






 本文详细介绍如何使用Telegraf 1.24.4版本从HTTP源收集数据并将其写入InfluxDB 2.0。包括生成配置文件、指定输入与输出、测试配置等步骤。
本文详细介绍如何使用Telegraf 1.24.4版本从HTTP源收集数据并将其写入InfluxDB 2.0。包括生成配置文件、指定输入与输出、测试配置等步骤。
这边文章主要介绍telegraf (Telegraf 1.24.4 (git: HEAD@c79edb5b))
telegraf是一个数据收集和写出的代理,可以从各种输入源收集数据,进行处理,聚合,然后再写出到各种输出源。
借用知乎上的一章图片说明原理和功能:
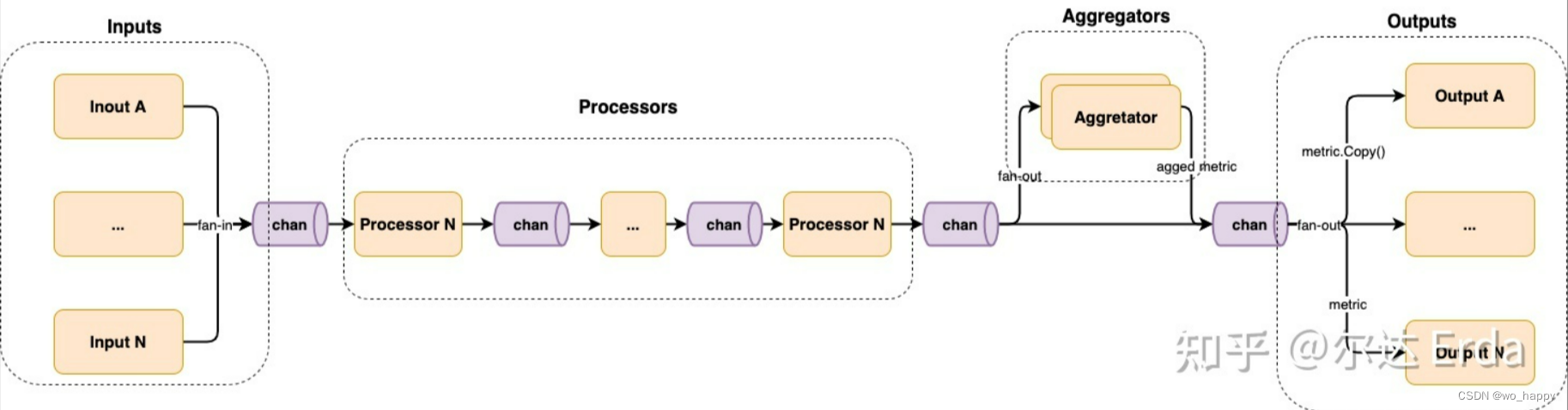
由于网上关于telegraf的介绍的版本都太老了,无法按照上面的步骤正确配置。经过不懈摸索,终于配置成功了。
配置步骤为:首先是生成一个默认的telegraf.conf文件,然后修改这个配置文件,然后运行telegraf并指定这个配置文件。
生成一个默认的telegraf.conf文件
telegraf --sample-config > telegraf.conf
指定一个输入http_listener_v2和一个输出influxdb_v2
![]()
生成的.conf文件中,输入和输出分别只保留了一个,处理processors和聚合aggregators还保留着呢。
配置文件中使用环境变量(可选),下面是官网截图。

测试telegraf.conf
telegraf --config telegraf.conf -test
运行telegraf
telegraf --config telegraf.conf 或 telegraf (默认使用/etc/telegraf/telegraf.conf)
下面重点讲如何修改telegraf.conf文件
(1)使用inputs.http_listener_v2
[[inputs.http_listener_v2]]
service_address = ":8099"
paths = ["/telegraf"]
methods = ["POST", "PUT"]
read_timeout = "10s"
write_timeout = "10s"
max_body_size = "500MB"
data_format = "influx"生成的默认文件对上面的每一条都有注释,为方便查看删除了注释。这里需要注意配置的数据格式是influx line protocal。对这种格式不理解的读者看本系列文章(一)。
(2)配置输出: outputs.influxdb_v2
# Configuration for sending metrics to InfluxDB 2.0
[[outputs.influxdb_v2]]
urls = ["http://192.168.1.7:8086"]
token = <你的all access API token>
organization = <用户所属组织,创建数据库登陆用户的时候指定的>
bucket = <要写入的bucket>
