









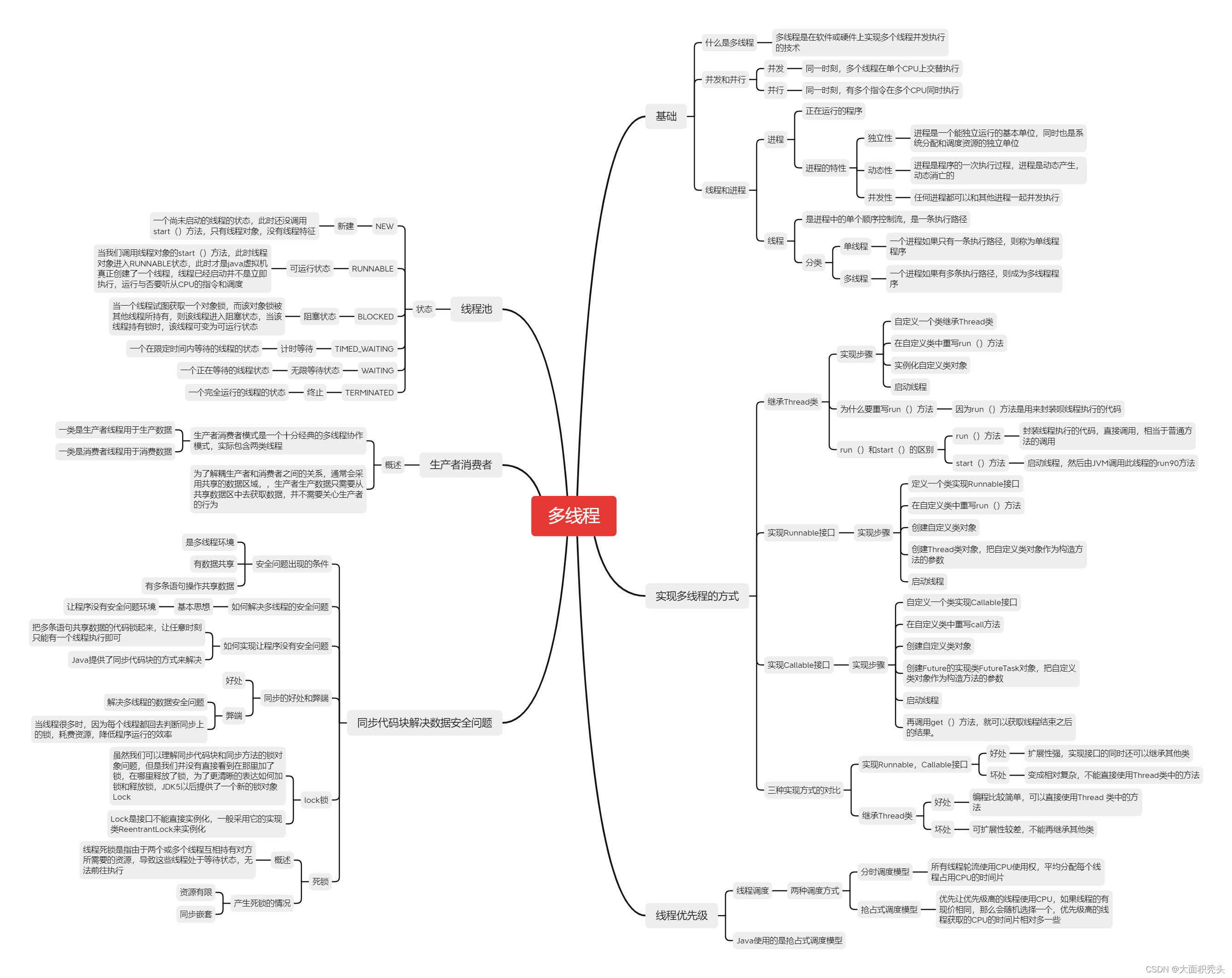
多线程
了解多线程
多线程是指从软件或者硬件上实现多个线程并发执行的技术。
具有多线程能力的计算机因有硬件支持而能够在同一时间执行多个线程,提升性能。
并发和并行
- 并行:在同一时刻,有多个指令在CPU上同时执行
- 并发:在同一时刻,有多个指令在CPU上交替执行
进程和线程
进程:正在运行的软件
- 独立性:进程是一个独立运行的基本单位,同时也是系统分配调度资源的独立单位。
- 动态性:进程的实质就是程序的一次执行过程,动态产生,动态消亡。
- 并发性:任何进程都可以和其他进程并发执行
线程:是进程中单个顺序控制流,是一条执行路径
- 单线程:一个进程如果只有一条执行路径,则称为单线程程序
- 多线程:一个进程如果有多条执行路径,则成为多线程程序
多进程的实现方案
- 继承Thread类的方式进行实现
- 定义一个类继承Thread类
- 在定义的类中重写run()方法
- 创建自定义类的对象
- 启动线程
- 实现Runable接口的方式实现
- 自定义一个类实现Runable接口
- 在自定义类中重写run()方法
- 创建自定义对象
- 创建Tread类对象,把自定义对象作为构造方法的参数
- 启动线程
- 利用Callable和Future接口方式实现
- 定义一个类实现Callable接口
- 在该类中重写call方法
- 创建自定义类的对象
- 创建Future的实现类FutureTask对象,把自定义类对象作为构造方法的参数
- 创建Tread类的对象,把FutureTask对象最为构造方法的参数
- 启动线程
三种方式的对比
| 优点 | 缺点 | |
|---|---|---|
| 实现Runnable,Callable接口 | 扩展性强,实现该接口的同时还可以继承其他类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 可扩展性差,不能继承其他类 |
使用getName()获取当前正在执行现成的名称
使用setName()给当前线程设置名称,也可使用子类的带参构造方法设置名称
使用Thread的Sleep()方法 使得线程睡眠特定的时间
实现Runnable结构创建多线程程序的好处
- 避免了单继承的局限性
- 一个类只能继承一个类,自定义类继承了Thread类就不能继承其他类
- 实现了Runnable接口,还可以继承其他类,实现其它接口
- 增强了程序的扩展性,降低了程序的耦合性
- 实现了Runnable接口的方式,把设置线程任务和开启新线程进行了分离(解耦)
- 实现类中,重写了run方法,用来设置线程任务
- 创建Thread类对象,调用start方法,用来开启新的线程
线程安全问题
解决措施:
使用同步机制解决
方法一:同步代码块
syncheonized(对象){
代码块
}
方法二:同步方法
使用步骤:
- 把访问了共享数据的代码提取出来,放到一个方法中
- 在方法上添加synchronized修饰符
- 格式
修饰符 synchronized 返回值类型 方法名(参数列表){
可能会出现安全问题的代码(访问了共享数据的代码)
}
线程池
线程池可以看成是一个池子,这个池子中存储很多个线程
系统创建一个线程的成本是很高的,因为他涉及到与操作系统的交互,当程序需要创建大量生存期很短暂的线程是,频繁的创建何晓辉线程对系统的资源消耗可能大于业务处理对线程的消耗。为了提高性能,我们可以采用线程池。
线程池在启动时,会创建大量空闲线程,当我们向线程池提价搜任务是,线程池就会启动一个线程来执行该任务。等待任务执行完毕,线程并不会死亡,而是咋次返回到线程池中称为空闲状态,等待哦下一次任务的执行。
线程池的设计思路
- 准备一个任务容器
- 一次性启动多个消费者线程
- 刚开始任务容器是空的,所有线程都在等待
- 知道一个外部线程向这个任务容器扔了一个“任务”,就会有一个消费者线程被唤醒
- 这个消费者线程取出任务,并执行任务,执行完毕后,继续等待下一次任务的到来
线程池-Executors默认线程池
概述:在开发中我们使用JDK中自带的线程池
我们可以使用Excutors中所提供的的静态方法来创建线程池
static ExcutorsService newCachedThreadPool()创建一个默认线程池
static newFixedThreadPool(int nThreads)创建一个指定最多线程数量的线程池
代码实现
ackage practise2.Exam2;
import java.util.concurrent.Executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
//static ExecutorsService new CachedThreadPool() 创建一个默认的线程池
//static newFixedThreadsPool(int nThreads) 创建一个指定最多线程数量的线程池
public class Exam1 {
public static void main(String[] args) {
//创建一个默认线程池对象,池子是空的,默认最多可以容纳int类型的最大值
