







原文:Noun2Verb: Probabilistic Frame Semantics for Word Class ConversionNoun2Verb: Probabilistic Frame Semantics for Word Class Conversion | Computational Linguistics | MIT Press
摘要
人类可以灵活地将词汇用法扩展到不同的语法类别中,这一现象被称为词类转换。名词到动词的转换,或称为来源于名词的动词(例如,“Google一个便宜的航班”),是词类转换的最常见形式。然而,现有的自然语言处理系统在解释和生成新的来源于名词的动词用法上还很不成熟。之前的研究表明,如果听者可以基于与说话者共享的知识计算出预期的意思,那么新的来源于名词的动词用法是可以理解的。在这里,我们探讨了基于框架语义的这一提议的计算形式。我们提出了一个正式的框架,Noun2Verb,该框架通过在语义框架中模拟说话者和听者的共享知识来模拟生成和理解新的来源于名词的动词用法。我们评估了一系列的概率模型,这些模型通过释义学习解释和生成新的来源于名词的动词用法。我们展示了一个模型,在该模型中,说话者和听者合作学习语义框架元素的联合分布,这比现有的最先进的语言模型更好地解释了实证上的来源于名词的动词用法,这些数据来自于(1)现代英语中的成人和儿童语言,(2)现代普通话,以及(3)英语的历史发展。我们的工作将词类转换基于概率框架语义,并在词汇创造性方面弥补了自然语言处理系统与人类之间的差距。
1 简介
词类转换是指一个词在不同的语法类别中的扩展使用,而不改变词形。名词到动词的转换,或来源于名词的动词,是词类转换的最常见形式之一。例如,“Google一个便宜的航班”的表达形式,展示了Google这一创新的动词用法,它通常作为一个名词代表网络搜索引擎或公司。这里的扩展动词使用表示“在线搜索信息”的行为。尽管在成人、儿童以及不同语言中,来源于名词的动词作为词汇语义创新的现象已经在语言学中得到了广泛研究(例如,Clark和Clark 1979; Clark 1982; Vogel和Comrie 2011; Jespersen 2013),但在计算语言学的现有文献中,它们仍然被大大忽视;而它们的灵活性给自然语言理解和生成创新词汇用法带来了关键的挑战。我们在框架语义中提出了名词到动词转换的正式计算解释。我们展示了我们的概率框架如何产生有意义的解释和生成新的来源于名词的动词用法,超越了自然语言处理中的最先进的语言模型。
以前的工作为何名词到动词的转换会发生提供了广泛的实证研究,从语法(Hale和Keyser 1999)、语义(Dirven 1999)和语用学(Clark和Clark 1979)的角度出发。特别是,Clark和Clark (1979)对这一主题进行了最全面的研究,并描述了“创新来源于名词的动词约定”作为一个沟通情境,其中听者可以基于Grice的合作原则(Grice 1975)轻松理解一个新的来源于名词的动词用法的意思。他们建议,一个新的或以前未观察到的来源于名词的动词用法的成功理解依赖于这样一个事实:说话者表示他们相信听者可以基于他们的共同知识轻松和唯一地计算的某种状态、事件或过程。他们用经典的例子“男孩将报纸放在门廊上”(见图1a)来说明这一点。在听到这个包含porch的新的来源于名词的用法的话语时,听者预期会基于话语所引发的实体之间的共享世界知识——男孩、门廊和报纸送货系统,来识别男孩将报纸送到门廊的情境。
与人类语言使用者不同,现有的自然语言处理系统常常无法以有意义的方式解释(或生成)灵活的来源于名词的话语。图1a在两个成熟的自然语言处理系统中揭示了这一问题。在图1a中,一个最先进的BERT语言模型为查询短语“放报纸在门廊上”分配了比更合理的释义“在门廊上放下报纸”更高的概率给两个不适当的释义。在图1b中,Google Translate系统也未能将同一个查询来源于名词的话语从普通话反译成英文。具体来说,该系统误解了来源于名词的动词“放在门廊上”为普通话中的“使困惑”,这导致了错误的反译成英文。这些失败的案例展示了自然语言处理系统在解释灵活的来源于名词的动词用法方面的挑战,它们表明,支持自动化解释和生成新的来源于名词的动词用法的原则性计算方法可能是有必要的。
