







目录
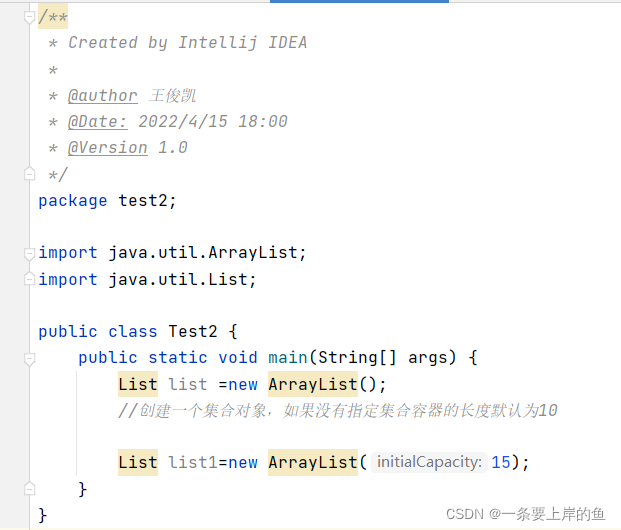
2. ArrayList有参构造: ArrayList(int initialCapacity)
6. 查找集合中某个元素的位置: indexOf(Object o)
1.集合框架
概念
- 数据结构
- ArrayList:数组集合。
- linkedList:双向链表集合。
- HashMap:数组+链表。
Java集合框架(Java Collections Framework简称JCF)是为表示和操作集合,而规定的一种统一的标准的体系结构。集合框架包含三大块内容:对外的接口、接口的实现和对集合运算的算法。
集合就是用于存储对象的容器。 只要是对象类型就可以存进集合框架中。集合的长度是可变的。 集合中不可以存储基本数据类型的值
1.1集合和数组的区别
数组和集合相比,数组的缺点是它长度是固定的,没有办法动态扩展。
而集合存储数据时是没有长度限制的,是可以动态扩展的。集合容器因为内部的数据结构不同,有多种不同的容器对象。这些容器对象不断的向上抽取,就形成了集合框架。
手撕可变长度的容器



我们自己可以手动写一个可变的容器,那么别人也可以手写可变的容器。
Java官网 基于数组 根据不同的数据结构 创建了多个类 而这些类统称为集合框架
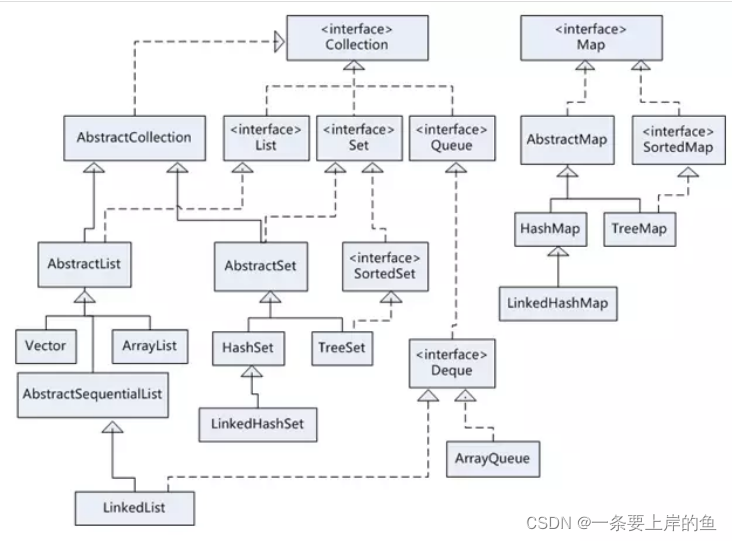
1.2集合的架构

