







四、Linux性能优化诊断之pidstat+mpstat 命令说明(一)
Demo 大量等待CPU的进程调度 导致平均负载升高,CPU使用率也会比较高,系统是2核
九、Linux性能优化诊断pidstat+mpstat(二)
一、Linux操作系统CPU平均负载
1.1什么是CPU平均负载
单位时间内 系统处于【可运行状态】和【不可中断状态】的平均进程数,就是平均活跃进程数
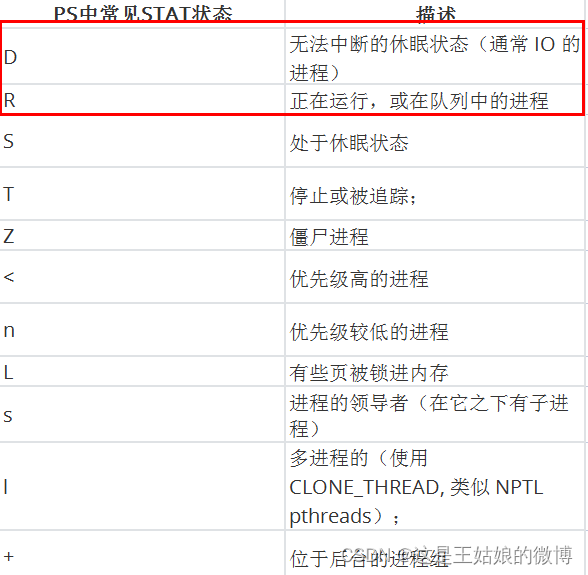
【可运行状态】
正在使用 CPU 或者正在等待 CPU 的进程
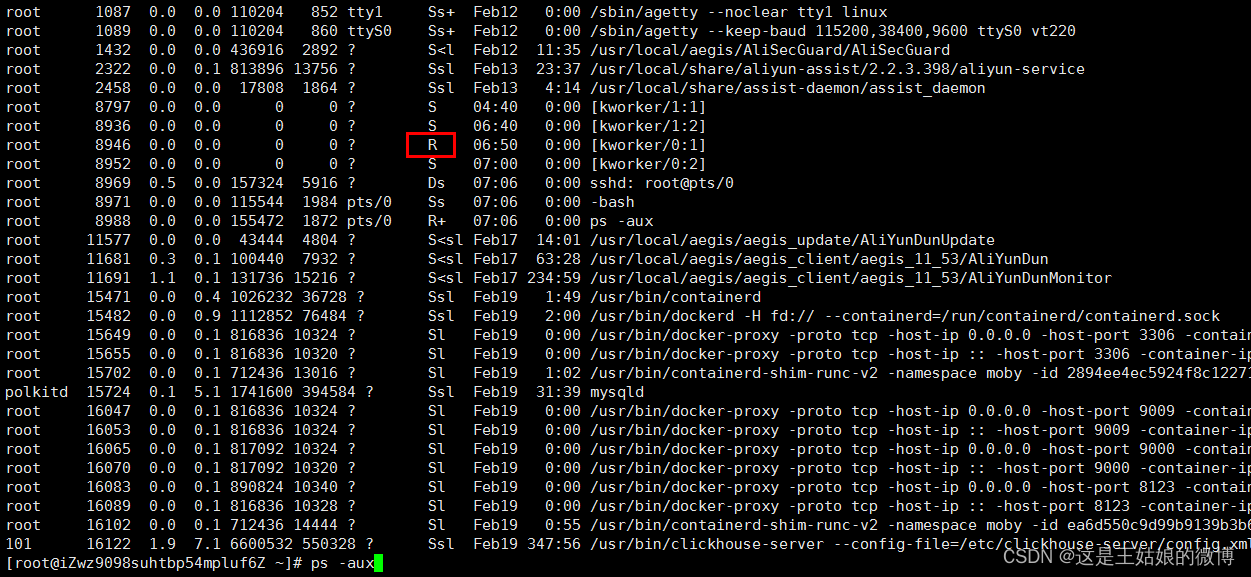
用 ps aux命令看到的,处于 R 状态(Running 或 Runnable)的进程【不可中断状态】
正处于内核态关键流程中的进程,且流程不可打断的,
比如 等待硬件设备的 I/O 响应,为了保证数据的一致性,进程向磁盘读写数据时,在得到磁盘响应前是不能被其他进程或者中断打断的
ps aux命令中 D 状态 的进程 Uninterruptible Sleep
1.2 怎么查看平均负载数值

load average:后的3个数字就分别代表着1分钟,5分钟,15分钟的CPU平均负载
查看服务器总的逻辑cpu个数【cat /proc/cpuinfo| grep "processor"| wc -l】如果平均负载数字是2,那么在2个CPU核数时候,刚刚好利用,那么在4个CPU核数的时候,则有50%空闲
分析:
1,5,15分钟的数值相差不大,说明负载很平稳
如果 1 分钟的值远小于 15 分钟的值,说明系统最近 1 分钟的负载在降低,而过去 15 分钟内却有很大的负载
如果 1 分钟的值远大于 15 分钟的值,最近 1 分钟的负载在增加,平均负载接近或超过了 CPU 的个数,意味着系统正在 发生过载的问题,持续的长时间则说明出现了问题需要优化
举例:在一个单核CPU 系统平均负载为 1.80,0.90,5.48
在过去 1 分钟内,系统有 80% 的超载,而在 15 分钟内,有 448% 的超载,从整体趋势来看,系统的负载在降低
二、Linux操作系统CPU使用率和平均负载区别
CPU使用率
CPU 非空闲态运行的时间占比,反映 CPU 的繁忙程度,和平均负载不一定完全一致
举例:
开发一个网站前期有2个前端,2个后端 也就是4核,
前期都很忙,4个人都有任务,这时候平均负载高,利用率也高
但是后期项目进入测试阶段了,前后端人员都在等待测试结果
这个时候cpu利用率就低了,但是负载依然是高的 因为4个人都在等
生产系统的 CPU 总使用率不要超过 70~80%
比如:
单核 CPU 1s 内非空闲态运行时间为 0.8s,那么它的 CPU 使用率就是 80%
双核 CPU 1s 内非空闲态运行时间分别为 0.4s 和 0.6s,总体 CPU 使用率就是 (0.4s + 0.6s) / (1s * 2) = 50%
Linux的 top 命令查看 CPU 使用率:
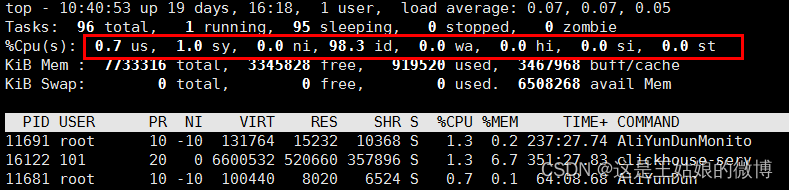

