






目录
1.redis介绍
1.1redis简介
redis 是一个高性能的 key-value 数据库。 redis 的出现,很大程度补偿了
memcached 这类 keyvalue 存储的不足,在部分场合可以对关系数据库起到很
好的补充作用。它提供了 Python,Ruby,Erlang,PHP 客户端,使用很方便。
Redis 的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上
(这称为“半持久化模式”);也可以把每一次数据变化都写入到一个 append
only file(aof)里面(这称为“全持久化模式”)。redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
1.2key-value简介
key-value:key-value分布式存储系统查询速度快、存放数据量大、支持高并发,非常适合通过主键进行查询,但不能进行复杂的条件查询。
key value 根据关键字取值(key是关键字,value是值)
特点:
具有极高的并发读写性能
Key-value数据库是一种以键值对存储数据的一种数据库,类似Java中的map。可以将整个数据库理解为一个大的map,每个键都会对应一个唯一的值
1.3 redis有哪些数据结构?
redis提供五种数据类型:
string 字符串(可以为整形、浮点型和字符串,统称为元素)
list 列表(实现队列,元素不唯一,先入先出原则)
set 集合(各不相同的元素)
hash hash散列值(hash的key必须是唯一的)
sort set 有序集合
1.4 redis相比memcached有哪些优势?
1、数据存储介质: Memchache缓存的数据都是存放在内存中,一旦内存失效,数据就丢失,无法恢复;Redis缓存的数据存放在内存和硬盘中,能够达到持久化存储,Redis能够利用快照和AOF把数据存放到硬盘中,当内存失效,也可以从磁盘中抽取出来,调入内存中,当物理内存使用完毕后,也可以自动的持久化的磁盘中。
2、数据存储方式:Redis与Memchache都是以键值对的方式存储,而Redis对于值 使用比较丰富,支持Set,Hash,List,Zet(有序集合)等数据结构的存储,Memchache只支持字符串,不过Memchache也可以缓存图片、视频等非结构化数据。
3、从架构层次:Redis支持Master-Slave(主从)模式的应用,应用在单核上, Memchache支持分布式,应用在多核上
4、存储数据大小:对于Redis单个Value存储的数据最大为1G,而Memchache存储的最大为1MB,而存储的Value数据值大于100K时,性能会更好
5、Redis只支持单核,而Memchache支持多核。
6、Redis直接自己构建了VM(虚拟内存) 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
1.5redis的虚拟内存(vm)
Redis的VM(虚拟内存)机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。Redis提高数据库容量的办法有两种:一种是可以将数据分割到多个Redis Server上;另一种是使用虚拟内存把那些不经常访问的数据交换到磁盘上。需要特别注意的是Redis并没有使用OS提供的Swap,而是自己实现。
Redis为了保证查找的速度,只会将value交换出去,而在内存中保留所有的Key。所以它非常适合Key很小,Value很大的存储结构。如果Key很大,value很小,那么vm可能还是无法满足需求。
1.6redis的优点
速度快:因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
支持丰富数据类型:支持string,list,set,sorted set,hash
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
1.7适用场景
会话缓存(Session Cache)
全页缓存(FPC)
队列Reids
排行榜/计数器Redis
发布/订阅
1.8使用场景
1) 配合关系型数据库做高速缓存 ,缓存高频次访问的数据,降低数据库io, 分布式架构,做session共享
2) 可以持久化特定数据,利用zset类型可以存储排行榜,利用list的自然时间排序存储最新n个数据
2.redis安装与启用
tar zxf redis-6.2.4.tar.gz
ls
cd redis-6.2.4/
make
make install
ls
cd utils/
vim install_server.sh
注释指定的内容
./install_server.sh

cd /etc/redis
vim 6379.conf
##bind 0.0.0.0(修改端口使其他主机可以访问)
ss -antlp
/etc/init.d/redis_6379 restart 重启redis



