







前段时间,不知道为什么Kimi突然在各大平台爆火,dy b站都能看到它的身影。抱着试试看的态度,我也去体验了一下Kimi的效果,我只能说 一言难尽。。。。。。国产模型我还是回去用通义千问吧哈哈哈哈哈。圆规正转,今天想聊的是Kimi的“护城河”--大模型如何来解决长上下文输入问题。
前言
看了Kimi的广告,我发现它主打的就是“长”,不管是输入文件还是什么都能给你支持。直到今天,kimi能够支持200万token的输入,并且支持处理500个文件。
我只能说200万汉字大概有6000k的tokens,如果模型处理文本真的能有这么大,那当之无愧的国产最强大模型。 但是 Kimi家的模型底层用的还是moonshot大模型,它所开放的接口也就128k。
截止目前数据
| 模型 | 可处理Tokens | 推出时间 |
| moonshot- V1 | 128k | 2024-3 |
| longformer | 4096 | 2023-3 |
| ChatGPT-4 | 128k | 2024 |
| Qwen2-7B | 128K | 2024-7 |
所以说能支持200万字的是kimi助手 不是大模型
接下来引入我们的正题,大模型解决上下文问题为什么难解决?
为什么难以增长token?
原因1:Attention
众所周知,大模型的底层架构是Transformer,而Transformer的关键技术就是Attention机制。Self- Attention处理n个token的复杂度为。所以序列长度直接影响了Attention的计算复杂度。
参考:
原因2:位置编码
目前位置编码(如ROPE)理论上来说其实可以处理无限长的token的,但是实践上来看还是会有些问题,会导致模型的训练效果不佳。
想了解位置编码的可以去苏老师的博客仔细了解。(是一位非常非常厉害的老师)
参考:
知道原因之后就可以来专门解决问题了
解决方法1:稀疏Transformer
左图:注意力矩阵
右图:每个token和不同token的关联性
Full Self Attention
最普通的Transformer 和每个元素都进行Attention计算。
如:“我爱中国美食”中
“我”会与所有token进行计算得出结果
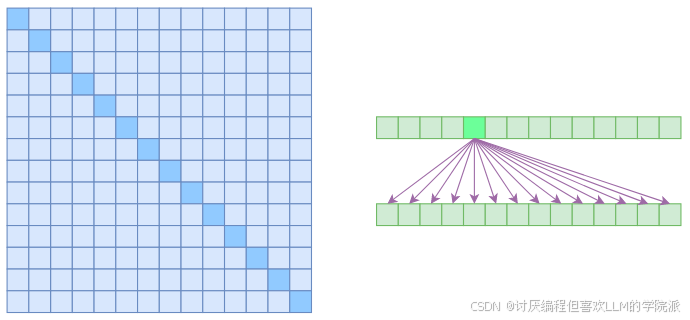
时间空间复杂度均为
Atrous Self Attention
要求每个token之间的注意力是不连续的,它的注意力只与距离为的nk元素的值相关。
如:“我爱你的兄弟们” k=2
“我”会与“你”、“兄”、“们”这三个token做计算
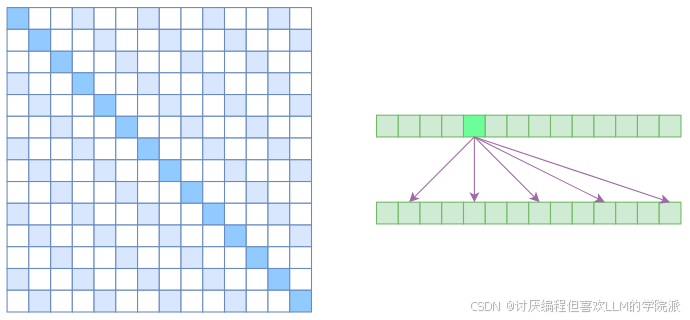
时间空间复杂度都变成了,也就是说能直接降低到原来的
。
Local Self Attention
要求每个token只和自己前后距离为k的token做计算
如:“我爱你的兄弟们”k=2
“的”会与“爱”、“你”、“兄”、‘弟’做计算
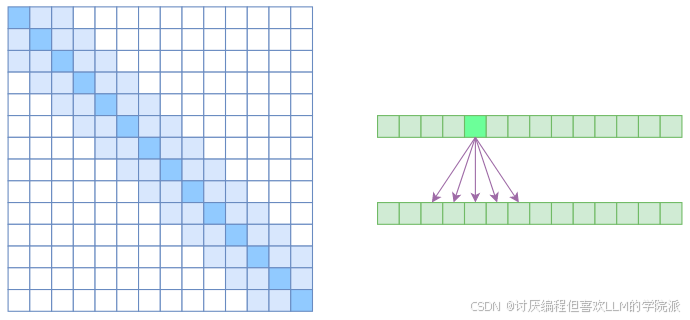
时间空间复杂度都为了
优点:变成线性复杂度了
