







凡是让你着迷的事物,背后往往都是满满的套路。——二师兄

今天给大家分享的一本书是关于爆款文章写作的——《爆款写作课》,看完之后真是感慨颇多。感慨什么呢?原来每一篇爆款文章都是满满的套路。有些文章是有真才实学,再加上写作技巧,短时间内达到10W+,100W+的阅读量,真是人气爆棚;有些文章则完全是技巧的堆砌,不值一提,却获得你获得不到的人气。
这本书适合什么读者来看呢?如果你是内容运营者或者销售者(互联网运营销售),你可以读读这本书;如果你想了解爆款文章是如何写出来的,你也可以读读这本书;如果你是内容运营的小白,那么你可能会大开眼界;如果你是文学类作家,书中有些技巧对你有用,但可能没有你想象中的那么大。

看完这本书再对照《得到》和其他付费课程的推销策略,简直是按照书中的套路一条条在设计。难怪那么多人会去购买那些课程,因为课程背后的营销策略抓住了读者内心最深处的欲望。这里就暂且不讨论那些课程的好坏、知识付费和碎片化学习的问题。
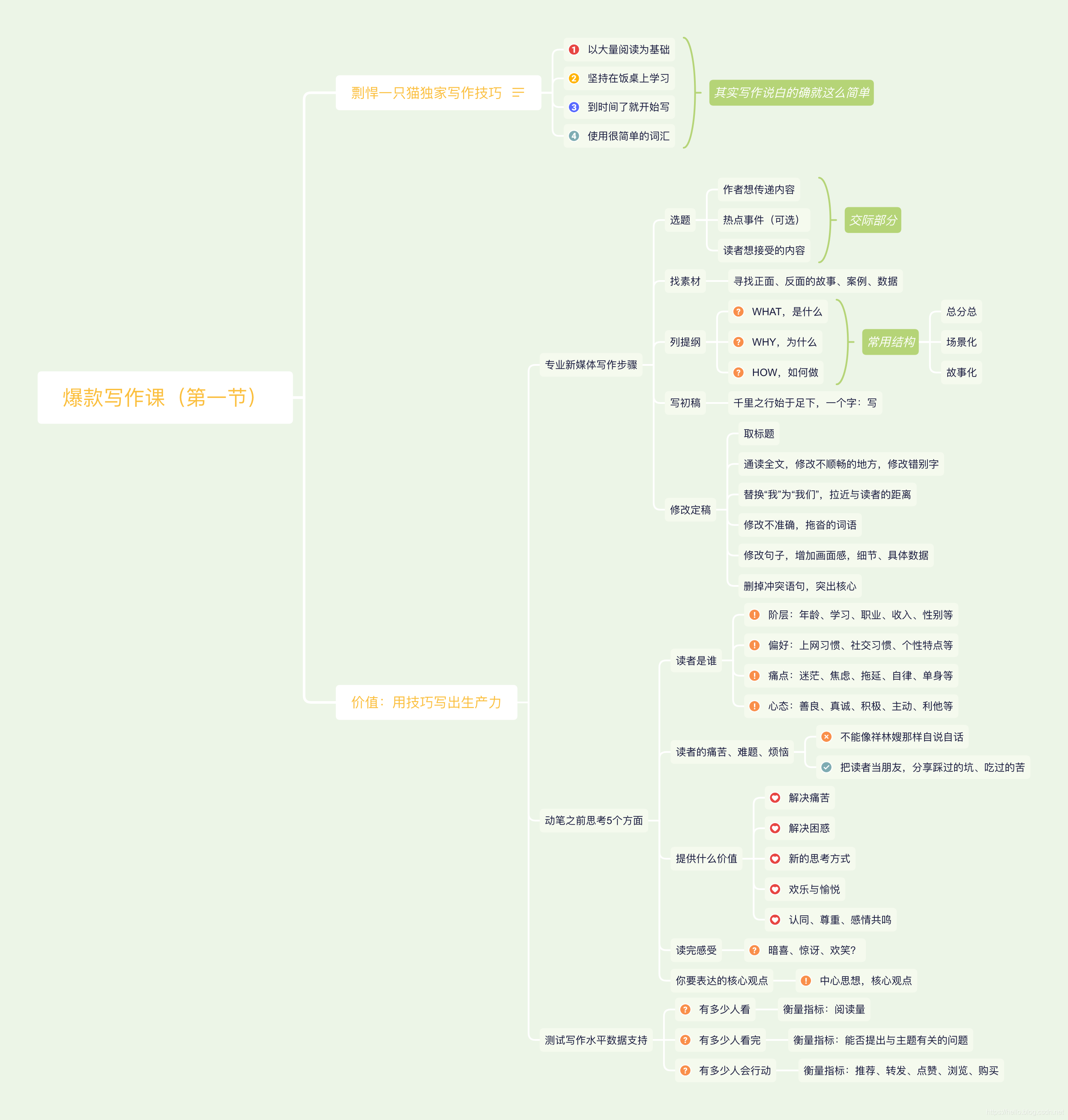
整体来说,书中从以下几个方面来介绍写作的技巧:
- 写书的整个流程及相关技巧:选题、找素材、列提纲、写初稿、修改定稿。
- 动笔之前要思考用户的痛点及能够用户带来什么价值。
- 读者愿意阅读、分享、购买等行动的底层动力分析。
- 如何通过筛选题材来吸引读者。
- 如何通过标题来吸引读者。
- 如何通过内容的环环相扣来吸引读者。
- 写作的技巧和作者所站立场等细化介绍。
- 如何通过说服力来引导读者阅读或购买。
- 具体案例分析。
通过这本书我学习到的也是想强调的重点是:无论使用什么技巧,前提条件是你的作品能够为读者解决问题、解决痛点、带来价值!而所谓的标题、选题以及其他相关技巧只是在其基础上的辅助手段。如果把它们当成主要方式,可能只会画虎不成反类犬。

另外这本书的缺点和不足也很明显。第一,全书只有270页,页面却有大量留白和可有可无的插图,仅仅有效内容可能只有一半多一点;第二,书中大量内容重复,前面章节在说,后面章节也在说,不同的主题引用同样的内容;第三,整体章节内容排版不够流畅,显得逻辑上有些混乱,给人一种不像专业作家的写作水平,而更像是各种东拼西凑(说的有些严厉);第四:实战部分引入实例内容占用大量篇幅;第五,如果是你是文学作者,收获可能不会太大。
下面依照老规矩,给大家分享这本书读书笔记之思维导图。这里只贴出前三节的导图内容,全部内容(Xmind Zen格式或PNG格式)大家可关注微信公众号《程序新视界》,回复“爆款写作课”获得。


为了不影响阅读体验,其余章节,大家可关注微信公众号《程序新视界》,回复“爆款写作课”获得。



















 2167
2167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