CPU使用率和平均负载区别
首先了解:
CPU密集型应用 也叫计算密集型,表示该任务需要大量的运算,没有阻塞CPU一直全速运行
比如对视频进行高清解码、机器学习和深度学习的模型训练等
IO密集型应用 程序需要大量I/O操作,大部分的时间是CPU在等IO (硬盘/内存) 的读写操作
CPU使用率低,但等待IO 也会导致平均负载升高
比如:数据库交互,文件上传下载,网络数据传输
当线程进行 I/O 操作 CPU 空闲时,启用其他线程继续使用 CPU,提高 CPU 的使用率
就跟你上班的时候没干太多活,光在5个项目中来回启动服务切换,导致压力大,但是对公司来说[利用率低]没产出
区别具体说明:
CPU 密集型进程,使用大量 CPU运算 会导致平均负载升高,这个场景这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
CPU 的效率要远高于磁盘,磁盘读写请求过多就会导致大量 I/O 等待
进程在 CPU 上访问磁盘文件,CPU 会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候CPU会切换到其他进程或者空闲
而此时任务会转换为 不可中断睡眠状态,当这种读写请求过多会导致不可中断睡眠状态的进程过多,导致CPU负载高,利用率低的情况
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高
三、阿里云Linux操作系统CPU压测环境准备
问题定位大致思路:先看全局,找系统哪个资源问题,是CPU还是IO还是什么瓶颈,然后再看具体哪个进程导致的这个资源有问题
3.1 核心命令+应用场景
sysstat 工具包的命令 mpstat+pidstat
命令:mpstat(全局)多核 CPU 性能分析程序,实时查看每个 CPU 的性能指标和全部 CPU 的平均性能指标
命令:pidstat (局部) 实时查看进程的 CPU、内存、I/O 、上下文切换等指标
命令:vmstat (全局)实时查看系统的上下文切换(跨进程间,同个进程里多个子线程)、系统中断次数
3.2 模拟生产环境出现的多种问题环境准备
安装环境:阿里云Linux CentOS7.X
分析工具安装:sysstat
下载地址:https://github.com/sysstat/sysstat 版本12.7.2 sysstat-master.zip
安装步骤:
yum install gcc -y
yum install unzip -y
cd /usr/local/software/arch
unzip sysstat-master.zipcd sysstat-master
./configure
makesudo make install
通过 pidstat -V 查看版本

两大模拟问题工具介绍+安装
stress 多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测
yum install -y epel-release
yum install stress -y
sysbench 多线程基准测试工具,模拟上下文切换过多场景等
yum -y install make automake libtool pkgconfig libaio-devel
yum -y install mariadb-devel openssl-devel
yum -y install postgresql-devel
unzip sysbench-master.zip
cd sysbench-master
./autogen.sh
./configure --without-mysql
make && make install
sysbench --version

四、Linux性能优化诊断之pidstat+mpstat 命令说明(一)
sysstat 工具包的命令 mpstat+pidstat
【全局命令】mpstat
全称 Multiprocessor Statistics,多核 CPU 性能分析程序,
场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导 致
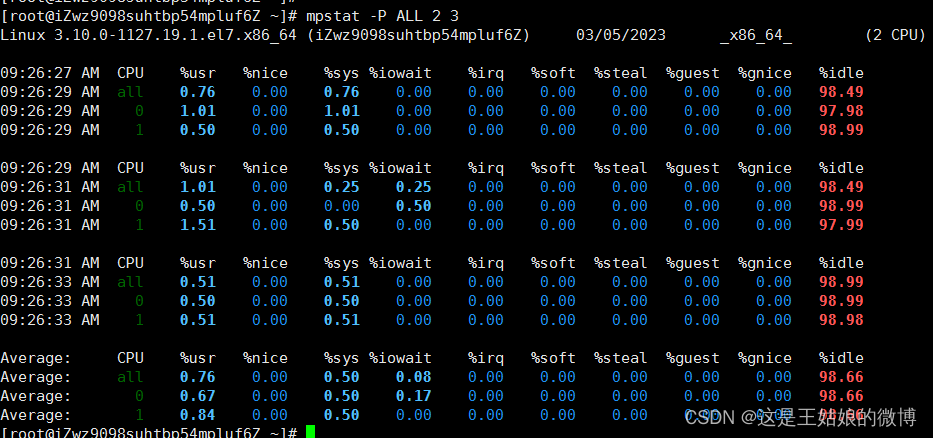
格式mpstat [-P {|ALL}] [ <时间间隔> ] [ <次数> ] 比如 mpstat -P ALL 2 3 每隔2秒出一个报告数据,共出具3次

显示信息 :
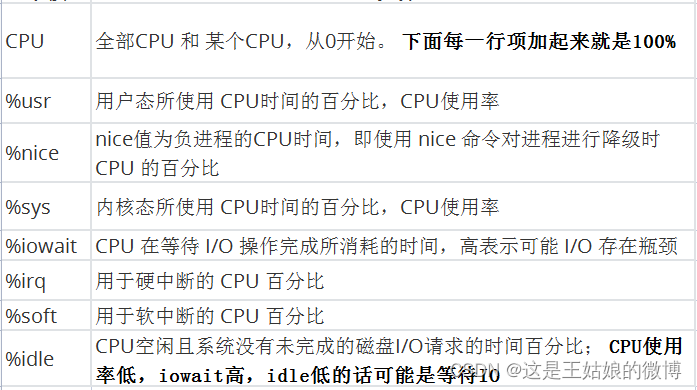
每列含义:
【局部命令】pidstat
实时查看进程的 CPU、内存、I/O 、上下文切换等指标
格式 pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ] 比如 pidstat -u 2 3每隔2秒出一个报告数据,一共出具3次
输出排序 pidstat -u | sort -k 9 -r,其中 sort是排序 指定排序用哪一列,下面的例子中是第9列:%CPU -r是倒序

