






harr 特征用于人脸检测
就是把haar特征(比如边界特性,是一个矩形)放到人脸区域,白色区域的像素和减去黑色区域的像素和之差就是特征值,(积分图是为了更快速的计算出特征值)如果这个矩形不在人脸区域,其特征值肯定不一样,对于人脸检测这个值越不一样越好,这样更能区分人脸和非人脸。
但是如何增加区分度,就是把不同的矩形特征组合在一起(其实这个组合就是分类器),如何选择更好的矩阵特征组合,,就是adaboost算法要干的事情
Boosting算法
Boosting算法涉及到两个重要的概念就是弱学习和强学习,所谓的弱学习,就是指一个学习算法对一组概念的识别率只比随机识别好一点,所谓强学习,就是指一个学习算法对一组概率的识别率很高。现在我们知道所谓的弱分类器和强分类器就是弱学习算法和强学习算法。弱学习算法是比较容易获得的,获得过程需要数量巨大的假设集合,这个假设集合是基于某些简单规则的组合和对样本集的性能评估而生成的,而强学习算法是不容易获得的,然而,Kearns 和Valiant 两头牛提出了弱学习和强学习等价的问题 【6】 并证明了只要有足够的数据,弱学习算法就能通过集成的方式生成任意高精度的强学习方法。这一证明使得Boosting有了可靠的理论基础,Boosting算法成为了一个提升分类器精确性的一般性方法。
但是
Boosting算法还是存在着几个主要的问题,其一Boosting算法需要预先知道弱学习算法学习正确率的下限即弱分类器的误差,其二Boosting算法可能导致后来的训练过分集中于少数特别难区分的样本,导致不稳定。针对Boosting的若干缺陷,Freund和Schapire牛于1996年前后提出了一个实际可用的自适应Boosting算法AdaBoost【9】,
AdaBoost目前已发展出了大概四种形式的算法,Discrete AdaBoost(AdaBoost.M1)、Real AdaBoost、LogitBoost、gentle AdaBoost。
弱分类器
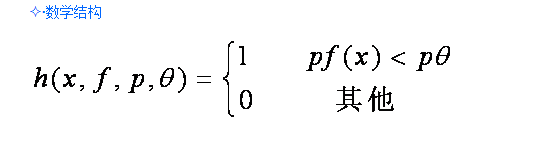
一个弱分类器由子窗口图像x,一个特征f,指示不等号方向的p和阈值组成。P的作用是控制不等式的方向,使得不等式都是<号,形式方便。
假设我们使用三个Haar-like特征f1,f2,f3来判断输入数据是否为人脸,可以建立如下决策树:

一个弱分类器就是一个基本和上图类似的决策树,最基本的弱分类器只包含一个Haar-like特征,也就是它的决策树只有一层,被称为树桩(stump)。
最重要的就是如何决定每个结点判断的输出,要比较输入图片的特征值和弱分类器中特征,一定需要一个阈值,当输入图片的特征值大于该阈值时才判定其为人脸。训练最优弱分类器的过程实际上就是在寻找合适的分类器阈值,使该分类器对所有样本的判读误差最低。
具体操作过程如下:
1)对于每个特征 f,计算所有训练样本的特征值,并将其排序。
扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
全部人脸样本的权重的和t1;
全部非人脸样本的权重的和t0;
在此元素之前的人脸样本的权重的和s1;
在此元素之前的非人脸样本的权重的和s0;
2)最终求得每个元素的分类误差
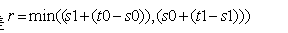
在表中寻找r值最小的元素,则该元素作为最优阈值。有了该阈值,我们的第一个最优弱分类器就诞生了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









