







Storm 在集群上运行一个 Topology的时刻,主要通过以下3个实体来完成Topology的执行工作
1 Worker
2 Executor
3 Task

一个Worker 进程执行的是一个topology的子集,这里我们必须强调:不会存在一个worker 为多个topology服务,
一个worker进程会启动一个或则多个executor 线程来执行一个topology的compotent-》也就是Spout或者bolt,
一个topology就是由于集群中间的多台物理机上的Worker构成的
一个executor是一个被Worker进程启动的单独线程,每一个Executor都只会运行一个topology的一个component,
在默认的情况之下,一个spout,或则一个bolt都只会生成一个task,Executor线程里会在每次循环的时候顺序的去调用所有的task的实例子
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task
更加细化的来说:
一个storm topology运行起来之后, 会在supervisor 机器上启动一些进程来运行spout和bolt实例.
如果一个topology里面一共有一个spout, 一个bolt。 其中spout的parallelism是2, bolt的parallelism是4, 那么我们可以把这个topology的总工作量看成是6, 那么一共有6个task,那么/tasks/{topology-id}下面一共会有6个以task-id命名的文件,其中两个文件的内容是spout的id, 其它四个文件的内容是bolt的id。
task->node+port, 它其实就是从task-id到supervisor-id+port的映射, 也就是把这个task分配给某台机器的某个端口来做。
topology里面的组件(spout/bolt)都根据parallelism被分成多个task, 而这些task被分配给supervisor的多个worker来执行。
task都会跟一个componment-id关联, componment是spout和bolt的一个统称.
对于每一个component在部署的时候都会指定使用的数量, 在storm-user中有一个讨论说明了这个问题:
里面的大意是说, 通过设置parallelism来指定执行spout/bolt的线程数量. 而在配置中还有另外一个地方(backtype.storm.Config.setNumWorkers(int))来指定一个storm集群中执行topolgy的进程数量, 所有的线程将在这些指定的worker进程中运行. 比如说一个topology中要启动300个线程来运行spout/bolt, 而指定的worker进程数量是60个, 那么storm将会给每个worker分配5个线程来跑spout/bolt, 如果要对一个topology进行调优, 可以调整worker数量和spout/bolt的parallelism数量(调整参数之后要记得重新部署topology. 后续会为该操作提供一个swapping的功能来减小重新部署的时间).
对于worker和task之间的比例, nathan也给出了参考, 即1个worker包含10~15个左右, 当然这个参考, 实际情况还是要根据配置和测试情况
3: work 进程内部消息传递处理和数据结构分析
本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义。试图从代码实现的角度来回答,如果是从头开始实现worker的话,该如何来定义消息接口,如何实现各自接口上的消息处理。
3.1 Topology 到worker的映射关系
Topology 由Spout,Bolt组成,其中的逻辑关系大体如下
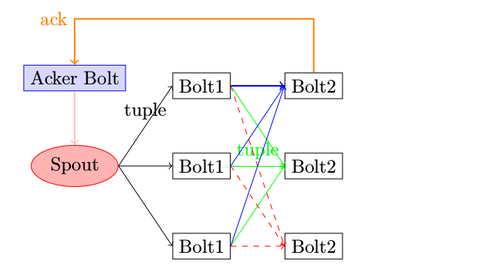
请注意 Acker的行为,是在tuple,以及tuple所产生的其他tuple被确认消费掉以后,才会
有你的ACK行为
无论是Spout或Bolt的处理逻辑都需要在进程或线程内执行,那么它们与进程及线程间的映射关系又是如何呢。有关这个问题,Understanding the Parallelism of a Storm Topology 一文作了很好的总结,现重复一下其要点。
-
1 worker是进程,executor对应于线程,spout或bolt是一个个的task
-
2 同一个worker只会执行同一个topology相关的task
-
3 在同一个executor中可以执行多个同类型的task, 即在同一个executor中,要么全部是bolt类的task,要么全部是 spout类的task
-
4 运行的时候,spout和bolt需要被包装成一个又一个task
期间的三个组件的关系为:
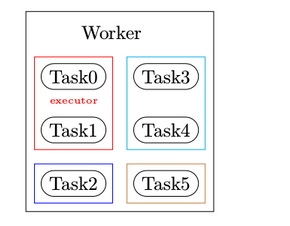
小结一下,Worker=Process, Executor=Thread, Task=Spout or Bolt.
每一个executor使用的是actor pattern,high level的处理逻辑如下图所示
















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