显示信息: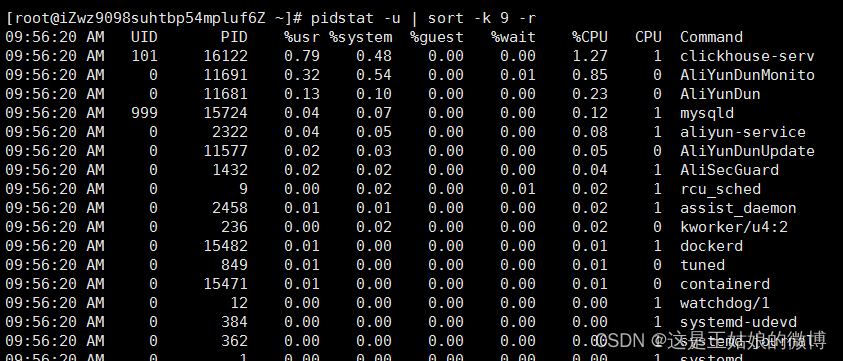
每列含义:
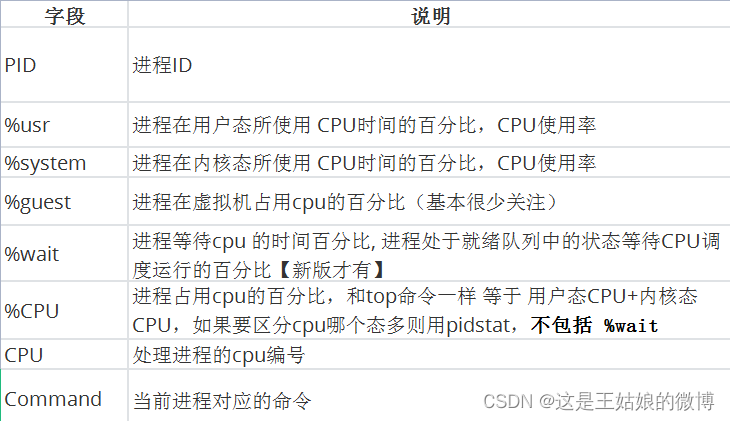
五、CPU密集型应用Demo性能指标分析
压测工具 stress
多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测
参数说明:

Demo 模拟CPU密集型应用,系统是2核
终端一 模拟两个CPU核的使用率 100%,对2个cpu 进行压力测试 持续600s stress --cpu 2 --timeout 600
终端二 -d 参数表示高亮显示变化的区域 watch -d uptime
终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况 mpstat -P ALL 5
终端四 查看运行中的进程和任务,每5秒刷新一次 pidstat -u 5
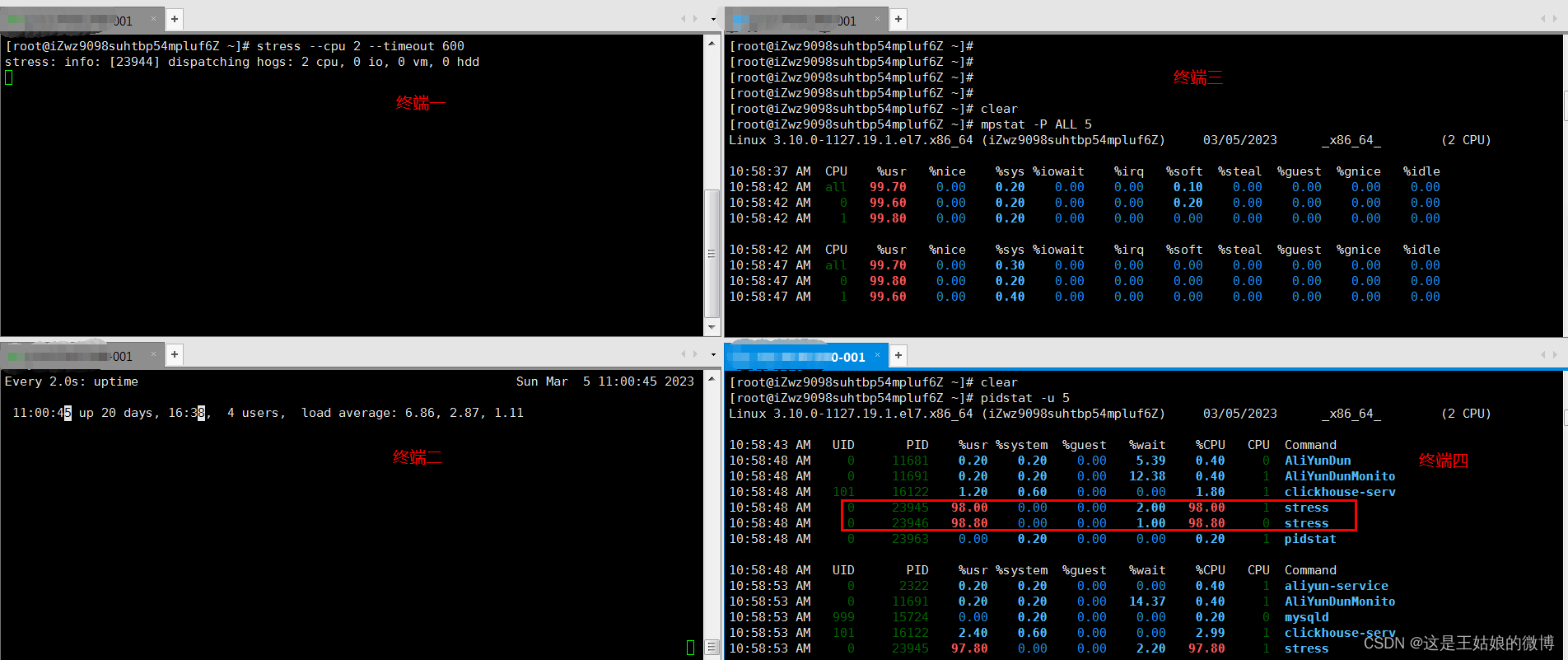
分析思路:
全局
uptime :运行1分钟后,2个核的CPU负载是2,高负荷可以到4,5+
mpstat :
实际应用场景:当系统变慢,CPU平均负载增大时,可判断是CPU的使用率增大,还是IO压力增大的情况导致
CPU的两个核在用户态使用率是99%,总的CPU使用率是100%,% iowait 为0,不存在io瓶颈因为sqrt()函数的 CPU进程是在用户态,所以是%usr升高,而%sys没啥变化
局部
pidstat: 对进程和任务的使用情况进行,发现stress进程对2块cpu使用率过高,导致CPU平均负载增加
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程,包括压测4个核
CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高
六、CPU密集型应用-内核态Demo性能指标分析
压测工具 stress
多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测
参数说明:

