以使用官方脚本修改配额
kafka官方的二进制包中,包含了一个脚本bin/kafka-configs.sh,支持针对user,client-id,(user,client-id)等三种纬度设置配额(也是通过修改zk来实现的)。
- 配置user
- 配置client-id
- 配置user+clientid
●限制follower副本拉取leader副本消息的速率
方法1: 设置broker端动态参数leader.replication.throttled.rate和follower.replication.throttled.rate。
前者控制leader副本端处理FETCH请求的速率,后者控制follower副本发送FETCH请求的速率。既然是动态参数,说明它们的值可以实时修改而无需重启broker。假设我要为broker 11和33设置follower和leader限速为100MB/s,方法如下:

执行下列命令检查下是否配置成功:
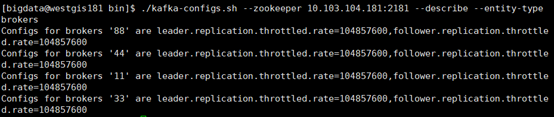
同时,还必须为topic设置leader.replication.throttled.replicas和follower.replication.throttled.replicas 。这组参数需要指定要限速的副本,如果想让topic的所有副本都生效,可以使用*通配符:
![]()
方法2:执行分区重分配时设置
在使用kafka-reassign-partitions.sh(bat)脚本执行分区重分配时也可以设定 ,方法如下(依然设置成100MB/s):
./kafka-reassign-partitions.sh --zookeeper 10.103.104.181:2181 --execute --reassignment-json-file to-be-reassigned.json --throttle 104857600
实际上,该脚本通过--throttle参数间接设置了leader.replication.throttled.rate和follower.replication.throttled.rate参数,故本质上和方法1是相同的。值得注意的,该脚本只会对参与到分区重分配的broker设置配额,对其他broker是不起作用的。
●限制producer端速率
方法1: 设置broker端静态参数quota.producer.default参数
比如:在server.properties中加入quota.producer.default=15728640将限制所有连入该broker的producer的TPS全部降到15MB/s以下。设置此参数的好处是能够限制集群上的所有producer,但劣处也在于此,对所有producer“一视同仁”,无法细粒度地对个别clients进行设置。故社区在0.11.0.0版本将其标记为"Deprecated",并始终推荐用户使用动态参数的方式来为producer端进行限速。
方法2:设置动态参数producer_byte_rate
首先演示为所有client id设置默认值,假设我们为所有producer程序设置其TPS不超过100MB/s,即104857600B/s,然后我们为client.id=‘producer-1'的producer单独设置其TPS不超过50MB/s,即52428800B/s,如图:

下面做个简单的试验验证下,我们启动两个client.id是producer-1和producer-2的producer程序去验证它们的TPS小于设置的阈值(测试5242880条大小为1KB的消息,即大约为5GB数据):
可见producer-2的TPS被限制在了100MB/s以下
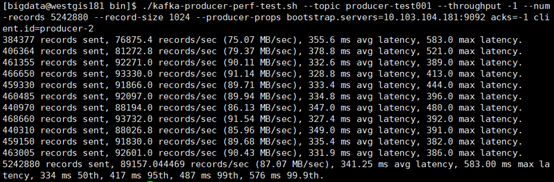
可见producer-1的TPS被限制在了50MB/s以下

为所有user设置默认值,假设我们为所有producer程序设置其TPS不超过100MB/s,即104857600B/s,然后我们为特定用户user1的producer单独设置其TPS不超过50MB/s,即52428800B/s,如图:

在zookeeper上面可以查看限流的信息:

最后是设置(user + client id)作用域设置配额。依然是全局默认值:
user1的client id默认配额和producer-1的user默认配额:

在zookeeper上面可以查看限流的信息:

producer-1的user默认配额,可见每两次的平均吞吐率限制在了20MB

在jconsole监控界面可以看到每秒传输的字节为19MB/s左右

然后是特定值:
user1 + producer-1的配额值
![]()
在zookeeper上面可以查看限流的信息:
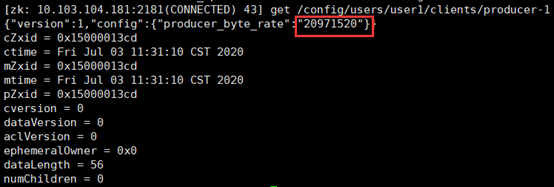
./kafka-configs.sh --zookeeper 10.103.104.181:2181 --alter --add-config 'producer_byte_rate=52428800' --entity-type clients --entity-name producer-1此命令只为client.id=producer-1的consumer设置了限速,故在Spark端你还需要显式设置client.id,比如:
Map<String,Object>kafkaParams=newHashMap<>();
...
kafkaParams.put("client.id","clientA");
...
JavaInputDStream<ConsumerRecord<String,String>>
stream=KafkaUtils.createDirectStream(...);
值得注意的是,在Kafka端设置的限速单位都是每秒字节数。如果你想按照每秒多少条消息进行限速还需要结合消息的平均大小来计算。
●限制consumer端速率
限制consumer端速率
和producer类似,也存在两种方法:
方法1: 设置broker端静态参数quota.consumer.default参数
与quota.producer.default完全相同的参数,只不过是适用于consumer端的,不再赘述。
方法2:设置动态参数consumer_byte_rate
与producer_byte_rate完全对等的参数,只是适用于consumer端的,这里略诉
为所有client id设置默认值,假设我们为所有consumer程序设置其TPS不超过1000MB/s,即1048576000B/s,然后我们为client.id=‘producer-1'的producer单独设置其TPS不超过20MB/s,即20971520B/s,如图:

