










 CDC是一种捕获数据库增量数据的技术,常用于数据备份、分发和数仓集成。常见的CDC方法包括时间戳、快照、触发器和日志。实时CDC工具如Canal、Maxwell、Debezium和FlinkCDC利用数据库日志实现数据一致性。离线数据集成工具有Sqoop和DataX。文章还讨论了MySQL的binlog模式及其在数据一致性中的作用。
CDC是一种捕获数据库增量数据的技术,常用于数据备份、分发和数仓集成。常见的CDC方法包括时间戳、快照、触发器和日志。实时CDC工具如Canal、Maxwell、Debezium和FlinkCDC利用数据库日志实现数据一致性。离线数据集成工具有Sqoop和DataX。文章还讨论了MySQL的binlog模式及其在数据一致性中的作用。
1、简介
CDC全称是Change Data Capture,是一种捕获增量数据的技术统称,目前主要应用在捕获数据库数据变更的技术。其中数据库变更包括DDL,DML,DCL等语句触发的变更。在数据备份容灾、数据分发、面向数仓的数据集成等场景中广泛应用。在增量数据识别中,增量捕获能否实现更多依赖于源端系统。
使用场景:企业信息化建设中,有一个板块是企业应用集成,根据集成深度的不同,可以分为界面集成、数据集成、控制集成、业务流程集成。其中界面集成是指统一入口,使分散的系统看起来产生整体的感觉,使最小化代价实现一体化操作的方法。控制集成和业务流程集成,是应用逻辑层的集成,通过通信的方式,调用其他系统方法或流程,来实现企业内外部的信息资产联动。
数据集成:其中数据集成是应用系统通过中间件、API调用等方式进行数据交互,当下提到的数据集成,更多的是面向分析场景,通过数据集成实现企业内外部数据的汇聚。
在面向分析场景中,出于网络压力、对源端系统的压力、以及效率等,重点考虑做增量数据的捕获,这样仅识别并获得最近变化的数据,更方便后续得ETL操作。
首先我们先对增量数据进行定义:有变化的数据行都是增量数据,如新插入的数据、发生修改的数据、被删除的数据。这些数据在数据集成的时候,都需要被准确识别和还原,这样才能保证OLAP侧和OLTP侧的数据一致性。
2、CDC常见方法分类
常见的增量数据捕获有基于时间戳、快照、触发器和日志四种。分别如下:
时间戳方法:
需要源端数据库中有相应的时间戳字段,并且这个字段在业务上代表更新时间,(某些情况下代表数据写入变更等操作时间)。
快照方法:
一般是数据库自带的机制,如关系型数据库的物化视图技术,也可以自己实现相关逻辑,比如每天或定时某些时刻进行数据的备份等操作,但会比较复杂。
触发器方法:
是传统关系型数据库自带的机制,触发器会在对表执行相关SQL语句如insert、delete、update的情况下触发,并执行一定的业务逻辑,将变化的数据写到另外一张表中,用于增量数据捕获。通常情况,DBA或数据开发管理人员,会自己编写或维护一套相关的触发器。
日志方法:
是基于日志消费的模式,源端数据库将库表变更以日志的方式记录到外存中,数据集成通过消费、解析日志进行增量数据捕获。如MYSQL的binlog等。
| 特性 | 时间戳方法 | 快照方法 | 触发器方法 | 日志方法 |
| DBA执行 | 不是 | 不是 | 是 | 是 |
| 实时 | 不是 | 不是 | 是 | 是 |
| 监听删除 | 不是 | 是 | 是 | 是 |
| 依赖数据库 | 不是 | 不是 | 是 | 是 |
| 周期内更新监听多次 | 不是 | 不是 | 是 | 是 |
| 区分插入和更新 | 不是 | 是 | 是 | 是 |
DBA执行:是否需要DBA支持,在源端系统(一般是数据库本身支持)做一些个性化配置。
不依赖数据库:技术选型不依赖数据库类型(例如关系数据库和分关系数据库包括大数据hadoop系列,redis,mongodb,memcache等)。(因为部分数据库不支持这些个性化配置,导致部分增量同步方式非普适性)
3、主流实现方式
基于SQL:
主要是离线调度查询作业,通过JDBC的方式,发起一次查询请求,服务端根据查询SQL进行解析、编译、执行优化、返回结果集。这个缺点也很明显,首先是增量捕获过程中,对源端数据库有侵入性,需要源端数据库有增量字段,一般是更新时间字段。其次是基于离线调度的方式,无法保证实时性和数据一致性。比如在查的过程中,数据可能已经产生了多次变化。最后,这种查询方式,对源端数据库有一定的IO压力,所以这种方法需要充分考虑源端系统压力,协调时间窗口,或者考虑从备库中进行数据集成。