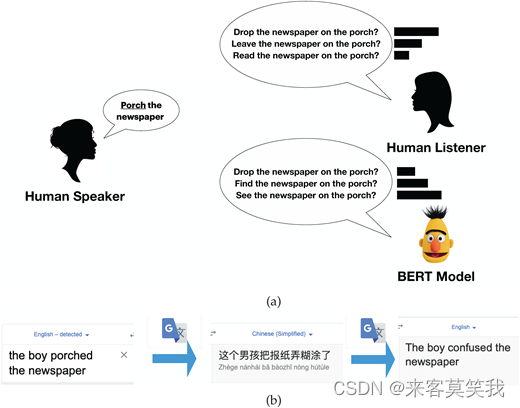
关于名词到动词的转换,或者来源于名词的动词,在人类语言使用者和自然语言处理系统中的问题示例。
(a) 当说话者发出一个新的来源于名词的porch的使用时,听者从上下文中正确地解释了说话者的意图,通过在一组可能的解释或释义中选择最有可能的解释(条形长度表示解释的概率)。相比之下,BERT语言模型为同一个来源于名词的话语分配了更高的概率给不恰当的解释。
(b) Google翻译系统(评估于2021年6月)在将查询来源于名词的话语翻译成普通话时,错误地将to porch the newspaper解释为使报纸困惑,这进一步导致了错误的反译成英语。
这部分内容介绍了认知语言学,特别是框架语义学,如何为解决结构化意义表示问题提供起点。框架语义学的理论主张,人们通过访问一个连贯的心智结构来理解词汇的意义,这个结构包含了百科知识或语义框架。这种框架存储了一系列复杂的事件、实体和场景,以及一组参与者。
这种概念结构也被人工智能、认知心理学和语言学的研究者所讨论,不过使用了不同的术语,如“模式”、“脚本”、“理想化的认知模型”和“质”。在名词到动词的转换的背景下,框架语义学提供了一个原则性的基础,用于描述人们如何解释和产生新的来源于名词的动词用法。
此外,这个部分还讨论了来源于名词的动词用法在现代英语中的普遍性。这种现象不仅仅局限于成人和儿童的不同欧洲语言,还常见于更多的分析型语言,如普通话。历史上,许多来源于名词的动词在其母体名词的既定用法之后出现。例如,根据《牛津英语词典》,advocate这个词在1500s之前一直专门用作名词,但这个词后来获得了动词意义,并迅速流行。
在这项研究中,作者们开发并评估了一个概率框架Noun2Verb,用于建模名词到动词的转换,这一框架建立在框架语义学的传统上。这项工作扩展了之前的研究,该研究提供了一个概率生成方法,用于模拟来源于名词的动词用法的意义,作为一组框架元素。此外,作者使用了一个概率图模型来捕获来源于名词的话语及其底层框架元素之间的依赖关系,并通过一个交际过程最大化三种变量的联合概率。
总的来说,这部分内容深入探讨了名词到动词的转换在框架语义学中的意义和应用,以及如何使用概率框架模型化这种转换。
我们当前的研究扩展了早期的工作,展示了这种概率生成模型如何在现代英语中为新的来源于名词的动词用法提供自动化的解释和生成(Yu, El Sanyoura, 和 Xu 2020)。我们采取框架语义学的方法,并比较了三种增量复杂性的模型,从区分式的基于变压器的模型到完全的生成模型。我们表明,尽管基于变压器的模型在许多自然语言理解任务中都取得了成功(Devlin等人,2018),但它不足以捕捉来源于名词的动词的灵活性,并且在相对稀疏的训练样本中失败地生产性地生成新的来源于名词的用法。我们超越了先前的工作,通过两个额外的数据来源对框架进行了全面的评估:英语名词到动词转换的历史数据和普通话来源于名词的动词用法。此外,我们进行了深入的分析,以解释生成模型的学习成果。
本文的其余部分组织如下。我们首先提供了相关文献的概述。然后,我们提出了我们的计算框架Noun2Verb,并指定了模型评估的预测任务。接下来,我们介绍了我们已经收集并公开供模型学习和评估的数据集。我们描述了三个案例研究,在其中我们严格评估了我们的框架在现代英语、普通话和过去两个世纪的英语历史发展中的广泛数据。最后,我们提供了关于我们框架的优点和局限性的详细解释和讨论,并得出结论。
2 相关工作
2.1 关于词类转换的计算研究
与关于词类转换的大量实证和理论研究相比,很少有研究尝试从计算角度探讨这个问题。现有的一项研究利用了分布式词表示和深度上下文语言模型的最新进展,来研究词类转换的方向性。具体来说,Kisselew等人(2016)构建了一个计算模型,研究了可能解释英语中名词到动词转换和动词到名词转换之间历史顺序的因素。在那项研究中,他们训练了一个逻辑回归模型,使用在名词和动词语境中都有证据的词元的词袋嵌入,来预测哪个词类(在名词和动词类之间)可能在历史上更早出现。他们的结果表明,从名词转化而来的动词通常具有比其母体名词更低的语料库频率,而从动词转化而来的名词往往具有更具语义特异性的语言语境。在一个相关的最近的研究中,Li等人(2020)使用BERT深度上下文语言模型,对37种语言中的词类灵活性进行了计算研究,以量化词类之间的语义转移。他们发现,当灵活的词元(即有多于一个语法类的词元)用于其主导词类时,会有更大的语义变化,支持词类灵活性是一个方向性过程的观点。
