







目录
1. strlen
函数原型:size_t strlen(const char *str);
strlen返回str中字符的个数,其中str为一个以’\0’结尾的字符串(a null-terminated string)。
1.1 strlen源码简单实现
如果不管效率,最简单的实现只需要4行代码:
size_t strlen_a(const char * str)
{
assert(str != NULL); //检查指针的有效性
size_t length = 0 ;
while (*str++ )
++ length;
return length;
}
也许可以稍加改进如下:
size_t strlen_b(const char * str)
{
const char *cp = str;
while (*cp++ );
return (cp - str - 1 );
}
1.2 strlen源码高效实现
很显然,标准库的实现肯定不会如此简单,上面的strlen_a以及strlen_b都是一次判断一个字符直到发现’\0’为止,这是非常低效的。比较高效的实现如下(在这里WORD表示计算机中的一个字,不是WORD类型):
(1) 一次判断一个字符直到内存对齐,如果在内存对齐之前就遇到’\0’则直接return,否则到(2);
(2) 一次读入并判断一个WORD,如果此WORD中没有为0的字节,则继续下一个WORD,否则到(3);
(3) 到这里则说明WORD中至少有一个字节为0,剩下的就是找出第一个为0的字节的位置然后return。
NOTE:
数据对齐(data alignment),是指数据所在的内存地址必须是该数据长度的整数倍,这样CPU的存取速度最快。比如在32位的计算机中,一个WORD为4 byte,则WORD数据的起始地址能被4整除的时候CPU的存取效率比较高。CPU的优化规则大概如下:对于n字节(n = 2,4,8…)的元素,它的首地址能被n整除才能获得最好的性能。
为了便于下面的讨论,这里假设所用的计算机为32位,即一个WORD为4个字节。下面给出在32位计算机上的C语言实现(假设unsigned long为4个字节):
typedef unsigned long ulong;
size_t strlen_c(const char * str) {
const char * char_ptr;
const ulong * longword_ptr;
register ulong longword, magic_bits;
for (char_ptr = str; ((ulong)char_ptr
& (sizeof(ulong) - 1)) != 0 ;
++ char_ptr) {
if (*char_ptr == '\0' )
return char_ptr - str;
}
longword_ptr = (ulong* )char_ptr;
magic_bits = 0x7efefeffL ;
while (1 ) {
longword = *longword_ptr++ ;
if ((((longword + magic_bits) ^ ~longword) & ~magic_bits) != 0 ) {
const char *cp = (const char*)(longword_ptr - 1 );
if (cp[0] == 0 )
return cp - str;
if (cp[1] == 0 )
return cp - str + 1 ;
if (cp[2] == 0 )
return cp - str + 2 ;
if (cp[3] == 0 )
return cp - str + 3 ;
}
}
}
源码剖析
上面给出的C语言实现虽然不算特别复杂,但也值得花点时间来弄清楚,先看9-14行:
for (char_ptr = str; ((ulong)char_ptr & (sizeof(ulong) - 1)) != 0; ++char_ptr) {
if (*char_ptr == ‘\0’)
return char_ptr - str;
}
上面的代码实现了数据对齐,如果在对齐之前就遇到’\0’则可以直接return char_ptr - str;
第16行将longword_ptr指向数据对齐后的首地址
longword_ptr = (ulong*)char_ptr;
第18行给magic_bits赋值(在后面会解释这个值的意义)
magic_bits = 0x7efefeffL;
第22行读入一个WORD到longword并将longword_ptr指向下一个WORD
longword = *longword_ptr++;
第24行的if语句是整个算法的核心,该语句判断22行读入的WORD中是否有为0的字节
if ((((longword + magic_bits) ^ ~longword) & ~magic_bits) != 0)
if语句中的计算可以分为如下3步:
(1) longword + magic_bits
其中magic_bits的二进制表示如下:
b3 b2 b1 b0
31------------------------------->0
magic_bits: 01111110 11111110 11111110 11111111
