



 本文详细介绍了正则表达式的基本概念和高级用法,包括元字符、位置锚定、分组及逻辑或等,并通过实例解析了如何运用正则进行匹配和过滤。同时,讲解了Sed编辑器的工作原理和常用操作,如删除、打印、替换等,展示了Sed在文本处理中的应用。
本文详细介绍了正则表达式的基本概念和高级用法,包括元字符、位置锚定、分组及逻辑或等,并通过实例解析了如何运用正则进行匹配和过滤。同时,讲解了Sed编辑器的工作原理和常用操作,如删除、打印、替换等,展示了Sed在文本处理中的应用。
正则表达式:
对文本内容进行过滤,查找,匹配,正则可以匹配完整的大小写
元字符:. 表示任意单个字符
转义符: \
() 分组 \(\)
[]匹配范围之内的任意单个字符,既能匹配数字,也能匹配字符
[^az]: 取反,显示不包含的内容
通配符:
匹配的是文件名,而且不能精确匹配大小写
基本正则表达式:
表示次数:
*:匹配前面的字符任意数,包括0次,尽可能长的匹配

.*:匹配前面的字符任意数,但是不包括0次,也就是匹配所有
\?:匹配前面的字符出现0次,或者一次,有且仅有一次
\+:匹配前面出现的字符,至少出现一次,也就是>=1
\{n\}:匹配前面出现的字符等于几次
\{m,n\}:匹配前面的字符,最少是m次,最多数n次
\{,n\}:匹配前面的字符最多n次,没有也算
\{n,\}:匹配前面的字符最少n次,只要连续出现n次,后面的都算
习题:
用正则表达式的方式把ip地址,子网掩码,广播地址,表达出来


这就是你在网站上输的账号密码不对:少输了数字,提示没有大写字母开头
位置锚定:
^:行首锚定,以什么开头
$:行尾锚定,以什么结尾
^root$:匹配行模式,单独一行只有root
^$:空白行
^[[:space:]]*$ 空白行
练习:
过滤非以#为开头的过滤出来

\<或者\b 词首锚定 用于匹配单词模式的左侧
\>或者\b 词尾锚定 用于匹配单词模式的右侧
这两个从左往右全部都算,所有一起都包含,所有算匹配到
只匹配右侧的单词,右侧的单词不匹配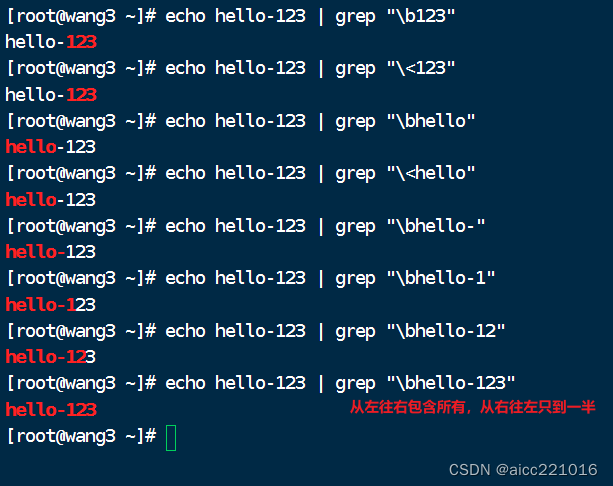
\broot\b :匹配整这个单词
\<root\> :匹配整个单词
分组以及逻辑或
分组:()