与这两项研究都不同,我们在这里关注的是模拟名词到动词转换的过程,而不是关注语言之间词类转换的方向性或类型学。
2.2 框架语义学
我们提出的计算框架基于框架语义学,这在语言学和计算语言学中有着悠久的传统。根据Fillmore、Johnson和Petruck(2003)的说法,一个语义框架可能被一组相关的词汇单位所唤起,这些单位在自然语句中通常实例化为主要的述词动词。词典中的每一个框架也列举了几个角色,对应于由框架表示的情境的各个方面,其中一些角色可以被省略或空实例化,并留下未明确的内容供听者推断(Ruppenhofer和Michaelis 2014)。因此,解释从名词转化的动词用法的问题可以被认为是推断潜在的语义框架的(由其唤起的概念)潜在词汇单位,这本身与语义框架识别(Hermann等人,2014)和语义角色标注(Gildea和Jurafsky 2002)的任务相关。鉴于标注或完全注释数据的有限资源,许多现有的研究已经考虑了一种生成和半监督学习方法,将像FrameNet(Baker、Fillmore和Lowe 1998)和PropBank(Kingsbury和Palmer 2002)这样的标注词汇数据库与其他未标注的语言语料库结合起来。例如,Das等人(2014)提出的SEMAFOR解析器是一个潜在变量模型,它学习最大化FrameNet中标注的语义角色的条件概率,并通过基于图的半监督学习技术(Bengio、Delalleau和Le Roux 2010)支持对未见词汇单位的词汇扩展。在另一项工作中,Thompson、Levy和Manning(2003)使用FrameNet中的标注句子学习一个生成的隐马尔可夫模型,并表明所得到的模型能够在未观察到的言论中推断出空实例化的语义角色(例如,给定句子The ore was boated down the river时推断出“driver”角色是缺失的)。
我们的框架基于这些现有研究,通过将名词到动词的转换制定为潜在语义框架成分的概率推断,我们建议如何一个半监督生成学习方法在解释和生成训练数据中未出现的新的名词化动词用法上提供数据效率和有效的泛化。
2.3 复合词释义的模型
我们的研究也与最近关于复合词理解的研究有关。许多关于复合词理解的问题都需要从语言上下文中推断潜在的语义成分。例如,Nakov和Hearst(2006)建议名词-名词复合词的语义可以被表达为多个介词和动词的释义(例如,apple cake 可以被解释为由苹果制成/含有苹果的蛋糕)。后来的工作开发了监督和无监督的学习方法来解决名词复合词的释义问题(Van de Cruys、Afantenos和Muller 2013;Xavier和de Lima 2014)。特别地,Shwartz和Dagan(2018)提出了一个半监督学习框架,用于推断名词-名词复合词的潜在语义关系。当释义不可用时,缺失的组件被替换为由编码器生成的相应的隐藏表示。Shwartz和Dagan(2018)显示了他们的模型对未观察到的例子的良好泛化能力。我们展示了,由于在分布式语义空间中使用了半监督学习方法,我们的框架在新的名词化语句上泛化得很好,并且进一步地,所提出的框架可以通过生成建模同时学习解释(监听者)和生成(说话者)模型。
2.4 用于自然语言处理的深度生成模型
最近深度生成模型的兴起,导致了几种灵活的语言生成系统的发展,如变分自动编码器(VAEs)(Bowman等人,2016;Bao等人,2019;Fang等人,2019)和生成对抗网络(GANs)(Subramanian等人,2017;Press等人,2017;Lin等人,2017)。我们的Noun2Verb框架基于Kingma等人(2014)提出的半监督VAE的架构,其中解释/听者模块和生成/说话者模块共同学习所有名词化语句及其任何可用释义的概率分布。VAEs的一个优点是它们可以通过其潜在变量编码某些语义信息的方面(例如,写作风格、主题或高级句法特征),并通过祖先采样从学到的隐藏语义空间生成适当的样本。我们在我们的模型分析中显示,我们框架中学到的潜在变量确实捕捉了目标名词化语句及其释义的句法结构和语义框架信息的变化。
2.5 深度情境化语言模型