magic_bits中的31,24,16,8这些bits都为0,我们把这几个bits称为holes,注意在每个byte的左边都有一个hole。
检测0字节:
如果longword 中有一个字节的所有bit都为0,则进行加法后,从这个字节的右边的字节传递来的进位都会落到这个字节的最低位所在的hole上,而从这个字节的最高位则永远不会产生向左边字节的hole的进位。则这个字节左边的hole在进行加法后不会改变,由此可以检测出0字节;相反,如果longword中所有字节都不为0,则每个字节中至少有1位为1,进行加法后所有的hole都会被改变。
为了便于理解,请看下面的例子:
b3 b2 b1 b0
31------------------------------->0
longword: XXXXXXXX XXXXXXXX 00000000 XXXXXXXX
- magic_bits: 01111110 11111110 11111110 11111111
上面longword中的b1为0,X可能为0也可能为1。因为b1的所有bit都为0,而从b0传递过来的进位只可能是0或1,很显然b1永远也不会产生进位,所以加法后longword的第16 bit这个hole不会变。
(2) ^ ~longword
这一步取出加法后longword中所有未改变的bit。
(3) & ~magic_bits
最后取出longword中未改变的hole,如果有任何hole未改变则说明longword中有为0的字节。
根据上面的描述,如果longword中有为0的字节,则if中的表达式结果为非0,否则为0。
NOTE:
如果b3为10000000,则进行加法后第31 bit这个hole不会变,这说明我们无法检测出b3为10000000的所有WORD。值得庆幸的是用于strlen的字符串都是ASCII标准字符,其值在0-127之间,这意味着每一个字节的第一个bit都为0。因此上面的算法是安全的。
一旦检测出longword中有为0的字节,后面的代码只需要找到第一个为0的字节并返回相应的长度就OK:
const char *cp = (const char*)(longword_ptr - 1);
if (cp[0] == 0)
return cp - str;
if (cp[1] == 0)
return cp - str + 1;
if (cp[2] == 0)
return cp - str + 2;
if (cp[3] == 0)
return cp - str + 3;
strlen错误用法
void main()
{
char aa[10];
printf(“%d”,strlen(aa));
}
问题:
sizeof()和初不初始化,没有关系,
strlen()和初始化有关,打印结果值未知。
2. strcpy
2.1 strcpy源码
//返回char*的原因是 可以在其他函数中直接调用。
char * strcpy(char *dst,const char *src)//源字符串参数用const修饰,防止修改源字符串
{
assert(dst != NULL && src != NULL); //检查指针的有效性
char *ret = dst; //记下dst的初始地址防止找不到
while ((*dst++=*src++)!='\0'); //将src中所有字符(包括'\0')一个字符一个字符的拷贝到dst(包括'\0')。在赋值完'\0'后,循环停止
return ret;
}
返回char*的原因是 可以在其他函数中直接调用。例如:strcpy(a,strcpy(b,c)),这样c的值copy给b,然后copy给a,那么你就不用写两行代码。
源字符串参数用const修饰,防止修改源字符串
2.2 假如考虑dst和src内存重叠的情况,strcpy该怎么实现
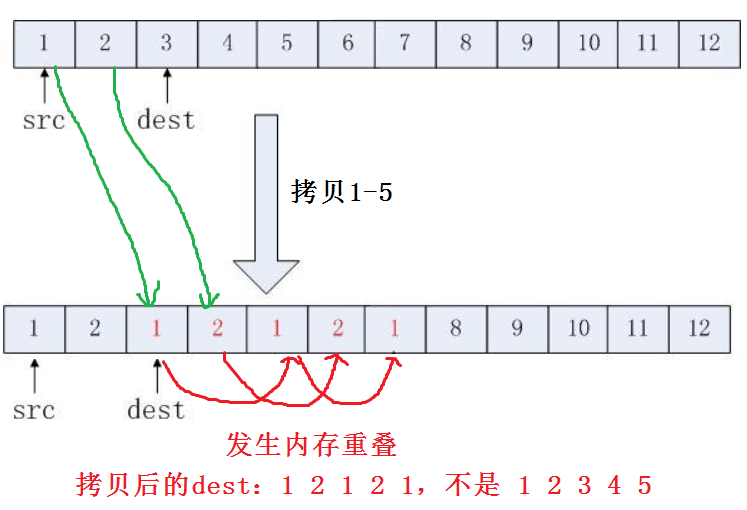
char s[10]="hello";
strcpy(s, s+1); //输出ello,从s的第二个位置开始拷贝。没有内存重叠,但会少拷贝字符。dst<src || dst>=src+strlen(s)+1时,拷贝不会发生内存重叠
char s[10]="hello";
strcpy(s+1, s); //dst>=src && dst<src+strlen(s)+1,会发生内存重叠,
src <= dst <= src + strlen(s)
当目的地址大于等于源地址且目的地址小于源地址+拷贝字符串的长度+1时,会发生内存重叠
不清楚内存重叠,可以看这里:https://blog.csdn.net/Vcrossover/article/details/114714899
解决方法:
- 拷贝时从后往前拷贝
2.3 strcpy错误用法
示例1:
void GetMemory(char *p)
{
undefined p = (char *)malloc(100);
}
void Test(void)
{
undefined char *str = NULL;
GetMemory(str);
strcpy(str, “hello world”);
printf(str);
}
请问运行Test 函数会有什么样的结果?
