







1、常用OLAP查询引擎
目前大数据比较常用的OLAP查询引擎包括:Presto、Impala、Druid、Kylin、Doris、Clickhouse、GreenPlum等。
不同引擎特点不尽相同,针对不同场景,可能每个引擎的表现也各有优缺点。下面就以上列举的几个查询引擎做简单介绍。
2、Presto
2.1、Presto简介
Presto是 Facebook 推出的一个开源的分布式SQL查询引擎,数据规模可以支持GB到PB级,主要应用于处理秒级查询的场景。Presto 的设计和编写完全是为了解决像 Facebook 这样规模的商业数据仓库的交互式分析和处理速度的问题。虽然 Presto 可以解析 SQL,但它不是一个标准的数据库。不是 MySQL、Oracle 的代替品,也不能用来处理在线事务(OLTP)。
2.2、Presto 应用场景
Presto 支持在线数据查询,包括 Hive,关系数据库(MySQL、Oracle)以及专有数据存储。一条 Presto 查询可以将多个数据源的数据进行合并,可以跨越整个组织进行分析(跨库执行)。Presto 主要用来处理 响应时间小于 1 秒到几分钟的场景 。
2.3、Presto架构
Presto 是一个运行在多台服务器上的分布式系统。完整安装包括一个 Coordinator 和多 个 Worker。由客户端提交查询,从 Presto 命令行 CLI 提交到 Coordinator。Coordinator 进行 解析,分析并执行查询计划,然后分发处理队列到 Worker 。
Presto也是一个master-slave架构的查询引擎。其架构图如下图所示:
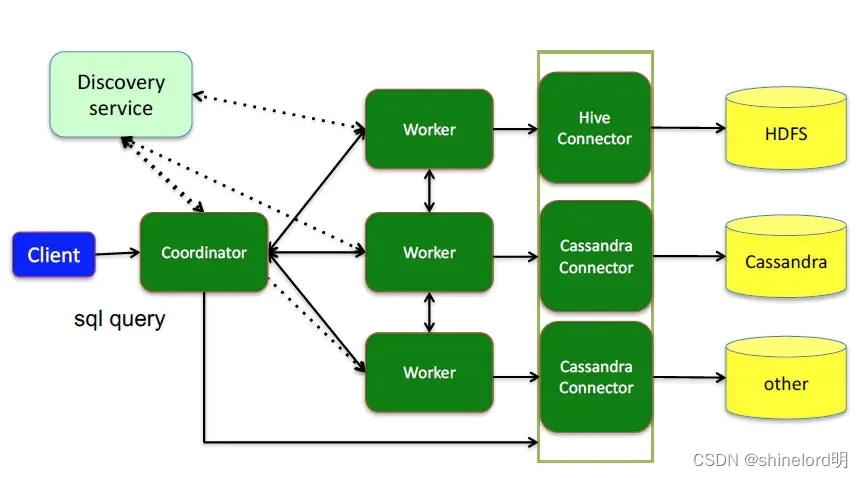
3、Impala
3.1、Impala简介
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala是一个MPP(大规模并行处理)SQL查询引擎:
- 是一个用
C++和Java编写的开源软件; - 用于处理存储在
Hadoop集群中大量的数据; - 性能最高的
SQL引擎(提供类似RDBMS的体验),提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。 - 使用impala,用户可以使用传统的SQL知识以极快的速度处理存储在HDFS、HBase和Amazon s3中的数据中的数据,而无需了解Java(MapReduce作业)。
- 由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
但是:
- 不提供任何对序列化和反序列化的支持;
- 只能读取文本文件,而不能读取自定义二进制文件;
- 每当新的记录/文件被添加到
HDFS中的数据目录时,该表需要被刷新; -
不支持text域的全文搜索;
-
不支持Transforms;
-
对内存要求高;
-
不支持查询期的容错。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