Demo 模拟CPU密集型应用,系统是2核
终端一 模拟四个IO进程, 持续600s stress --io 2 --timeout 600s
终端二 -d 参数表示高亮显示变化的区域 watch -d uptime
终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况 mpstat -P ALL 5
终端四 查看运行中的进程和任务,每5秒刷新一次 pidstat -u 5
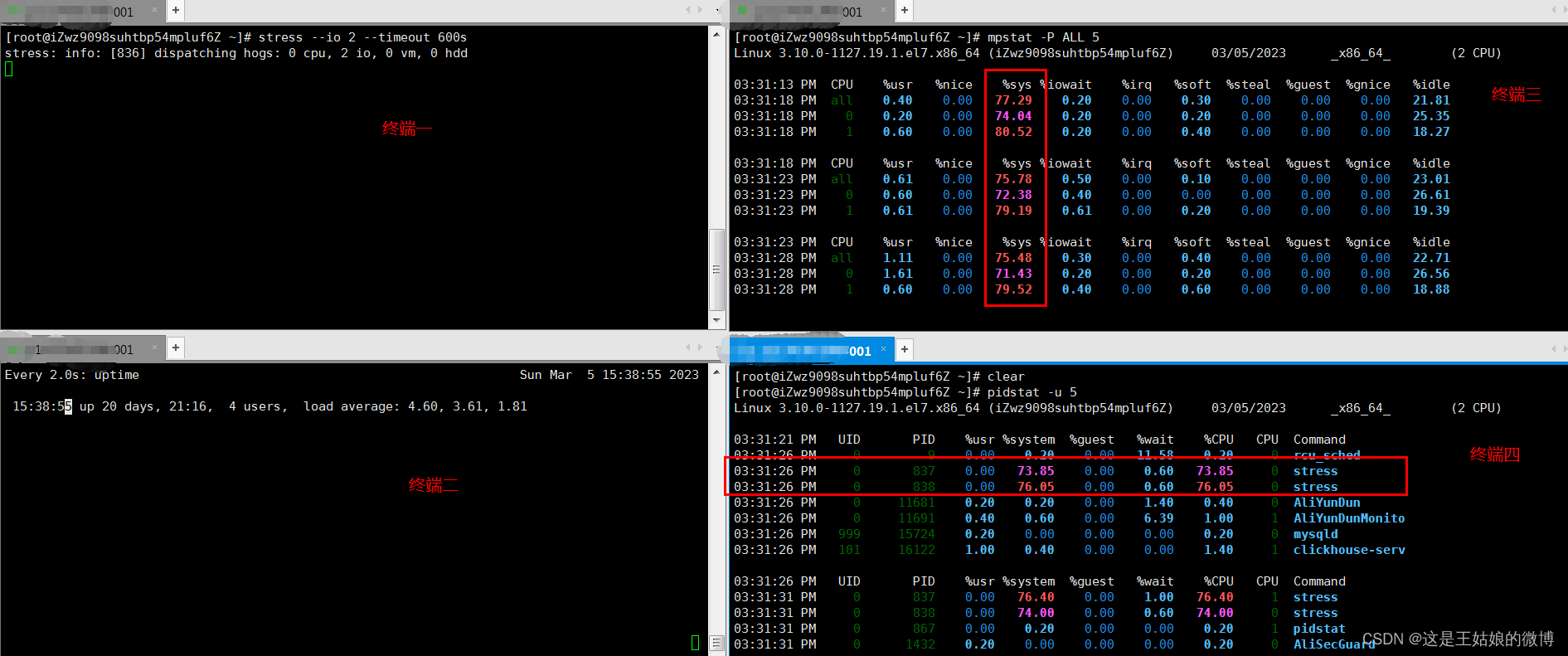
分析思路:
全局
uptime :运行1分钟后,2个核的CPU负载是比较高的
mpstat :
应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
多次调用mpstat,持续观察, 平均负载升高,内核态CPU使用率%sys 比较高,iowait也有一定数值
局部
pidstat: 对进程和任务的使用情况进行,发现stress进程对cpu使用率比较高,导致CPU平均负载增加
%wait有一定数值,但是不高,使用 pidstat -d 查看 没太多磁盘读写,但是有iodelay
七、IO密集型应用Demo性能指标分析
压测工具工具 stress
多进程工具 ,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景, 对CPU,内存,IO等情况进行压测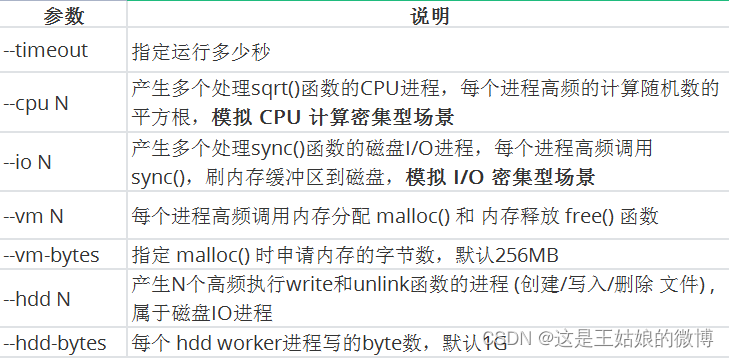
pidstat 查看进程IO使用情况,显示各活动进程的IO使用统计
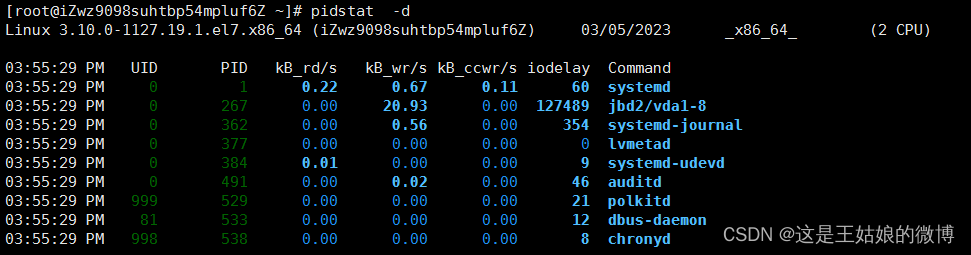
每列含义:

Demo 模拟IO密集型应用,系统是2核
终端一 模拟两个磁盘IO进程, 持续600s stress --hdd 2 --hdd-bytes 6G --timeout 600s
终端二 -d 参数表示高亮显示变化的区域 watch -d uptime
终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况 mpstat -P ALL 2 3 每隔2秒出一个报告数据,一共出具3次
终端四 查看运行中的进程和任务,每5秒刷新一次 pidstat -u 2 3 每隔2秒出一个报告数据,一共出具3次 或者 pidstat -d 2 2
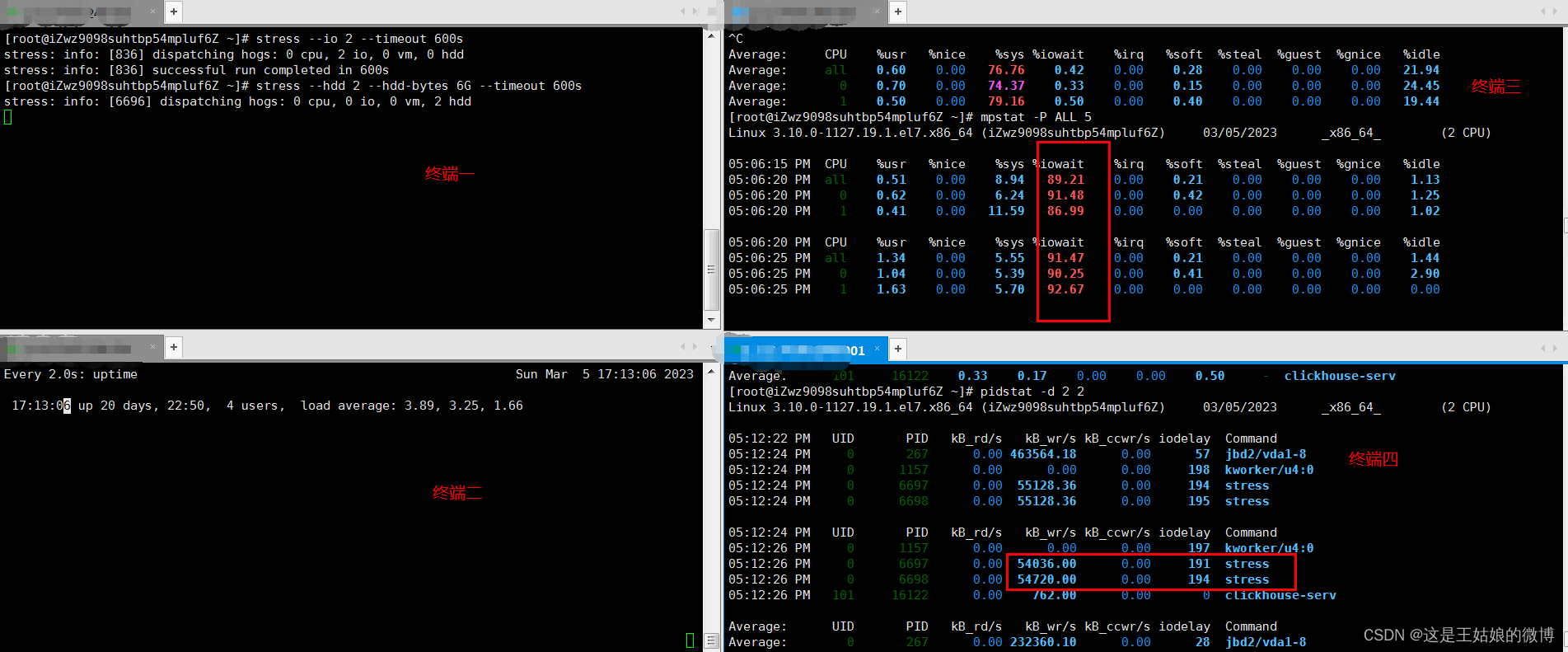
分析思路:
全局
uptime :运行1分钟后,2个核的CPU负载是比较高
mpstat :
应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
多次调用mpstat,持续观察, 平均负载升高,但是CPU使用率没啥变化,iowait大于50%值比较高
一直在等待IO处理,说明进程是IO密集型,进程频繁进行IO操作,导致系统平均负载很高,而CPU使用率不高局部
ps aux 里面stat字段D的状态一般是I/O出现了问题,说明进程在等待I/O,比如 磁盘I/O,网络I/O或者其他
pidstat : 对进程和任务的使用情况进行,发现stress进程对cpu使用率不高,但CPU平均负载高
pidstat -u
pidstat -d
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
CPU使用率高,CPU平均负载也高; CPU平均负载高,CPU使用率不一定高,则可能IO瓶颈
ps aux

八、多进程调度Demo性能指标分析
前言:
CPU密集型进程,使用大量CPU会导致平均负载高,此时cpu使用率也高
I/O密集型进程, 等待I/O导致负载升高,但CPU使用率不一定高
大量进程等待CPU调度也会导致平均负载升高,CPU使用率也会比较高
Demo 大量等待CPU的进程调度 导致平均负载升高,CPU使用率也会比较高,系统是2核
终端一 模拟4个进程,也可以更多, 持续600s stress --cpu 4 --timeout 600s
终端二 -d 参数表示高亮显示变化的区域 watch -d uptime
终端三 mpstat 查看 CPU 使用率情况, 每5秒监控所有 CPU情况 mpstat -P ALL 2 3 每隔2秒出一个报告数据,一共出具3次
终端四 查看运行中的进程和任务,每5秒刷新一次 pidstat -u 2 3 每隔2秒出一个报告数据,一共出具3次
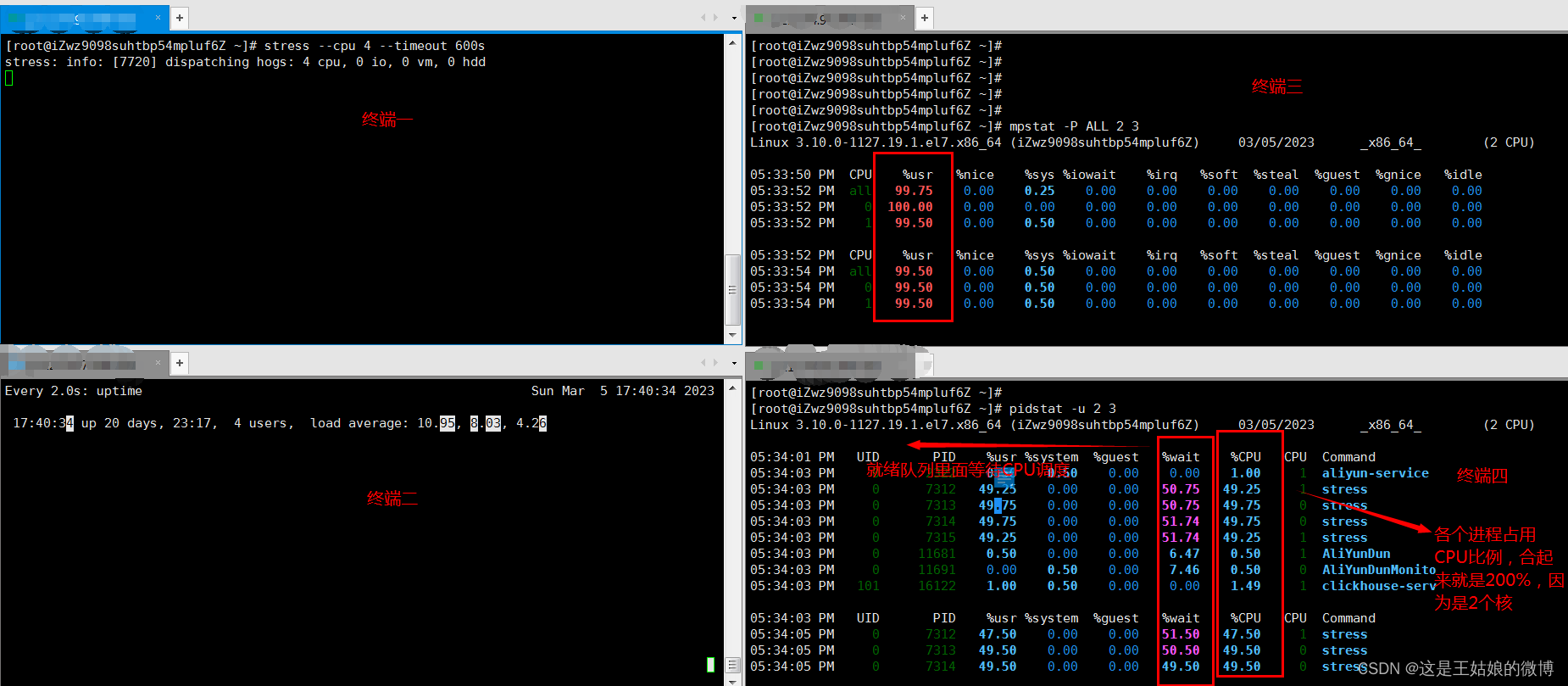
分析思路:
全局
uptime :运行1分钟后,2个核的CPU负载是比较高
mpstat :
应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
多次调用mpstat,持续观察, 平均负载升高,每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU局部
pidstat : 对进程和任务的使用情况进行,发现%wait高,说明cpu不够用在等待cpu调度上花费了不少时间
结论:4个进程在竞争2个cpu,每个进程等待cpu的时间达到50%(%wait),超出cpu计算能力的进程,导致了负载变高
pidstat -u CPU情况,默认
pidstat -d 磁盘IO情况 , 基本很低
举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程
九、Linux性能优化诊断pidstat+mpstat(二)
pidstat(局部)
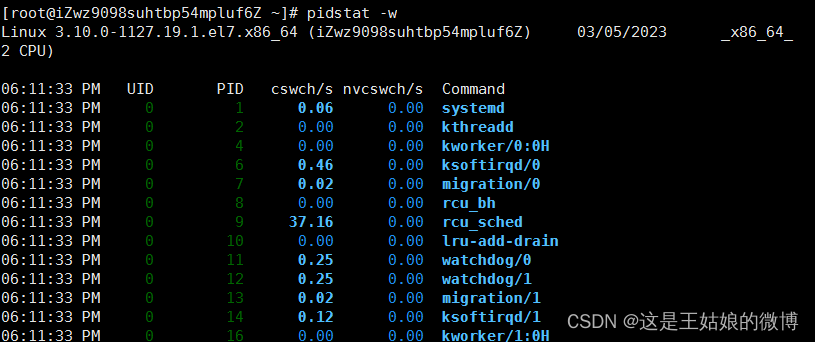
pidstat -w 进程上下文切换情况,显示各活动进程的上下文切换情况统计
cswch/s 每秒自愿上下文切换(voluntary context switches)的次数
进程获取不了所需要的资源导致的上下文切换
比如 出现 I/O问题瓶颈、内存等系统资源不足,会发生自愿上下文切换
nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数
进程由于调度算法,时间片已到等原因,被系统【强制调度】发生上下文切换
比如 大量进程再抢夺CPU资源时,会发生非自愿上下文切换,CPU出现了瓶颈