分析:程序崩溃。因为GetMemory 并不能传递动态内存,Test 函数中的 str 一直都是 NULL。strcpy(str, “hello world”);将使程序崩溃。
执行GetMemory之后,p得到新分配的空间地址,str依然为NULL;
因为函数GetMemory没有返回值,因此str并不指向p所申请的那段内存,所以函数GetMemory并不能输出任何东西。事实上,每执行一次GetMemory函数就会申请一块内存,但申请的内存一直被独占,最终造成内存泄漏。
没有对内存进行回收free(),局部变量存在栈区,malloc()在堆区;局部变量在函数执行完毕之后回收栈空间;
解决:
GetMemory(&str, 100);
如果一定要用指针参数去申请内存,那么应该采用指向指针的指针,传递str的地址给函数GetMemory。
示例2:
void getmemory(char *p)
{
p=(char *) malloc(100);
strcpy(p,“hello world”);
}
错误:getmemory中的malloc 不能返回动态内存
示例3:
int main()
{
char a;
char *str=&a;
strcpy(str,"hello");
printf(str);
return 0;
}
没有为str分配内存空间,将会发生异常
问题出在将一个字符串复制进一个字符变量指针所指地址。
虽然能输出hello,但不能正常运行,因为char a只能存1个字符,存"hello"会抛异常
示例4:
void test1()
{
char string[10];
char* str1 = "0123456789";
strcpy(string, str1);
}
错误:字符串str1有11个字节(包括末尾的结束符’\0’),而string只有10个字节,故而strcpy会导致数组string越界。
3. strncpy
3.1 strncpy源码
char * strncpy ( char * dst, const char * src, size_t count )
{
char *start = dst;
while (count && (*dst++ = *src++)) /* copy string */
count--;
if (count) /* pad out with zeroes */
while (--count)
*dst++ ='\0';
return(start);
}
3.2 考虑内存重叠的strncpy
char *strncpy(char *dst, const char *src, size_t len)
{
assert(dst != NULL && src != NULL);
char *res = dst;
if (dst >= src && dst <= src + len - 1)//重叠,从后向前复制
{
dst = dst + len - 1;
src = src + len - 1;
while (len--)
*dst-- = *src--;
}
else
{
while (len--)
*dst++ = *src++;
}
return res;
}
4. strcat
4.1 strcat源码
char * strcat(char * dest, const char * src)//把 src 所指向的字符串追加到 dest 所指向的字符串的结尾
{
assert(dst != NULL && src != NULL); //检查指针的有效性
char *tmp = dest;//记下dest的初始地址防止找不到
while (*dest)
dest++; //找到dest的末尾
while ((*dest++ = *src++) != '\0'); //将src附加到dest后面
return tmp;
}
while (* dest)
dest++;
不能写成while(* dest++), 因为这样的话为*dest为0时还会+1,导致dest指向了\0的后一个。
5. strcmp
5.1 strcmp源码
int strcmp ( const char* src, const char* dst )
{
assert(dst != NULL && src != NULL); //检查指针的有效性
int ret = 0 ;
while( !(ret = *(unsigned char *)src - *(unsigned char *)dst) && *dst)
++src, ++dst;
if ( ret < 0 )
ret = -1 ;
else if ( ret > 0 )
ret = 1 ;
return( ret );
}
我们要看的是while循环这个语句, ! (ret = *(unsigned char )src - (unsigned char )dst)意思是拿指针变量src所指向的字符值(即src)减去指针变量dst所指向的字符值(即dst),差值赋给ret,再取非运算,最后与dst进行与运算;
! ret表示ret=0才继续比较。
为什么要把src转成unsigned char *类型?