ExecutorService executorService= Executors.newCachedThreadPool();
//Executors ---可以帮助我们创建线程池对象
//ExecutorService ---可以帮助我们控制线程池
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"在执行了");
});
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"在执行了");
});
executorService.shutdown();
}
}
线程池-Executors创建指定上限的线程池
使用Executors中所提供的静态方法来创建线程池
static ExecutorsService newFixcedThreadPool(int nThread):创建一个指定最多线程数量的线程池
代码实现:
package practise2.Exam2;
import java.util.concurrent.Executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
//static ExecutorService newFixedThreadPool(int nThread):创建一个指定最多线程数量的线程池
public class Exam2 {
public static void main(String[] args) {
//参数不是初始值而是最大值
ExecutorService executorService= Executors.newFixedThreadPool(10);
ThreadPoolExecutor pool= (ThreadPoolExecutor) executorService;
System.out.println(pool.getPoolSize()); //0
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"在执行了");
});
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"在执行了");
});
System.out.println(pool.getPoolSize());//2
//executorService.shutdown();
}
}
线程池-ThreadPoolExecutor
创建线程池对象:
ThreadPoolExecutors threadPoolExecutor =new ThreadPoolExecutor(核心线程数连发,最大线程数量,空闲线程数量,空闲线程最大存活时间,任务队列,创建线程工厂,任务的拒绝策略);
代码实现
package practise2.Exam2;
import pracise1.exam5.MyRunnable;
import java.util.concurrent.*;
public class Exam3 {
public static void main(String[] args) {
//参数一:核心线程数量
//参数二:最大线程数
//参数三:空闲线程最大存活时间
//参数四:时间单位
//参数五:任务队列
//参数六:创建线程工厂
//参数七:人物的拒绝策略
ThreadPoolExecutor pool =new ThreadPoolExecutor(2,5,2, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10), Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
pool.submit(new MyRunnable());
pool.submit(new MyRunnable());
pool.shutdown();
}
}
线程池-参数详解
创建线程池对象
ThreadPoolExecutor threadPoolExecutor =new ThreadPoolExecutor(
核心线程数量,最大线程数量,空闲线程最大存活时间,任务队列,创建线程工厂,任务的拒绝策略
)
| 参数 | 含义 | 限制 |
|---|---|---|
| 参数一 | 核心线程数量 | 不能小于0 |
| 参数二 | 最大线程数 | 不能小于等于0,最大线程数大于等于核心线程数 |
| 参数三 | 空闲线程最大存活空间 | 不能小于0 |
| 参数四 | 时间单位 | 时间单位 |
| 参数五 | 任务队列 | 不能为null |
| 参数六 | 创建线程工厂 | 不能为null |
| 参数七 | 人物的拒绝策略 | 不能为null |
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
corePoolSize: 核心线程的最大值,不能小于0
maximumPoolSize:最大线程数,不能小于等于0,maximumPoolSize >= corePoolSize
keepAliveTime: 空闲线程最大存活时间,不能小于0
unit: 时间单位