3.redis主从复制
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。下图为级联结构。

全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。
增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
master和slave的/etc/redis/6379.conf配置文件配置大体一致,但需要在slave端,加入slaveof master的ip 6379
启用redis:
/etc/init.d/redis_6379 start
查看信息:info
在master端写入:set name westos
在slave端可查看:get name4.高可用(redis sentinel哨兵模式)
Redis Sentinel 为Redis提供了高可用的实现。通俗来说就是你可以部署一套无需人为干预即可防灾的Redis环境。RS同时为客户端提供了其他诸如监控,通知的功能。但它也有一个问题,就是不能动态扩充。
从全局来说RS的功能如下:
监控: RS时刻监控主从是否在正常工作。
通知: 当某个Redis实例出现问题,RS可以通知系统管理员或者通过API通知其他程序。
自动切换: 如果一个主实例失效,RS会启动一个失效转移(从升级为主)的进程,其他的从节点将重新跟随新的主节点。连接到RedisServer的会被通知切换到新的地址。
配置提供者: RS充当了客户端服务自动发现的提供者:连接到Sentinal的客户端,Sentianl会响应最新的主节点地址给客户端,并且当发生转移的时候会发送通知。
cd redis-5.0.9
cp sentinel.conf /etc/redis/
vim /etc/redis/sentinel.conf
修改以下三行内容:
17 protected-mode no (关闭保护模式)
121 sentinel monitor mymaster 172.25.254.1 6379 2
(指定要监控的master,mymaster是定义的master名字,
quorum为法定票数2,此处指的是sentinel的数,
只有指定的sentinel同意时才认为sentinel做的决策是有效的,
一般大于sentinel数量的半数。
可以有多个master,一组sentinel集群可以监控N个主从复制架构。)
146 sentinel down-after-milliseconds mymaster 10000
(至少多长时间连不上才认为master离线了。单位为ms,即连接超时时长(这里我设置为10秒))
scp /etc/redis/sentinel.conf root@vm2:/etc/redis/
scp /etc/redis/sentinel.conf root@vm3:/etc/redis/
在三个redis上分别开启监控:redis-sentinel /etc/redis/sentinel.conf
再开启一个shell连接server1查看信息:
redis-cli
127.0.0.1:6379> info(此时可以看到vm1是master)手动down掉master的redis:
redis-cli
127.0.0.1:6379> SHUTDOWN等待10s后,在监控页面可以看到:
vm1宕掉,而vm3变成新的master的信息。重新开启1的redis,手动成为server3的slave:
redis-cli
127.0.0.1:6379> SLAVEOF 172.25.254.3 63795.redis集群
5.1redis-cluster设计
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
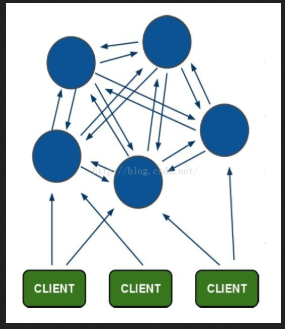
5.2结构特点
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
5.3Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉
假设集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
5.4安装与启用

vim redis.conf 编辑配置文件
///
port 7001
cluster-enabled yes 开启集群
cluster-config-file nodes.conf 集群配置文件
cluster-node-timeout 5000 ##节点超时
appendonly yes 开启AOF模式
daemonize yes 用守护线程的方式启动
复制完文件之后,将7002-7006的文件作改动,然后启用(redis-server redis.conf)
![]()
搭建集群:

向集群中加入节点:
将7007加入集群:
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
将7008作为7006的slave加入集群:
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7001 --cluster-slave --cluster-master-id d0ba4fb6b9e627f80341c3737c2e1319cddd14dd
分配hash槽:
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 596a60abeef8d85d96a70780e85b0f5adbd34f9f --cluster-to d0ba4fb6b9e627f80341c3737c2e1319cddd14dd --cluster-slots 1000 --cluster-yes
6.lamp架构+redis+mysql
6.1实现简单的redis缓存mysql中的数据
首先在三台主机中关闭以前设置的环境变量
vim .bash_profile
source .bash_profile
vm1(lamp架构):
cd /usr/local
ps ax
/etc/init.d/redis_6379 stop
systemctl stop nginx.service
systemctl stop php-fpm.service
killall5
yum install httpd php php-mysql -y
cd /var/www/html
得到test.php文件
php -m | grep mysql
在250主机中得到rhel7目录,并下载
php-pecl-redis-2.2.8-1.el7.x86_64.rpm
php-pecl-igbinary-1.2.1-1.el7.x86_64.rpm
php -m | grep redis
systemctl start httpd
vm2(redis):
必须是master
vm3(mysql):
yum install mariadb-server.x86_64 -y
vim /etc/my.cnf
systemctl start mariadb
将test.sql文件导入数据库中
grant all on test.* to redis@'%' identified by 'westos'
test.php中的内容

/etc/my.cnf中的内容

6.2配置 gearman 实现数据同步
Gearman 是一个支持分布式的任务分发框架:
Gearman Job Server: Gearman 核心程序,需要编译安装并以守护进程形式运行在后台。
Gearman Client:可以理解为任务的请求者。
Gearman Worker:任务的真正执行者,一般需要自己编写具体逻辑并通过守护进程方式
运行,Gearman Worker 接收到 Gearman Client 传递的任务内容后,会按顺序处理。
大致流程:下面要编写的 mysql 触发器,就相当于 Gearman 的客户端。修改表,插入表就相当于直接下发任务。然后通过 lib_mysqludf_json UDF 库函数将关系数据映射为 JSON 格式,然后
在通过 gearman-mysql-udf 插件将任务加入到 Gearman 的任务队列中,最后通过
redis_worker.php,也就是 Gearman 的 worker 端来完成 redis 数据库的更新。
在mysql上:





上图所示的软家有依赖性,需要安装


指定 gearman 的服务信息


在lamp上:


先vim work.php 然后将worker打入后台

验证结果:

















 89
89











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