对于自然语言记号的序列,深度情境化模型为每个记号计算一系列对上下文敏感的嵌入。许多最先进的自然语言处理模型都是基于一个称为Transformer的神经模块的堆叠层构建的(Vaswani等人,2017),如BERT(Devlin等人,2018)、GPT-2(Radford等人,2019)、RoBERTa(Liu等人,2019)和BART(Lewis等人,2020)。这些大型神经网络模型通常是预训练的,其目标是预测给定句子内的上下文信息的缺失记号。然后对这些模型进行微调,利用一系列下游任务的学习示例,包括语言生成任务,如摘要,以及自然语言理解任务,如识别文本蕴涵。当前基于transformer的模型的一个常见问题是,它们的许多成功应用都倾向于依赖于采纳的基准上的大量微调(有时有成千上万的示例)。对于大规模注释的学习示例不可行,或者目标语言数据在标准预训练资源中严重缺乏的任务,transformer模型通常会产生更差的性能(Croce, Castellucci和Basili 2020)。
在我们的工作中,我们考虑使用基于BERT的语言生成模型作为一个有竞争力的基线,并且我们证明这个预训练的语言模型不足以捕捉名词到动词转换的灵活性,特别是当一个名词化语句的真实释义高度不确定时。
3 计算框架
我们将名词到动词的转换形式化为理解和生产的双重问题,并在框架语义学的视角下阐述这一问题。我们提出了三种在关于名词到动词转换的计算机制假设下逐渐增加的概率模型。
3.1 名词到动词的转换作为概率推断
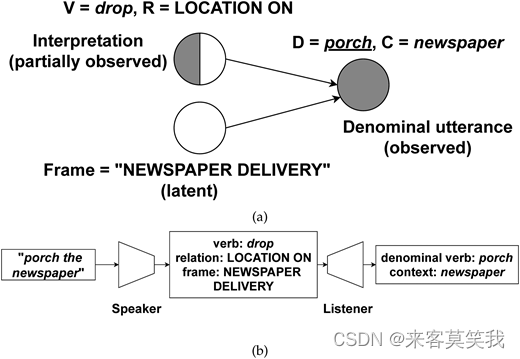
我们将名词到动词的转换视为听者和说话者之间关于包含新的名词化动词用法的话语的沟通。我们的框架重点在于建模知识和动态,这使得(1)一个听者模块能够通过释义正确地解释新的名词化动词用法(或零次推断)的含义,以及(2)一个说话者模块在给定解释后产生新的名词化用法。
图3展示了我们的框架。这里,说话者生成一个话语U = (D,C),它由名词化动词D的创新用法(例如,走廊)和其上下文C组成。作为第一步,我们考虑了一个简单的情况,即C是一个单词,作为D的直接宾语(例如,报纸作为走廊的上下文)。
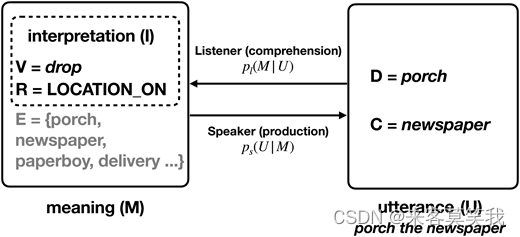
Noun2Verb框架的示意图。说话者根据其生产可能性ps产生一个名词化动词用法的话语。听者通过其理解可能性pl通过释义解释话语的含义。U = (D,C) 是名词化话语,其中D是目标名词化动词,C是其对象上下文;M是U的含义,其中V是释义动词,R是语义关系,E表示一组潜在的框架元素。
考虑到这个话语,听者解释其含义M,我们将其操作化为三个关键组成部分:(1)目标名词动词的一个释义动词V(例如,"drop");(2)按照Clark和Clark (1979)的一个语义关系R,它指定了释义动词和上下文之间的关系(例如,一个on类型的位置,表示报纸被放在阳台上);(3)遵循框架语义学传统的一组框架元素E,我们下面将详细说明。释义动词V是一个已建立的动词,最能描述由名词动词D表示的动作。它作为唤起D的底层语义框架的词汇单元。根据Clark和Clark (1979)的实证研究,语义关系R反映了名词化动词的新意义是如何从其母名词扩展出来的,并系统地分为八种主要类型(参见表1中的摘要)。在每一种关系类型中,都有一组词(其中大部分是介词)表示这种关系,以及这种类型的名词化用法的模板释义。例如,形式为“to <名词化动词> the <上下文>”的名词化用法(例如,“to porch the newspaper”),其中D来自关系类型LOCATION ON,通常可以释义为“to <释义动词> the <上下文> onto/into/to the <名词化动词>”(例如,“to drop the newspaper onto the porch”)。在由V唤起的语义框架下,听者将同时推断目标话语U表示的情境中可能涉及的框架元素E——这种推断不仅捕捉到由名词话语明确指定的参与者,而且捕捉到说话者和听者之间共享的在变量V和R中未被捕捉到的残留的上下文知识。具体来说,"porch the newspaper"可能会唤起一个DELIVERY框架,其中可以确定DELIVERY的元素是报纸,目的地是阳台,并推断出DELIVERER角色的合理选择可以是邮递员或送报员。我们用I = (V,R)表示目标话语U的解释,而我们将框架元素E指定为要由模型推断的潜在变量(即隐性知识)。