pidstat -t -p pid 显示进程里面的线程的统计信息
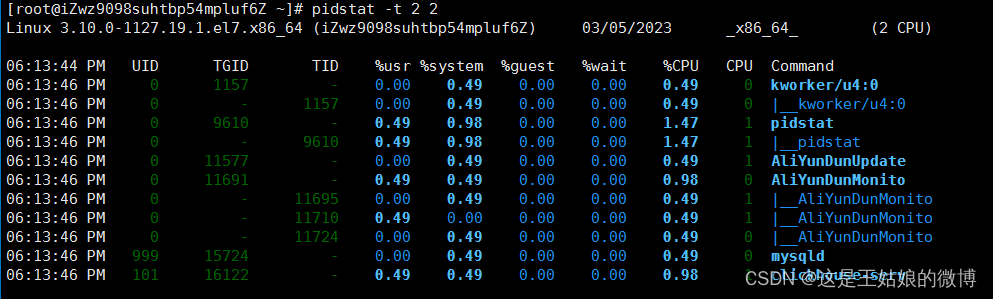
每列含义:
pidstat -wt 1 组合命令 ,看具体进程里面的线程上下文切换情况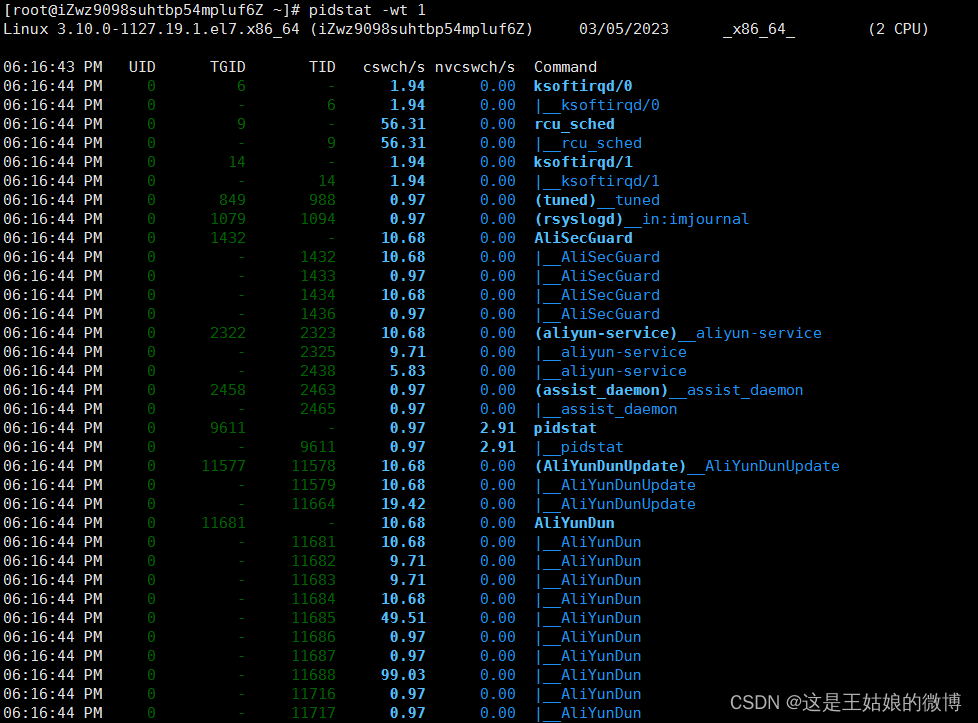
十、Linux性能监控命令vmstat
vmstat (全局)
全称是 Virtual Meomory Statistics(虚拟内存统计)的缩写,是对系统整体的情况进行统计,不细化到某个进程,是宏观命令
格式:vmstat [选项] [时间间隔[次数]] (参数很多,记住常用的即可)
vmstat n 每隔n秒后输出一行信息, 一般会加个 -w 进行加宽显示,比如 vmstat -w 1
vmstat -SM 指定单位显示,默认KB,M表示是MB
vmstat -t 带上时间戳信息
更多参数信息 vmstat -h 或 man vmstat
vmstat -w -SM -t 1