下面做个简单的试验验证下,我们启动两个client.id是consumer002和consumer001的pconsumer程序去验证它们的TPS小于设置的阈值(测试5242880条大小为1KB的消息,即大约为5GB数据):
可见producer-2的TPS被限制在了1000MB/s以下

直接写zookeeper修改配额
如果我们希望能够在代码里面直接写zk来实现配额管理的话,那要怎样操作呢?
假定我们在启动kafka时指定的zookeeper目录是kafka_rootdir。
1、配置user+clientid。例如,针对”user1”,”clientA”的配额是10MB/sec,其它clientid的默认配额是5MB/sec。
<1>znode: ${kafka_rootdir}/config/users/user1/clients/clientid; value: {"version":1,"config":{"producer_byte_rate":"10485760","consumer_byte_rate":"10485760"}}
<2>znode: {kafka_rootdir}/config/users/user1/clients/<default>; value: {"version":1,"config":{"producer_byte_rate":"5242880","consumer_byte_rate":"5242880"}}
2、配置user。例如,”user2”的配额是1MB/sec,其它user的默认配额是5MB/sec。
<1>znode: ${kafka_rootdir}/config/users/user1; value: {"version":1,"config":{"producer_byte_rate":"1048576","consumer_byte_rate":"1048576"}}
<2>znode: ${kafka_rootdir/config/users/<default>; value: {"version":1,"config":{"producer_byte_rate":"5242880","consumer_byte_rate":"5242880"}}
3、配置client-id。例如,”clientB”的配额是2MB/sec,其它clientid的默认配额是1MB/sec。
<1>znode:${kafka_rootdir}/config/clients/clientB'; value:{“version”:1,”config”:{“producer_byte_rate”:”2097152”,”consumer_byte_rate”:”2097152”}}</li>
<li>znode:${kafka_rootdir}/config/clients/; value:{“version”:1,”config”:{“producer_byte_rate”:”1048576”,”consumer_byte_rate”:”1048576”}}`
无论是使用官方的脚本工具,还是自己写zookeeper,最终都是将配置写入到zk的相应znode。所有的broker都会watch这些znode,在数据发生变更时,重新获取配额值并及时生效。为了降低配额管理的复杂度和准确度,kafka中每个broker各自管理配额。所以,上面我们配置的那些额度值都是单台broker所允许的额度值。
配额算法
简单来说,我们假设当前实际值是O,T是我们设置的阈值,而W表示某一段时间范围,我们希望在W时间内O能够下降到T以下(如果O本来就比T小,则什么都不用做),那么broker端就需要延缓等待一段时间。如果假设这段时间是X,那么以下等式成立:
O * W = (W + X) * T
由此得出X = (O - T) / T * W。这就是Kafka用于计算等待时间的公式。当然在具体实现时,Kafka提供了两个参数来共同计算W:W = quota.window.num * quota.window.size.seconds。前者表示取样的时间窗口个数,后者表示时间窗口大小。特别是后者会在CPU配额管理中用到。不过在本文中,我们可以统一使用W即可。当Kafka检测到配额透支情况发生时,broker不会返回错误而是直接将超支配额的客户端进行减速处理。它会计算需要X然后令client强制sleep直至令其降到配额之下。该方法对于client来说完全透明。同时,client也不需要自己实现任何特殊的策略来应对。事实上,有的client在应对这种情况时会不停地重试反而加剧了本要解决的问题。
超额处理
如果连接超过了配额值会怎么样呢?kafka给出的处理方式是:延时回复给业务方,不使用特定返回码。
具体到producer还是consumer,处理方式又有所不同:
Producer。如果Producer超额了,先把数据append到log文件,再计算延时时间,并在ProduceResponse的ThrottleTime字段填上延时的时间(v2,只在0.10.0版本以上支持)。
Consumer。如果Consumer超额了,先计算延时时间,在延时到期后再去从log读取数据并返回给Consumer。否则无法起到限制对文件系统的读蜂拥。在v1(0.9.0以上版本)和v2版本的FetchResponse中有ThrottleTime字段,表示因为超过配额而延时了多久。
如前所述,限速是在broker端执行的!broker端故意“sleep”来限速的做法虽然对clients端透明,但确实也会引起clients端请求的超时,故在实际使用过程中适当地增加request.timeout.ms对于启用了限速的Kafka环境而言就显得非常必要了。
附加
上述是kafka端限速
Spark端限速的方法主要的思路是设置不同的参数,比如在Direct模式下设置spark.streaming.kafka.maxRatePerPartition,receiver模式下设置spark.streaming.receiver.maxRate。它们都是控制每秒处理的消息数。应该说目前使用Direct模式的比较多,因此你需要适当地调整spark.streaming.kafka.maxRatePerPartition值。















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