缺点:牺牲了长距离关联性
Stride Sparse Self Attention
将上面两种方式进行了融合,结合了各自的优点。
每个token与距离为m的和距离为nk的都进行计算
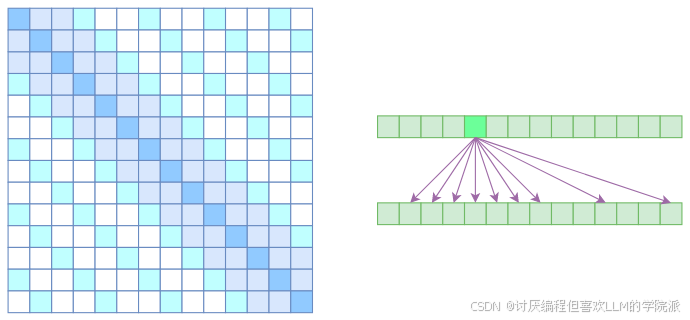
时间空间复杂度:
使得具有局部紧密相关和远程稀疏相关的特性,由于很长距离的关联任务不多,因此效果不错
Fix Sparse Self Attention
对token进行分组后在组内做全注意力计算+对特定位置的元素固定做注意力计算
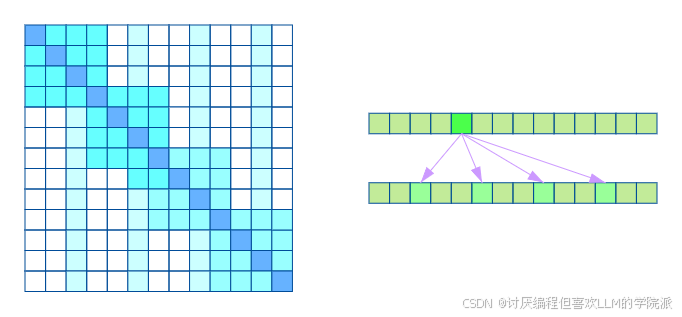
同样保证了局部紧密相关和远程稀疏相关特性。
Sparse Softmax
论文:
From Softmax to Sparsemax: A Sparse Model of Attention and Multi-Label Classification
Sparse Sequence-to-Sequence Models
主要对softmax进行了修改,只保留最大的k个类别 剩下的都置为0
公式如下
稀疏化的关键作用在于缓解 Softmax 过度学习问题。假设目标类别的分数最大(即 ),则原始交叉熵公式可表示为:
进一步可得不等式:
设当前交叉熵值为 ,当
=
时,解得:
为了使损失降至 0.69,最大的 logit 与最小的 logit 之间的差距必须超过 log(n-1)。当 n 较大时,这对分类问题来说是一个不必要的过大间隔。实际上,我们只需要目标类的 logit 略高于非目标类即可,而不必达到 log(n-1) 这么大的差距,因此常规的交叉熵容易因过度学习而导致过拟合。
一个简单的伪代码实现:有兴趣的可以去git上搜一搜
import torch
def sparse_softmax(preds, k):
#稀疏化 Softmax 函数:仅保留每行中最大的 k 个元素用于 Softmax 计算,其余置零。
# 获取每行的前 k 个最大值及其索引
vals, indices = torch.topk(preds, k, dim=1)
sparse= torch.zeros_like(preds)
# 将前 k 个最大值填充到对应位置
sparse.scatter_(1, indices, vals)
exp_sparse = torch.exp(sparse)
sum_exp_sparse = exp_sparse.sum(dim=1, keepdim=True)
output = exp_sparse / (sum_exp_sparse + 1e-10)
return output解决方法2:位置编码
去看这篇文章 ROPE
解决方法3:Multi_QueryAttention
pass
解决方法4:MOE技术
pass
本质上来说解决问题的方法还得是Linear Attention,因为n方的代价太大了,得有更好的解决方法来处理transformer


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