workQueue: 任务队列,不能为null
threadFactory: 创建线程工厂,不能为null
handler: 任务的拒绝策略,不能为null
线程池-非默认任务拒绝策略
RejectedExecutionHandler是jdk提供的一个任务拒绝策略接口,他下面存在4个子类。
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。是默认的策略。
ThreadPoolExecutor.DiscardPolicy: 丢弃任务,但是不抛出异常 这是不推荐的做法
ThreadPoolExecutor.DiscardOldestPolicy: 抛弃队列中等待最久的任务 然后把当前任务加入队列中。
ThreadPoolExecutor。CallerRunsPolicy: 调佣任务的run()方法绕过线程池直接执行
注:明确线程池对多可执行的任务数=队列容量+最大线程数
package practise2.Exam2;
import java.util.concurrent.*;
public class Exam {
public static void main(String[] args) {
// ThreadPoolExecutor threadPoolExecutor=new ThreadPoolExecutor(1,3,20,
// TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),
// Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
//提交5个任务,而该线程池最多可以处理4个任务,当我们使用ABortPOlicy这个任务处理策略是后,就会抛出异常
ThreadPoolExecutor threadPoolExecutor=new ThreadPoolExecutor(1,3,20,TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),
Executors.defaultThreadFactory(), new ThreadPoolExecutor.DiscardOldestPolicy());
//提交了5个任务
for (int i = 0; i < 5; i++) {
//定义一个变量,来制定当前执行的任务,这个变量需要被final修饰
final int y=i;
threadPoolExecutor.submit(()->{
//System.out.println(Thread.currentThread().getName()+"------>>执行了任务");
System.out.println(Thread.currentThread().getName()+"---->>执行了任务"+y);
});
}
}
}
package practise2.Exam2;
import java.util.concurrent.*;
public class Exam5 {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor=new ThreadPoolExecutor(
1,3,20, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),
Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy()
);
//提交五个任务
for (int i = 0; i < 5; i++) {
threadPoolExecutor.submit(()->{
System.out.println(Thread.currentThread().getName()+"---->>执行了任务");
});
}
}
}
通过控制台的输出,我们可以看次策略没有通过线程池中得到线程执行任务,而是直接调用任务的run()方法绕过线程池直接执行。
原子性
volatile-问题
代码分析:
volatile解决
以上案例出现的问题:
当A线程修改了共享数据时,B线程没有及时获取道最新的值,如果还在使用原先的值,就会出现问题。
- 堆内存是唯一的,每一个线程都有自己的线程栈
- 每一个线程在使用堆内存里面的变量时,都会先拷贝一份到变量的副本中
- 在线程中,每一次使用是从变量的副本中获取的
volatile关键字:强制线程在每一次使用时,都会看一下公共区域最新的值。
public class Money {
public static volatile int money=100000;
}
public class MyThread1 extends Thread{
@Override
public void run() {
while (Money.money==100000){}
System.out.println("结婚基金已经不是十万了");
}
}
public class MyThread2 extends Thread{
@Override
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