1.3List集合
- List集合是有序集合: 数据的添加和存储次序一致
- List集合可以存储重复的数据
- List集合中的数据可以通过下标访问


1.30 创建集合对象
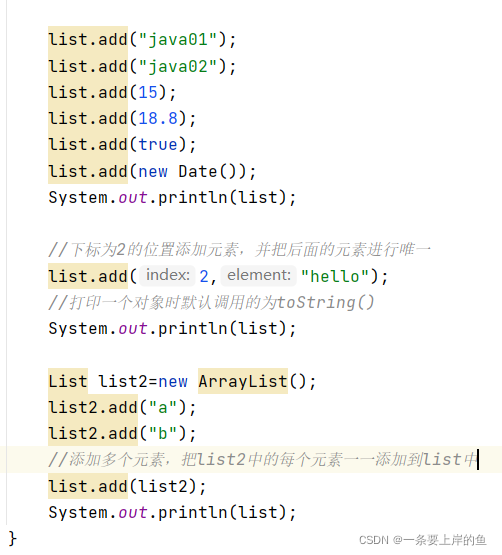
1.31 添加的操作
1.3.2 删除的操作

1.3.3 修改的操作

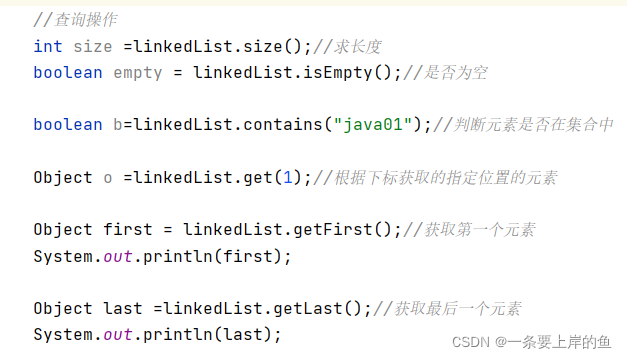
1.3.4 查询操作


1.4.1 ArrayList底层源码
对于ArrayList而言,它实现List接口、底层使用数组保存所有元素。其操作基本上是对数组的操作
1. ArrayList无参构造: ArrayList()
public ArrayList() {
//elementData 是ArrayList 底层实际存储数据的对象数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
transient Object[] elementData; // non-private to simplify nested class
accessprivate static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};说明: 当new ArrayList的时候,本质就是创建了一个空的Object类型的数组
2. ArrayList有参构造: ArrayList(int initialCapacity)
// initialCapacity:初始容量
public ArrayList(int initialCapacity) {
if (initialCapacity > 0)
{ // 初始容量大于0,则按初始容量创建数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 初始容量是0,则赋值一个空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 初始容量小于0,则报错
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}3. 添加元素: add(E e) 扩容原理
public boolean add(E e) {
// 扩展数组容量
ensureCapacityInternal(size + 1); // Increments modCount!!
// 将数据存储到数组中,并且元素个数加 1
elementData[size++] = e;
return true;
}
// 扩容具体实现1
private void ensureCapacityInternal(int minCapacity) {
// 判断当前ArrayList底层是否是空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 如果要扩容的容量小于10,则直接按10个长度扩容
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
} ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
// 判断当前数组长度如果小于要扩容的长度,则执行grow
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 第一次最小容量是10
private void grow(int minCapacity) {
// overflow-conscious code
// 初始长度0
int oldCapacity = elementData.length;
// 新容量0
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
// 新容量变为10
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//Arrays.copyOf:进行数组扩容,扩容到指定长度
elementData = Arrays.copyOf(elementData, newCapacity);
}
小结: ArrayList添加元素的时候,会进行数组扩容 第一次扩容到10,第二次扩容到15
4.删除元素: remove(Object o)
public boolean remove(Object o){
//判断要删除的数据是否为空
if(o==null){
for(int index=0;index<size;index++)
if(elementDate[index]==null){
fastRemove(index);
return true;
}else{
//数据不为空的删除
for (int index = 0;index<size;index++)
if(o.equals(elementDate[index])){
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index){
modCount++;
int numMoved = size - index -1;
if(numMoved>0)
//通过复制的方式,删除元素
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
}5.清空集合: clear()
//将数组每个元素设置为空,长度为0
public void clear(){
modCount++;
//clear to let GC do its work
for(int i=0;i<size;i++)
elementDate[i] = null;
size = 0;
}6. 查找集合中某个元素的位置: indexOf(Object o)
//查询某个元素的位置
public int indexOf(Object to){
if( o == null){
for(int i =0;i<size;i++)
if(elementDate[i]==null)
return i;
}else{
for (int i=0;i<size;i++)
if(o.equals(elementDate[i]))
return i;
}
return -1;
}7. 返回集合元素长度:size()
public int size(){
//记录了元素的个数
return size;
}ArrayList
-
- ArrayList底层实现是基于数组的,因此对指定下标的查找和修改表较快,但是删除和插入操作比较慢。
- 构造ArrayList时尽量指定容量,减少扩容时带来的数组复制操作,如果不知道大小可以复制为默认容量10。
- 每次添加元素之前会检查是否需要扩容,每次扩容都是增加原有容量的一半。
- 每次对下标的操作都会进行安全性检查,如果出现数组越界就立即抛出异常。
- ArrayList的所有方法都没有进行同步,因此它不是线程安全的。
ArrayList的底层原理
我们查看ArrayList底层原理 首先从构造函数开始看起
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
当我们上层调用: List haha = new ArrayList(100); 其实底层帮我们创建了一个Object[]数组
也就是说 ArrayList 底层就是一个 Object[] 数组
所以我们调用 haha.add("张三") 其实底层就是
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!! 容量是否够 不够要扩容
elementData[size++] = e;
return true;
}
我们继续查看扩容代码 ensureCapacityInternal(size + 1)
private void ensureCapacityInternal(int minCapacity) {
// 数组是否为 空数组 -- 容量为 0
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 重新规划容量
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 继续扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
所以 Object o = haha.get(1); 其实底层就是 从数组中根据索引获取对应数据
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
所以 boolean empty = haha.isEmpty(); 其实底层就是 size是否为零
public boolean isEmpty() {
return size == 0;
}
所以 int size = haha.size(); 其实底层就是 返回值 size的值
所以 int index = haha.indexOf("张三"); 其实底层就是 遍历 查找对应的数据 有返回值索引 没有返回-1
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
所以 boolean contains = haha.contains("张三"); 其实底层就是 判断首次出现的索引是否大于零
public boolean contains(Object o) {
return indexOf(o) >= 0;
}1.4.2LinkedList
LinkedList: 具有List的特征,底层以链表结构实现,可以进行头尾元素的添加删除
添加操作

