









1.使用<br>标签分行显示文本
对于上一小节的例子,我们想让那首诗显示得更美观些,如显示下面效果:
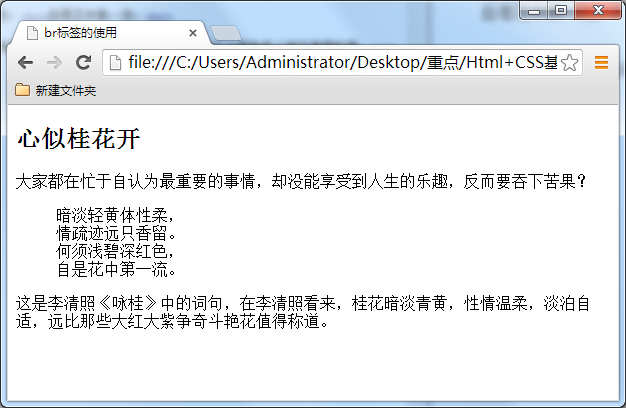
怎么可以让每一句诗词后面加入一个折行呢?那就可以用到<br />标签了,在需要加回车换行的地方加入<br />,<br />标签作用相当于word文档中的回车。
上节的代码改为:

语法:
xhtml1.0写法:
<br />
html4.01写法:
<br>
大家注意,现在一般使用 xhtml1.0 的版本的写法(其它标签也是),这种版本比较规范。
与以前我们学过的标签不一样,<br />标签是一个空标签,没有HTML内容的标签就是空标签,空标签只需要写一个开始标签,这样的标签有<br />、<hr />和<img />。
讲到这里,你是不是有个疑问,想折行还不好说嘛,就像在 word 文件档或记事本中,在想要折行的前面输入回车不就行了吗?很遗憾,在 html 中是忽略回车和空格的,你输入的再多回车和空格也是显示不出来的。如下边的代码。

上面的代码在浏览中显示是没有回车效果的。如下图所示:
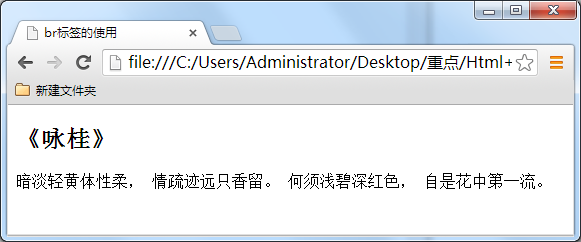
总结:在 html 代码中输入回车、空格都是没有作用的。在html文本中想输入回车换行,就必须输入<br />。
2.为你的网页中添加一些空格
在上一节的例子,我们已经讲解过在html代码中输入空格、回车都是没有作用的。要想输入空格,必须写入 。
语法:
在html代码中输入空格是不起作用的,如下代码。

在浏览中显示,还是没有空格效果。

输入空格的正确方法:

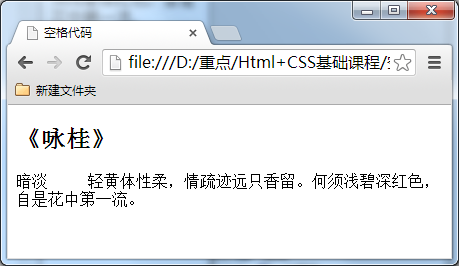
在浏览器中的显示出来的空格效果。如下图所示。
3.认识<hr>标签,添加水平横线
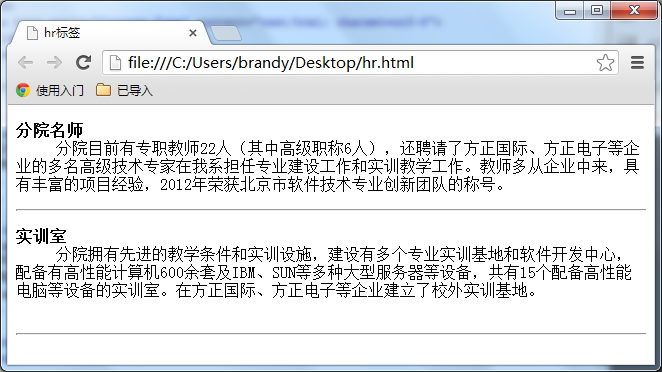
在信息展示时,有时会需要加一些用于分隔的横线,这样会使文章看起来整齐些。如下图所示:
语法:
html4.01版本 <hr>
xhtml1.0版本 <hr />
注意:
1. <hr />标签和<br />标签一样也是一个空标签,所以只有一个开始标签,没有结束标签。
2. <hr />标签的在浏览器中的默认样式线条比较粗,颜色为灰色,可能有些人觉得这种样式不美观,没有关系,这些外在样式在我们以后学习了css样式表之后,都可以对其修改。
3. 大家注意,现在一般使用 xhtml1.0 的版本(其它标签也是),这种版本比较规范。
4.<address>标签,为网页加入地址信息
一般网页中会有一些网站的联系地址信息需要在网页中展示出来,这些联系地址信息如公司的地址就可以<address>标签。也可以定义一个地址(比如电子邮件地址)、签名或者文档的作者身份。
语法:
<address>联系地址信息</address>
如:
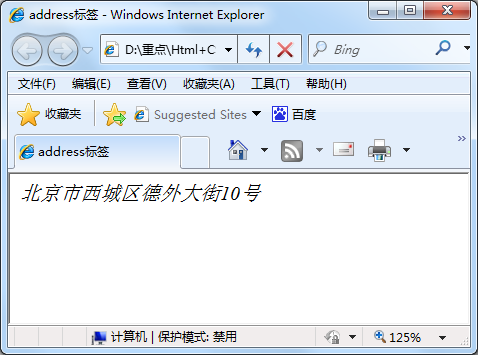
<address>文档编写:lilian 北京市西城区德外大街10号</address>
<address> 本文的作者:<a href="mailto:lilian@imooc.com">lilian</a> </address>
在浏览器上显示的样式为斜体,如果不喜欢斜体,当然可以,可以在后面的课程中使用 css 样式来修改它<address>标签的默认样式。
5.想加入一行代码吗?使用<code>标签
在介绍语言技术的网站中,避免不了在网页中显示一些计算机专业的编程代码,当代码为一行代码时,你就可以使用<code>标签了,如下面例子:
<code>var i=i+300;</code>
注意:在文章中一般如果要插入多行代码时不能使用<code>标签了。
语法:
<code>代码语言</code>
注:如果是多行代码,可以使用<pre>标签。
6.使用<pre>标签为你的网页加入大段代码
在上节中介绍加入一行代码的标签为<code>,但是在大多数情况下是需要加入大段代码的,如下图:
怎么办?不会是每一代码都加入一个<code>标签吧,没有这么复杂,这时候就可以使用<pre>标签。
语法:
<pre>语言代码段</pre>
<pre> 标签的主要作用:预格式化的文本。被包围在 pre 元素中的文本通常会保留空格和换行符。
如下代码:
<pre>
var message="欢迎";
for(var i=1;i<=10;i++)
{
alert(message);
}
</pre>
在浏览器中的显示结果为:
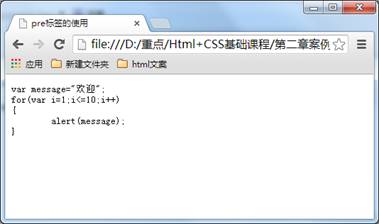
在上面的例子中可以看到代码中的空格,换行符都保留下来。如果用以前的方法,回车需要输入<br>签,空格需要输入
注意:<pre> 标签不只是为显示计算机的源代码时用的,在你需要在网页中预显示格式时都可以使用它,只是<pre>标签的一个常见应用就是用来展示计算机的源代码。















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









