







 本文详细探讨了Oracle数据库中字符串处理的各种技巧和优化方法,包括常用操作符和函数的使用,如字符串连接符"||",instr和substr函数,以及正则表达式的应用。通过实例展示了如何计算字符出现次数、按符号分割字符串、提取特定分隔的子串、分解IP地址和查询特定格式的数据。还介绍了如何使用listagg函数进行列转行操作。这些技巧对于提高Oracle查询效率和处理字符串数据非常有用。
本文详细探讨了Oracle数据库中字符串处理的各种技巧和优化方法,包括常用操作符和函数的使用,如字符串连接符"||",instr和substr函数,以及正则表达式的应用。通过实例展示了如何计算字符出现次数、按符号分割字符串、提取特定分隔的子串、分解IP地址和查询特定格式的数据。还介绍了如何使用listagg函数进行列转行操作。这些技巧对于提高Oracle查询效率和处理字符串数据非常有用。
前言
前两篇blog分别介绍了Oracle中的单表查询(Oracle查询技巧与优化(一) 单表查询与排序)与多表查询(Oracle查询技巧与优化(二) 多表查询)的相关技巧与优化,那么接下来本篇blog就具体研究一下Oracle查询中使用频率很高的一种数据类型——“字符串”的相关操作与注意点。
常用操作符与函数
如题,先简单回顾一下我个人认为在Oracle的查询或存储过程中使用频率较高的操作符与函数,作为基础知识回顾,首先是最常用的字符串连接符“||”,即Oracle中的字符串拼接符号,例如:
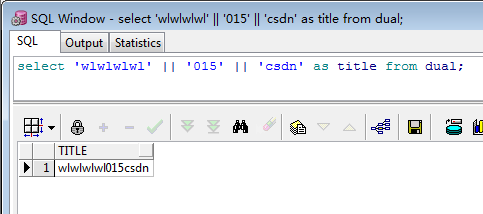
select 'wlwlwlwl' || '015' || 'csdn' as title from dual;运行结果如下:
再看几个简单的比较常用的字符串函数,首先是instr与substr,这两个函数经常结合使用,下面分别看一下,先来看看相对简单一些的substr函数,它的语法格式如下:SUBSTR(cExpression,nStartPosition [,nCharactersReturned]),通俗的讲,第1个参数是源字符串,第2个参数是开始截取的位置,第3个参数是截取长度,例如:
select substr('abcdefg',0,1) as newstr from dual; // 返回a
select substr('abcdefg',1,1) as newstr from dual; // 返回a,0和1都代表第1个字符
select substr('abcdefg',2,4) as newstr from dual; // 返回bcde,注意包含位置字符
select substr('abcdefg',-3,2) as newstr from dual; // 返回ef,负数表示从后往前数位置,其余不变substr函数实在不需要做过多说明,接下来看看instr函数,它的作用是“在一个字符串中查找指定的字符,返回被查找到的指定的字符的位置”,有点类似于java中String的indexOf方法:
select instr('abcd','a') from dual; // 返回1
select instr('abcd','b') from dual; // 返回2
select instr('abcd','c') from dual; // 返回3
select instr('abcd','e') from dual; // 返回0如上所示,如果找不到指定的子串,则返回0,以上是instr函数最简单的用法,接下来具体看一下instr函数完整的语法格式:instr(string1,string2[,start_position[,nth_appearence]]),可以看到它最多支持4个参数,下面分别解释一下每个参数的意思:
- string1,即源字符串。
- string2,目标字符串,即要在string1中查找的字符串。
- start_position,从string1开始查找的位置。可选,默认为1,正数时,从左到右检索,负数时,从右到左检索。
- nth_appearence,查找第几次出现string2。可选,默认为1,不能为负。
如上所示,之所以instr函数很强大往往是依赖第4个参数的作用,在某些场合往往能起到关键作用,下面看一个我项目中的例子,首先学生表有一个字段记录了每个学生的体育考试选考科目,每人选5门待考科目,每个科目都有一个代码,在学生表存储的数据格式是“每门科目代码加逗号拼接的字符串”,形如:
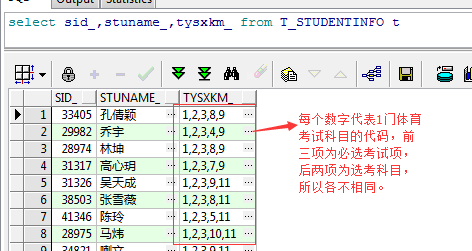
如上图,每一个选考项在字典表均可对应:
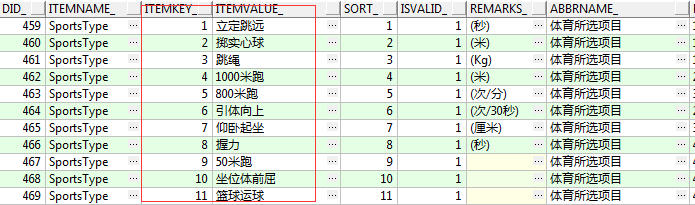
现在假设我们有这样一个需求,把每个学生的每一门体育选考项目的代码和名称分别列出来,达到以下的效果:
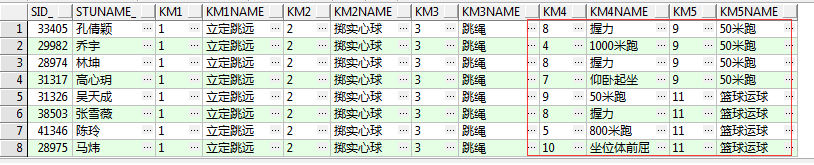
如上图所示,该如何实现呢?首先思路很明确,把学生表记录的选考科目代码字符串进行拆分,然后再一一列举,那么此时需要注意的一个问题是代码的长度不确定,科目代码可能是1位数字,例如:1,2,3,8,9,但也可能存在两位数字,例如:1,2,3,11,12,那么直接用substr按位截取肯定是行不通的,此时我们应该想办法如何按符号截取,每个考试科目代码中间都是用逗号隔开的,如果能找到相邻两个逗号之间的数字,那么问题就迎刃而解了,这里需要用到的就是前面说的instr和substr相结合:
select t1.sid_,
t1.stuname_,
t1.km1,
t2.itemvalue_ km1name,
t1.km2,
t3.itemvalue_ km2name,
t1.km3,
t4.itemvalue_ km3name,
t1.km4,
t5.itemvalue_ km4name,
t1.km5,
t6.itemvalue_ km5name
from (select sid_,
stuname_,
substr(tysxkm_, 0, instr(tysxkm_, ',', 1, 1) - 1) as km1,
substr(tysxkm_,
instr(tysxkm_, ',', 1, 1) + 1,
instr(tysxkm_, ',', 1, 2) - instr(tysxkm_, ',', 1, 1) - 1) as km2,
substr(tysxkm_,
instr(tysxkm_, ',', 1, 2) + 1</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