删除操作

修改操作

查询操作
LinkedList的底层源码
1.凡是查询源码 ,我们都是从类的构造方法入手:
public LinkedList(){
}
//该类的构造方法内是空的 没有任何的代码 但是该类中有三个属性
transient int size =0; //索引
transient Node<E> first; //第一个元素对象
transient Node<E> lase; //最后一个元素对象
---------add的源代码------E:理解为Object类型--------------
public boolean add(E e){
linkLast(e);
return true;
}
void linkLast(E e){
final Node<E> l =last;
final Node<E> newNode = new Node<>(l,e,unll);
last = newNode;
if(l==null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
---------Node的源代码 内部类-------------
private static class Node<E> { //<E>泛型--object
E ietm; //属性
Node<E> next; //下一个节点
Node<E> prev; //上一个节点
Node(Node<E> prev,E element, Node<E> next){
this.item = element;
this.next = next;
this.prev = prev;
}
}
-----------------get(1)----获取元素---------------------
public E get(int index){
checkElementIndex(index);//检查index下标是否正确
return node(index).item;//李四Node对象
}
-----------------node(index)-----------------------
Node<E> node (int index){
//>>为二进制运算 -----size >> 1 一半的意思 size/2
if(index < (size >> 1)){ //前半部分
Node<E> x = first;
for (int i=0;i<index;i++)
x=x.next;
return x;
}else { //后半部分
Node<E> X =last;
for(int i=size-1;i>index;i--)
x =x.prev;
return x;
}
}
分析: LinkedList查询效率低。因为它要一个节点一个节点的往后找
LinkedList
-
- LinkedList是基于双向链表实现的,不论是增删改查方法还是队列和栈的实现,都可以通过操作结点实现。
- LinkedList无需提前指定容量,因为基于链表操作,集合的容量随着元素的加入自动增加。
- LinkedList删除元素后集合占用的内存自动缩小,无需像ArrayList一样调用trimToSize()
- 方法。
- LinkedList的所有方法没有进行同步,因此它也不是线程安全的,应该避免在多线程环境下使用。
- LinkedList根据index查询时采取的是二分法,即index小于总长度一半时从链表头开始往后查找,大于总长度一半时从链表尾往前查找。如果是根据元素查找,则需要从头开始遍历。
LinkedList接口定制规则
我们发现 无论使用 ArrayList 还是 LinkedList 使用方式基本一样
增 add 删 remove 改 set 查 get
说明Java在封装的时候 有意为之
但是不一样的集合框架类 是不一样的程序员写的 肯定不一样 就好像一个人有一万个哈姆雷特
写出来的不一样 coder在使用的时候 就麻烦了所以需要他们写的方法名一样 整体的思路就是 设定一个接口 List add remove set get 定制规则
LinkedList底层原理
当我们创建 LinkedList haha = new LinkedList(); 构造函数式是这样的:
public LinkedList() { }
说明单纯的创建了一个对象,之前学习的语法告诉我们 对象创建的时候 会将成员变量一同创建到堆区
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
我们还能猜出来 Node 是一个对象类型
private static class Node<E> {
E item; //数据
Node<E> next;//下一个
Node<E> prev;//上一个
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
此时当我们调用add 的时候
public boolean add(E e) {
linkLast(e);
return true;
}
我们再次查看linkLast函数
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} 
当添加完成 调用Object o = haha.get(3);的时候 感觉是像是操作索引 其实不然
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
node(index) 这个方法用来找到对应索引的node对象
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}1.5. Set集合
1.5.1HashSet集合
1.5.2 创建对象