必须要连续出现,才能匹配的到



逻辑或:\|
grep -E 扩展正则表达式
egrep
扩展正则表达式,这两个都行 就不用打\了
练习:
用正则表达式把这三个号码展示出来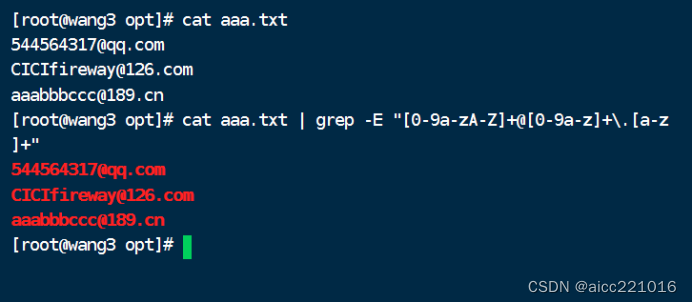
练习2
练习3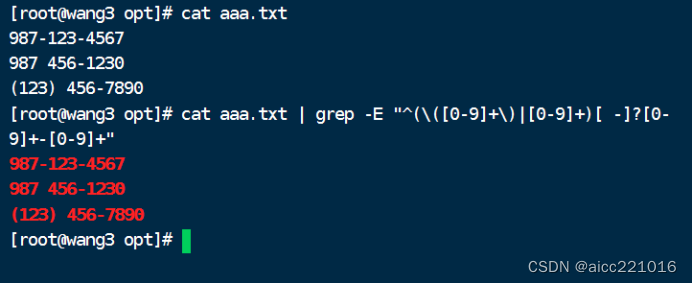
正则表达式核心:
grep -E 扩展正则表达式
*:匹配前面的字符任意次,包括0次,尽可能长的匹配
.*: 匹配前面的字符任意次,但是不包括0次。也就是匹配所有。
?: 匹配前面的字符出现0次,或者1次,有且只有一次。
+:匹配前面出现的字符,至少出现一次,也就是>=1,
{n }:匹配前面出现的字符等于几次。
{m,n }:匹配前面出现的字符最少M次,最多是n次
{ ,n } : 匹配前面的字符最多N次,没有也算。
{ n, }: 匹配前面的字符最少N次,只要连续出现N次,后面的都算。
|:表示逻辑或
grep -E
egrep
扩展正则表达式这两个都可以
位置锚定:
^: 行首锚定,以什么为开头
$:行尾锚定,以什么为结尾
^root$:匹配行,单独的一行只有root
^$:空白行。
^[[:space:]]*$ 空白行
\ < 或者 \b 词首锚定 用于匹配单词模式的左侧
从左往右全部都算。所有一起都包含,所有算匹配到。
\ > 或者 \b 词尾锚定 用于匹配单词模式的右侧
只匹配右侧的单词,左侧的单词不匹配。
\b
\b
\broot\b : 匹配整这个单词
\ < root \ >
分组以及逻辑或
():分组
\ |:逻辑或
Sed编辑器:
文本三剑客:
grep 过滤文本内容
Sed 行编辑器
Sed也是按行进行处理
Sed是一种流编辑器
每一次处理内容,只有确认才会生效,不确认的,只是把模式空间的临时数据展示给用户没然后删除,按照文本的行,一行一行向下处理,直到文件的最后一行
默认情况下:sed都是在模式空间执行,因此源文件不会发生变化,要变化怎么办?
Sed的格式:
Sed -e “操作” 文件1 文件2
Sed -e “操作1:;操作2”文件
-e 指定的命令来处理输入的文本文件,只有一个操作,-e可以省略。多个指令才会用-e
-f 用特定的脚本文件来处理输入的文件
-i 立即生效
-n 仅显示script处理后的结果
Sed -i 立刻生效 慎用
Sed ‘ ‘ 打印文本内容



Sed操作符
P 打印
Sed -e ‘p’ xxx.txt
sed自己还有一个默认输出,再加上p打印,就有两个
-n就是禁止了默认输出
Sed -n ‘2p’ xxx.txt
输出指定行内容,只有第二行,其他的都没有
既要行号也要内容
打印第一行和最后一行

打印第一行和第二行

打印第一行到第三行

= 号,只展示行号
Sed -n ‘$p’ test.txt
打印最后一行

Sed -n ‘=’ test.txt 只打印行号

d:删除行
对奇偶行打印
n在p的前面,跳过当前一行,打印下一行
p在前面,打印当前一行,跳下一行继续打印
文本内容过滤--sed
格式要栓斜杠括起来
例
过滤所有包含o的行
练习:
使用正则表达式过滤 etc /passwd里面的root

打印所有以bash为结尾的行

例题
从第四行开始,一直打印到第一个以bash为结尾的所在行
Sed使用扩展正则表达式:
Sed -r 使用扩展正则 {n} {n,} {n,m} {,m}
练习:包含两个99:的所在行
打印所有要么是以root为开头,要么以bash为结尾的行,打印
Sed删除文件:
面试题:现在有一个文件,文件名我想保留,但是原有的内容我要删除,不能用vim进去删
第一种方法:放入黑洞文件
第二种方法:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