timeout = "5s"(3)测试
下面是用postman发送的数据(需要注意时间单位是纳秒):
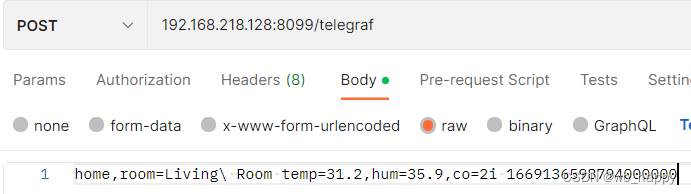
发送之后回复2.04表示发送成功。进入Influxdb查看刚才插入的数据,已经成功。
(4)使用json_v2作为输入源
这里在本地配置了http server,然后放入了一个json文件,下载地址为:
https://feeds.citibikenyc.com/stations/stations.json
[[inputs.http]]
# URL for NYC's Citi Bike station data in JSON format
#urls = ["https://gbfs.citibikenyc.com/gbfs/en/station_status.json"]
urls = ["http://localhost/station_status.json"]
# Overwrite measurement name from default `http` to `citibikenyc`
name_override = "citibike"
# Exclude url and host items from tags
tagexclude = ["url", "host"]
# Data from HTTP in JSON format
data_format = "json_v2"
# Add a subtable to use the `json_v2` parser
[[inputs.http.json_v2]]
# Add an object subtable for to parse a JSON object
[[inputs.http.json_v2.object]]
# Parse data in `data.stations` path only
path = "data.stations"
#Set station metadata as tags
tags = ["station_id"]
# Latest station information reported at `last_reported`
timestamp_key = "last_reported"
# Time is reported in unix timestamp format
timestamp_format = "unix"测试是否能够解析本地的stations.json
telegraf -test输出下面内容表示.conf文件配置正确
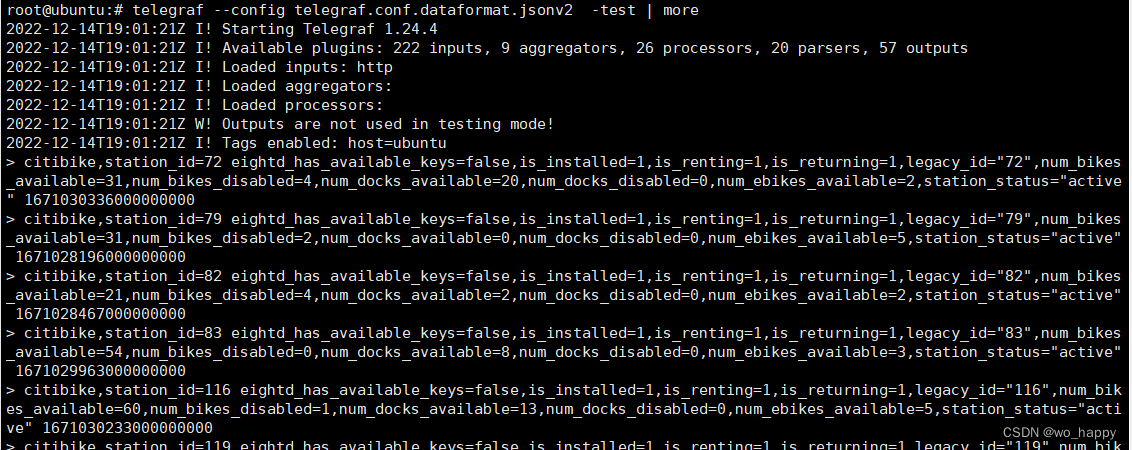
其实不用telegraf,用springboot实现一个server,向Influxdb写入数据好像更加灵活,除了需要连接influxdb数据库,调用Flux Java API接口,需要敲代码。使用telegraf就是零代码编程了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