1.5.3 添加元素

1.5.4 删除元素

1.5.5 修改元素
Set没有下标 无法修改

1.5.6 hashSet的遍历

1.5.7 hashSet的源码
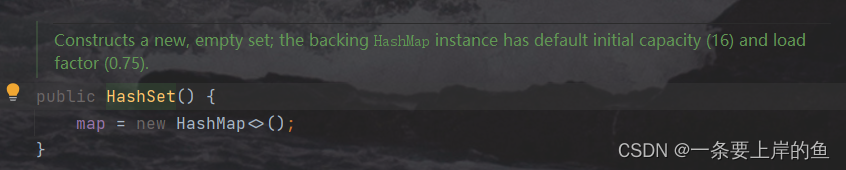
hashSet的源代码也是从构造函数说起
public HashSet() {
map = new HashMap<>();
}在创建一个HashSet的对象时,底层创建的是HashMap。我们说hashset的底层原理时,我们就在后HashMap的原理就行。 讲HashMap时给大家说原理
HashSet迭代器获取数据
@Test
public void test03(){
Set set = new HashSet();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");
set.add(null);
// [null, 李四, 张三, 王五] 无序 去重 可以为null
System.out.println(set);
Iterator iterator = set.iterator();
while ( iterator.hasNext() ){
Object next = iterator.next();
System.out.println(next);
}
}HashSet的底层原理
1.6 TreeSet集合
TreeSet中的方法和HashSet中的方法一模一样 只是他们的实现不一样
TreeSet 基于TreeMap实现 TreeSet可以实现有序集合,但是有序性需要通过比较器实现
1.6.1存储String类型

1.6.2 存储一个对象类型:

通过运行我们会发现以下两个错误:

发现:TreeSet中的元素必须实现Comparable接口 就可以放入TreeSet

解决办法当然是有的


1.7 Map属于键值对模式
map中的每个元素属于键值对模式。 如果往map中添加元素时 需要添加key和value 它也属于一个接口,该接口常见的实现类有:HashMap.
1.7.1 如何创建Map对象

1.7.2 添加操作

1.7.3 删除操作

1.7.4 修改操作

1.7.5 查询操作

HashMap
-
- 哈希表是由数组和单向链表共同构成的一种结构,上图中一个数组元素链表存在多个元素,说明存在hash冲突,理想情况下每个数组元素只应包含一个元素。
- 扩容原因:hashMap默认的初始容量为16,默认的加载因子是0.75,而threshold是集合能够存储的键值对的阈值,默认是初始容量*加载因子,也就是16*0.75=12,当键值对要超过阈值时,意味着这时候的哈希表已处于饱和状态,再继续添加元素就会增加哈希冲突,从而使hashMap的性能下降。
- 每次扩容都是增加原有容量的一倍
1.8 泛型
1.8.1:什么是泛型?
1. 泛型就是限制我们得数据类型
2.为什么使用泛型?
我们原来在定义集合时,是如下得定义方式:
List list=new ArrayList();//该集合没有使用泛型
list.add("java01");
list.add("java02");
String str= (String) list.get(0);//获取元素 需要进行强制类型转换
System.out.println(str);
获取元素时,不方便对元素进行相应得其他操作。
1.8.2:如何让使用泛型
List<类型> list=new ArrayList<类型>(); 只能在该集合中存储指定得类型。

1.8.3:能否自己定义泛型类
必然可以
public class 类名<标识,标识....> {
标识 变量名;
public 标识 方法名(){
}
public void 方法名(标识 参数名){
}
}
















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