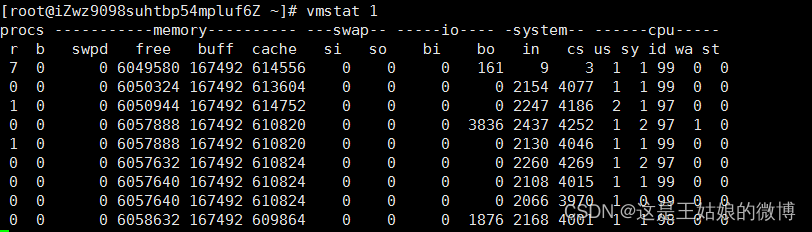

十一、CPU上下文切换Demo性能指标分析
cpu上下文切换知识点:
cpu寄存器和程序计数器是cpu在运行任务前依赖的环境,也叫cpu上下文
cpu的上下文切换先把前一个任务的cpu上下文保存起来【下次才知道任务从哪里加载+运行】
再加载新任务的上下文到寄存器和程序计数器进行运行任务,每次切换 在【保存和恢复】上下文耗时几十纳秒 或 微秒
1μs【微秒】 = 1000ns【纳秒】
sysbench
一款开源的多线程性能测试工具,模拟线程上下文切换过多场景等,可以执行CPU/内存/线程/IO/数据库等方面的性能测试
Demo 大量线程进行上下文切换,导致平均负载升高,CPU使用率也会比较高,系统是2核
终端一 模拟32个线程进行压测, 持续300s sysbench --threads=32 --time=300 threads run
终端二 -d 参数表示高亮显示变化的区域 watch -d uptime
终端三 vmstat -w 1 查看系统CPU的队列情况、内存、块I/O、上下文切换情况、系统中断次数、cpu使用率等
和mpstat命令有交集,都是可以看出cpu使用率,在内核态、用户态等终端四 pidstat -w 查看运行中的进程和任务上下文切换情况统计,显示各活动进程的上下文切换情况统计
pidstat -u 2 2
pidstat -t -p pid 显示进程里面的线程的统计信息
pidstat -wt 1 组合命令,查看进程里面具体线程的上下文切换情况
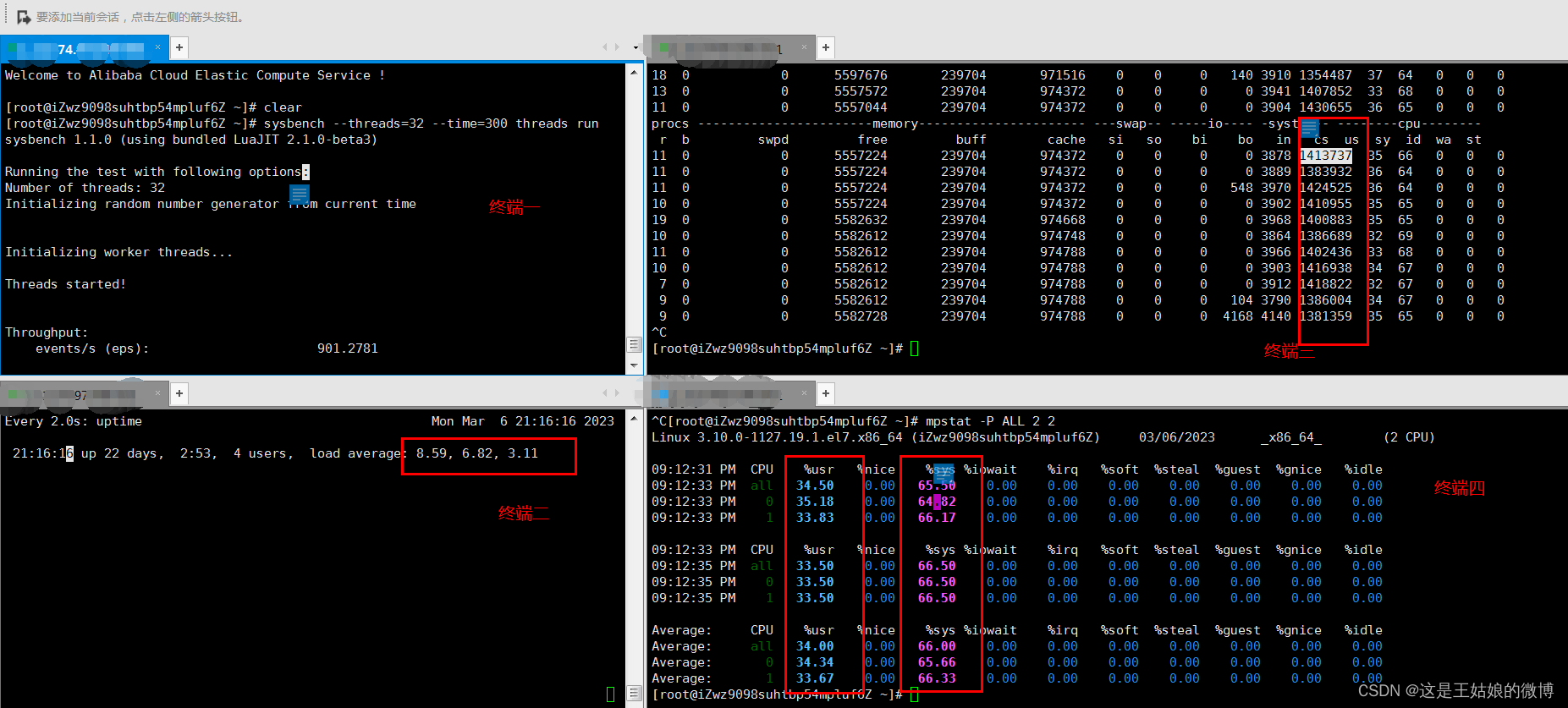
可以看到是sysbench 服务导致大量CPU被占用
分析思路:
uptime(全局) :运行1分钟后,2个核的CPU负载是比较高
mpstat:
应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
多次调用mpstat -P ALL 2 2,持续观察, 每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
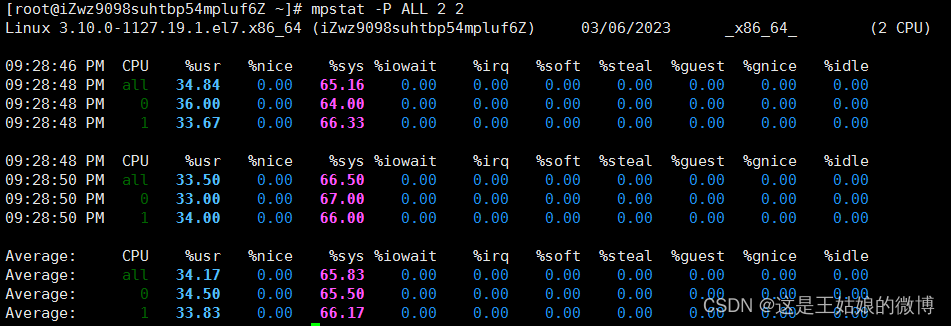
再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU?
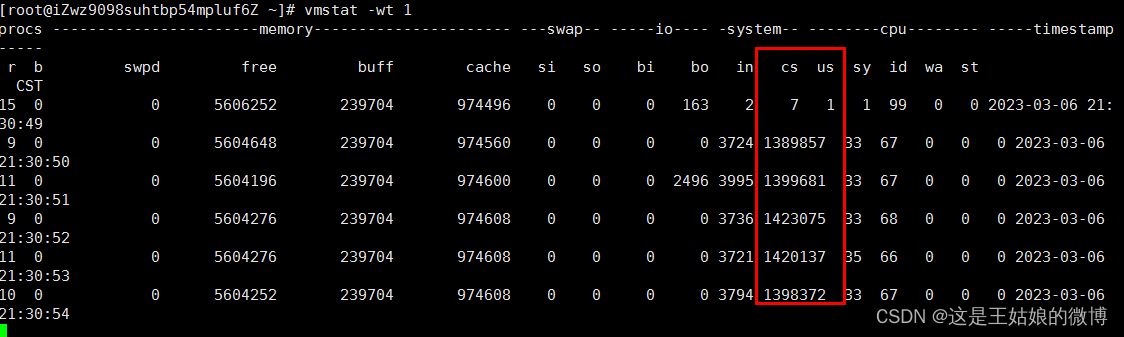