基于数据库日志:
源端数据库通过启用日志(如Mysql的binlog,oracle的binlog等),将数据库变更记录完整、顺序的记录在日志中,我们把日志作为数据源,进行实时消费,并在下游进行数据还原。这样做保证了数据的一致性和实时性。但整体架构相对复杂,设计的时候要充分考虑重跑重刷得情况导致数据重复,需要考虑exactly-once技术。
4、常见的CDC技术实现
CDC技术实现可以从实时和离线大体两个风向做区分:
实时:canal、maxwell、Debezium、FlinkCDC、FlinkX等开源技术。
离线:Sqoop、DataX。
以上这几种开源数据的比较:
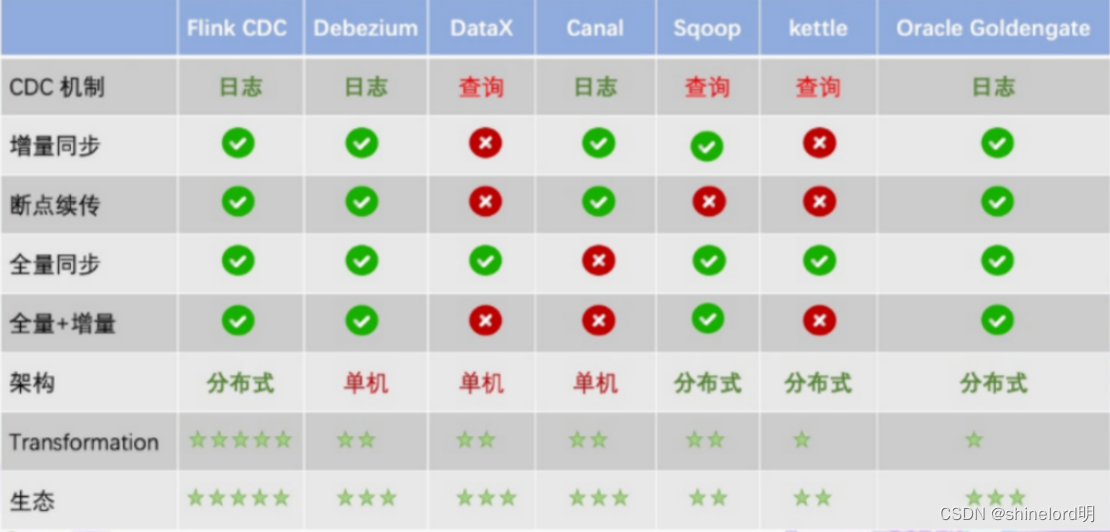
5、数据库BINLOG
binlog一般是关系数据库的操作日志,如Mysql,oacle,记录了数据的变更日志,定位一个LogEvent需要通过binlog fimename + binlog position。按照binlog生成方式,mysql支持三种配置:statement-based、row-based、mixed。一般建议使用ROW模式。
Statement:基于SQL语句的复制(statement-based replication, SBR),记录的是修改数据的SQL、不记录数据变化,减少日志量。但缺点是存在数据不一致的风险,如update t set create_date=now(),在binlog日志恢复时,会导致数据不一致。
Row:基于行的复制(row-based replication, RBR):仅保存哪条记录被修改,这种模式保证了数据的绝对一致性。缺点是,更新操作时,有多少记录被变化就会记录多少事件。
Mixed:混合模式复制(mixed-based replication, MBR):一般的复制使用Statement模式保存binlog,对于Statement模式无法复制的操作使用Row模式保存binlog。节省空间的同时,兼顾了一致性,但极个别情况仍有不一致的情况。
6、实时增量数据集成
Canal
主要用途是基于Mysql数据库增量日志解析,提供增量数据订阅和消费。目前支持MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
MaxWell
Maxwell同样可以实时读取Mysql的binlog,并生成Json信息,并作为生产者将数据同步给MQ,包括Kafka、Kinesis、RabbitMQ、Redis等。相比canal的优势就是使用简单,更轻量化,并且相比canal,支持初始化操作。
Debezium
Debezium最早是作为kafka连接器进行设计的,所以和kafka耦合性较强。消费binlog数据后,投递到kafka中,在依赖kafka的connector能力输出到其他存储中。后续的FlinkCDC等技术底层都是基于Debezium进行抽象、改造的。
FlinkCDC
传统的基于CDC的ETL分析中,通过先采集、然后依赖外部MQ进行数据投递、在下游消费后进行计算,最后在进行数据存储。整体的数据链路比较长,FlinkCDC的核心理念在于简化数据链路,底层集成了Debezium进行binlog的采集、省去了MQ部分、最后通过Flink进行计算。全链路上都基于Flink生态,比较清晰。
FlinkX
Flinkx已经更名为Chunjun,是一个基于Flink的批流统一的数据同步工具,既可以采集静态数据,也可以采集实时变化数据。功能上可以认为是扩展版的DataX(支持了实时变化数据采集)、从技术和架构上上也迎合了批流一体的概念,目前生态比较完善。
7、离线数据集成
Sqoop
目前Sqoop已经从apache顶级项目中被剔除,sqoop支持两个命令,import和export,分别完成关系型数据库到hive(import)、以及hive到关系型数据库(export)、任务触发时,会被解析成MapReduce执行。从当下来看,生态完善性较差,尤其是对数据使用的实时性要求、以及hive本身upsert较弱的局限性等,后续会逐步退出历史舞台。
Datax
阿里内被广泛使用的离线数据同步工具/平台,几乎实现了所有常见数据存储的扩展,支持各种异构数据源之间的数据同步。不在赘述


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