使用*(unsigned char )str1而不是用str1。这是因为传入的参数为有符号数,有符号字符值的范围是-128-127,无符号字符值的范围是0-255,而字符串的ASCII没有负值,若不转化为无符号数,在减法实现时出现错误。
例如:str的值为1,str2的值为255。
作为无符号数计算时ret=-254,结果为负值,正确。
作为有符号数计算时ret=-2,结果为正值,错误。
while循环中(ret=*(unsigned char *)str1 - *(unsigned char *)str2)&& *str1,最后的str1也可以换成str2,因为前面已经做了相减,无论哪个先为’\0’都会退出。
6. strstr
char *strstr(const char *haystack, const char *needle)
haystack – 要被检索的 C 字符串。
needle – 在 haystack 字符串内要搜索的小字符串。
作用:在字符串 haystack 中查找第一次出现字符串 needle 的位置,不包含终止符 ‘\0’。
6.1 strcstr源码
char * strstr(const char *str1, const char *str2)
{
char *cp = (char *)str1;
char *s1, *s2;
if (!*str2)
return((char *)str1);
while (*cp)
{
s1 = cp;
s2 = (char *)str2;
while (*s2 && !(*s1 - *s2))
s1++, s2++;
if (!*s2)
return(cp);
cp++;
}
return(NULL);
}
7. memcpy
memcpy 函数顾名思义就是 内存拷贝,实现 将一个 内存块 的内容复制到另一个 内存块这一功能。
void *memcpy(void *dest, const void *src, size_t n)
{
if(NULL == dest || NULL == src)
{
return NULL;
}
void *ret = dst;
char *d;
const char *s;
//内存不重叠的情况,从低地址开始复制
if (dest > (src + n)) || (dest < src))
{
d = dest;
s = src;
while (n--)
*d++ = *s++;
}
//内存重叠的情况,从高地址开始复制
else
{
d = (char *)(dest + n - 1); /* offset of pointer is from 0 */
s = (char *)(src + n -1);
while (n --)
*d-- = *s--;
}
return ret;
}
8. memmove
memmove() 用来复制内存内容,其原型为:
void * memmove(void *dest, const void *src, size_t num);
memmove() 与 memcpy() 类似都是用来复制 src 所指的内存内容前 num 个字节到 dest 所指的地址上。不同的是,memmove() 更为灵活,当src 和 dest 所指的内存区域重叠时,memmove() 仍然可以正确的处理,不过执行效率上会比使用 memcpy() 略慢些。
说明内存重叠时的情况:先将内容复制到类似缓冲区的地方,再用缓冲区中的内容覆盖 dest 指向的内存
void* memmove(void* dest, void* src, size_t num)
{
//dest落在了src的左边,从前往后拷贝
//dest落在了src的右边,同时没有超过那个重叠的边界的时候,从后往前拷贝
assert(dest != NULL);
assert(src != NULL);
void* ret = dest;
// void* 不能直接解引用,那么如何复制呢?
// 给了num个字节,也就是需要复制num个字节
// 那就转换成char*,一个一个字节的复制过去
if (dest < src)
//if (dest < src || dest > (char*)src + num)
{
//dest落在了src的左边,从前往后拷
while (num--)
{
*(char*)dest = *(char*)src;
//++(char*)dest;
//++(char*)src;
((char*)dest)++;
((char*)src)++;
}
}
else
{
// 从后往前拷
// 找到最后一个字节
while (num--)
{
*((char*)dest + num) = *((char*)src + num);
}
}
return ret;
}














 18
18











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