vmstat(全局):系统总的上下文切换情况,就绪队列里面的线程数,不可中断睡眠状态的进程数等
vmstat -wt 1 发现:上下文切换次数和中断次数数值比较高 in:中断次数 cs:上下文切换次数
pidstat -u 2 2: 对进程和任务的使用情况进行,发现CPU使用率接近100%,前面知道是大量上下文切换导致
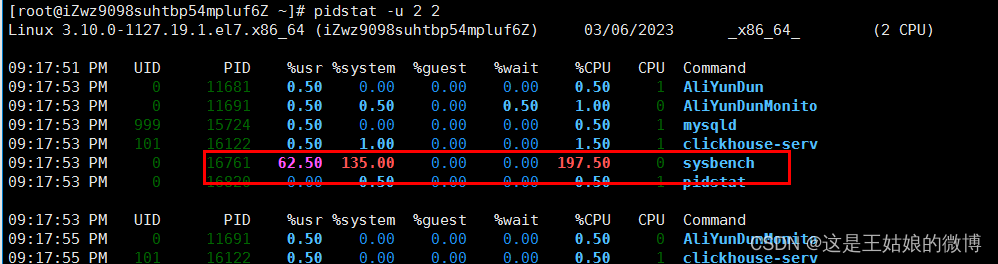
pidstat -wt 2 2 查看哪个进程大量占据上下文切换,到进程里面的具体线程,大量上下文切换,导致了负载变高
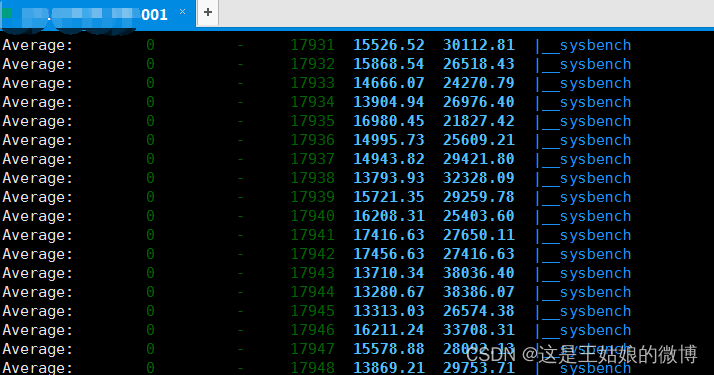
pidstat -u CPU情况
pidstat -d 磁盘IO情况
pidstat -t 显示进程里面的线程的统计信息
pidstat -w 进程上下文切换情况,查看是哪种上下文切换占比高
如果没加 -t则是进程上下文切换,和vmstat的数据不一样,所以推断出是进程内部的大量线程切换导致
加 -t 发现 nvcswch 高,大量线程抢夺CPU资源导致
pidstat -w 不加-t表示进程上下文
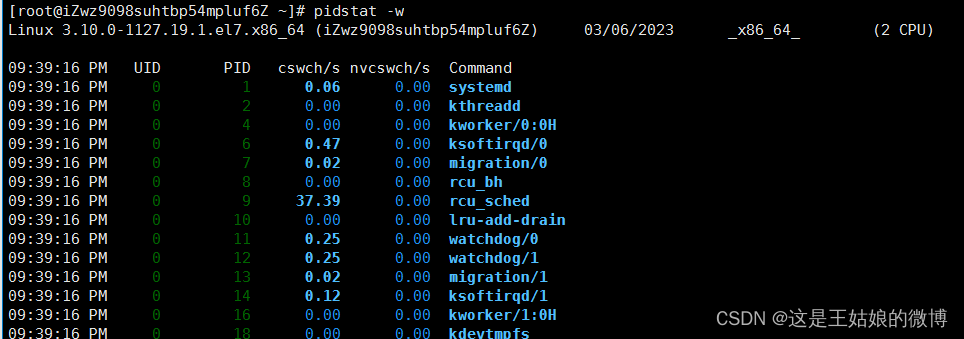
cswch/s 每秒自愿上下文切换(voluntary context switches)的次数
进程获取不了所需要的资源导致的上下文切换
比如 出现 I/O问题瓶颈、内存等系统资源不足,会发生自愿上下文切换nvcswch/s 每秒非自愿上下文切换(non voluntary context switches)的次数
进程由于调度算法,时间片已到等原因,被系统【强制调度】发生上下文切换
比如 大量进程再抢夺CPU资源时,会发生非自愿上下文切换,CPU出现了瓶颈
命令总结:
watch -d uptime 查看平均负载
top 查看CPU 内核态、用户态 使用率等指标
mpstat -P ALL 实时查看每个 CPU 的性能指标和全部 CPU 的平均性能指标
pidstat -u 实时查看进程的 CPU、内存、I/O 、上下文切换等指标
pidstat -d 查看运行中的进程和任务,显示各个进程的IO使用情况
pidstat -w 进程上下文切换情况,显示各活动进程的上下文切换情况统计
pidstat -wt 1 查看进程里面具体线程的上下文切换情况















 2744
2744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