Money.money=90000;
}
}
public class Demo {
public static void main(String[] args) {
MyThread1 myThread1=new MyThread1();
myThread1.setName("小垃圾");
myThread1.start();
MyThread2 myThread2=new MyThread2();
myThread2.setName("小趴菜");
myThread2.start();
}
}
synchronized解决
- 线程获得锁
- 清空变量副本
- 拷贝共享最新的值到变量副本中
- 执行代码
- 将修改后变量副本中的值赋值给共享数据
- 释放锁
代码实现
原子性
概述:在一次操作或者多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行,多个操作是一个不可分割的整体。
Volatile关键字不能保证原子性
解决方案:我们可以给count++操作添加锁,那么count++操作就是临界区中的代码,临界区中的代码一次只能被一个线程去执行,所以count++就变成了的原子操作。
原子性—AtomicInteger
概述:java从JDK1.5开始提供了java.uyil.concurrent.atomic包(简称Atomic包),这个包中的原子提供了一种用法简单,性能高效,线程安全地根新一个变量的方式,因为变量的类型有很多个,所以在Atomic包中一共提供了13个类,属于4种类型的原子更新方式,分别是:
原子更新基本类型,原子更新数组,原子更新引用和原子更行属性(字段)
使用原子的方式甘心基本类型,使用原子的方式更新基本类型Atomic包提供了一下3个类:
AtomicBoolean:原子更新布尔类型
AtomicInteger:原子更新整型
AtomicLong:原子更新长整型
以上三个类提供的方法几乎一模一样,以AtomicInteger为例讲解
public AtomicInteger(); //初始化一个默认值为0的原子型Integer
public AtomicInteger(int initialValue): //初始化一个指定值的原子型Integer
int get(); //获取值
int getAndIncrement(); //以原子的方式将当前值加1,注意,这里返回的是自增前的值
int incrementAndGet(); //以原子的方式将当前值加1,注意,这里返回的是自增前的值
int addAndGet(int data): //以原子的方式将输入的数值与示例中的值(AtomicInteger里的value)相加,并返回结果。
int getandSet(int value): //以原子方式设置为newValur的值,并返回旧值
代码实现:
AtomicInteger-内存解析
AtomicInteger原理:
自旋锁+CAS算法
CAS算法:
有三个操作数(内存值V,旧的预期值A,要修改的值B)
当旧的预期值A==内存值 此时修改成功,将V改为B
当旧的预期值A!=内存值,此时修改失败,不做任何操作
并重新获取现在的最新值(这个重新获取的动作就是自旋)
AtomicInteger-源码解析
代码实现:
源码解析
乐观锁和悲观锁
synchronized和CAS的区别
相同点:
在多线程的情况下,都可以保证共享数据的安全性
不同点:
synchronized总是从最坏的角度出发,认为每次获取数据的时候,别人都有可能修改。所以在每次操作共享数据之前,都会上锁。(悲观锁)
cas是从乐观的角度出发,假设每次获取数据别人都不会修改,所以不会上锁,只不过在修改共享数据的时候,会检查一下。
如果别人修改过,则获取最新数据。
如果别人没有修改过,那么我们直接修改共享数据的值(乐观锁)
并发工具类
并发 工具类-Hashtable
Hashtable出现的原因:
在集合类中HashMap是比较常用的集合类对象,但是HashMap是现成不安全的(多线程环境下可能会存在问题)。为了保证数据得到安全性我们可以使用Hashtable,但是Hashtable的效率低下。
代码实现:
并发工具类-ConcurrentHashMap基本使用
ConcurrentHashMap出现的原因
在集合类中HashMap是比较常用的集合对象,但是hashMap是线程不安全的多线程环境下可能会存在的问题)。为了保证数据的安全性我们可以使用Hashtable,但是Hashtable的效率低下,基于以上两个原因我们可以使用JDK1.5以后提供的ConcurrentHashMap。
体系结构
ConcurrentHashMap
Map接口
- HashMap
- Hashtable
- TreeMap
- ConcurrentMap
总结:
- HashMap是线程不安全的,多线程环境下有数据安全问题
- hashtable 是线程安全的,但是会将整张表锁起来,效率低下‘
- ConcurrentHashMap也是线程安全的,效率高,在JDK7和JDK8中,底层原理不同














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