表1 Clark和Clark (1979)中描述的解释英语中常见名词化动词用法的主要语义关系类型。每种语义关系都由一组关系词(主要是介词)指定,并有一个句法结构,作为在一种关系类型下释义查询名词化动词用法的模板。
| Relation type | Relational words | Denominal usage | Template paraphrase |
|---|---|---|---|
| LOCATUM ON | on, onto, in, into, to, at | carpet the floor | put the carpet on the floor |
| LOCATUM OUT | out (of), from, of | shell the peanuts | remove the shell from the peanuts |
| LOCATION IN | on, onto, in, into,to, at | porch the newspaper | drop the newspaper on the porch |
| LOCATION OUT | out (of), from, of | mine the gold | dig the gold out of the mine |
| DURATION | during | weekend at the cabin | stay in the cabin during the weekend |
| AGENT | as, like | referee the game | watch the game as a referee |
| GOAL | become, look like,to be, into | orphan the children | make the children become orphans |
| INSTRUMENT | with, by, using,via, through | bike to school | go to school by bike |
我们基于语义关系的构想受到了现有关于名词化动词的跨语言研究的启发。例如,Clark发现表1中的语义关系类型适用于许多由说英语、法语和德语的儿童创造的创新性的名词化用法(Clark 1982)。一个更近期的关于英语和普通话中名词化动词的比较研究也发现,这些主要的语义关系可以解释许多中文的名词化动词用法(Bai 2014)。我们在这里呈现的建模框架可以自动从数据中学习这些语义关系和潜在的框架元素,并且重要的是,它可以推广到解释和生成不同语言和时间跨度上的新颖的名词化用法。
在定义了核心组件之后,我们现在正式将名词转动词看作是两个相关的概率推断问题。听众模块处理理解问题,给定一个话语U,它在理解模型pl(M|U)下抽取适当的释义来解释其意义M = (I,E) = (V,R,E)。说话者模块处理逆生产问题,根据生产模型ps(U|M)给定一个预期的意义M来产生一个(新颖的)名词化用法U。
我们假设,当被模型化为语义框架信息时,互相分享的知识应该是成功沟通创新的名词化用法的关键。为了验证这一观点,我们描述并检查了在我们的Noun2Verb框架下的三个增量概率模型。
3.2 模型类别
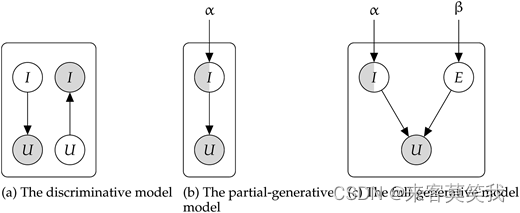
我们提出了三种概率模型(请参见图4的示意图),这些模型对名词转动词的计算机制做了不同的假设。首先,我们描述了一个判别模型,该模型既不假设说话者和听众之间有任何交互动态(即没有协作),也不知道语义框架元素。我们使用自然语言处理中的最先进的上下文化语言模型实现了这个模型。据我们所知,不存在特定和可扩展的名词动词模型,而鉴于上下文语言模型的通用性质,我们认为它是一个强有力的竞争基线模型。接下来,我们描述了一个部分生成模型,该模型通过知识共享实现了听众-说话者的协作,但没有任何语义框架元素的表示。最后,我们描述了一个完整的生成模型,它既包括听众-说话者的协作,也包括语义框架元素。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









