







就在昨天,2月19号 ,YOLOv12算法低调发布,YOLOv9,10,11都还没来得及看!!!
整体汇总一下 yolov12的信息:
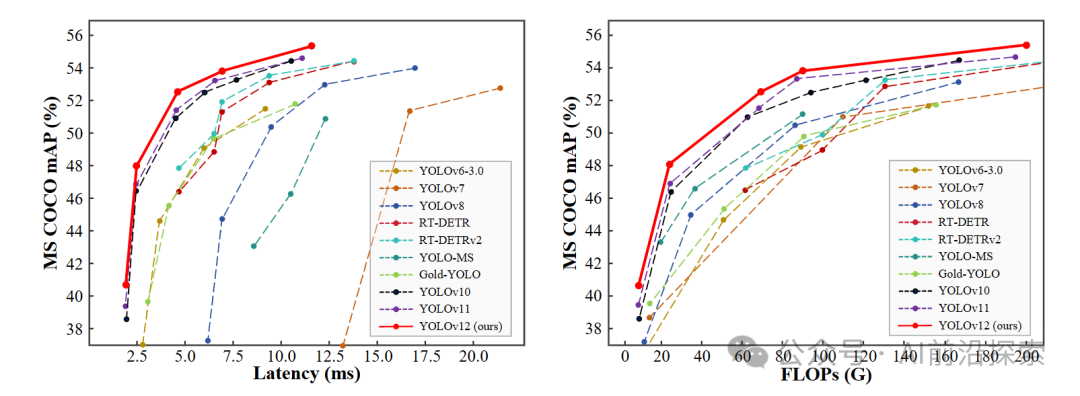
在计算机视觉领域,实时目标检测(如自动驾驶、监控系统)一直追求「快且准」。传统方法依赖CNN,但最近几年,基于注意力机制的Transformer模型凭借强大的上下文建模能力异军突起。然而,Transformer的二次计算复杂度和内存访问瓶颈让它难以在实时场景中落地。今天,一个突破性研究——YOLOv12,它首次让注意力机制在实时目标检测中媲美甚至超越CNN!
一、为什么我们需要YOLOv12?
现有的实时检测框架(如YOLOv10、YOLOv11)虽然优秀,但仍受限于以下问题:
-
CNN的局限性:CNN通过局部卷积捕捉特征,但难以全局关联;
-
Transformer的瓶颈:注意力机制的计算复杂度高(O(L²)),且内存访问效率低;
-
平衡难题:如何在保证速度的同时提升精度?
YOLOv12的目标是打破这一僵局——用注意力机制实现更快的推理速度和更高的检测精度。
二、YOLOv12的三大核
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











