







1.Grok插件
该工具可以将非结构话日志解析为结构化和和可查询的日志,基于正则匹配文本,内置了120多种匹配模式,也支持自定义模式匹配。可以解析匹配各种文本格式。
1.内置匹配模式文档
2.使用方法官方文档7.17
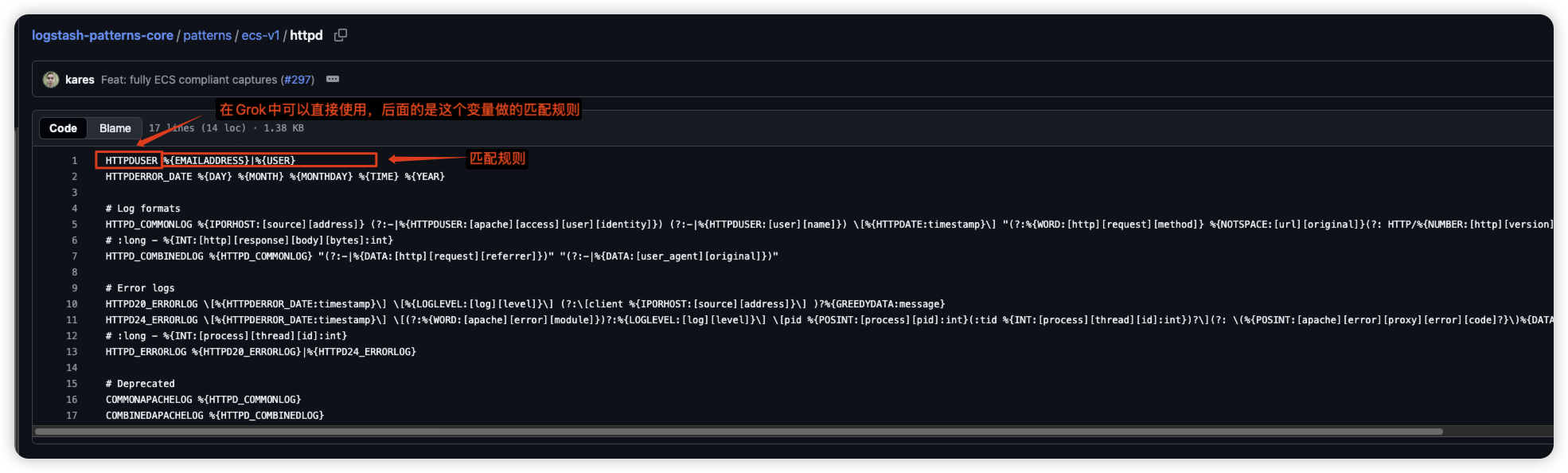
1.1 通过Grok内置规则来对常规nginx日志进行拆分示例
root@ubuntu2204test99:~/elkf/logstash/pipeline# cat logstash.conf
# 通过Grok来对nginx常规日志进行拆分处理
input {
beats {
port => 5044
}
}
# 过滤
filter {
# 通过grok组件来对字段进行正则匹配,引用自带的匹配规则变量%{COMBINEDAPACHELOG}
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
}
output {
stdout {}
elasticsearch {
hosts => ["192.168.1.99:9201","192.168.1.99:9202","192.168.1.99:9203"]
user => "elastic"
password => "123456"
index => "logs-nginx-base-%{+yyyy.MM.dd}"
}
}
# Filebeat采集常规nginx日志
root@ubuntu2204test99:/usr/local/filebeat-7.17.24# cat filebeat-nginx-grok-base.yml
filebeat.inputs:
- type: log
enable: true
tags: ["nginx"]
paths:
- /root/nginx_log/nginx01.log
output.logstash:
hosts: ["192.168.1.99:5044"]
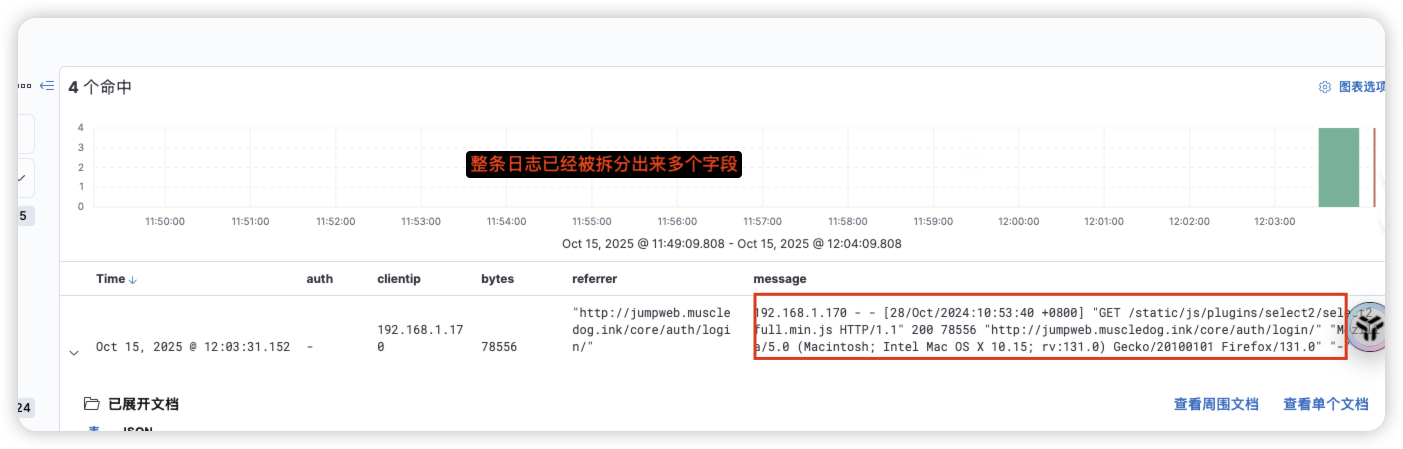
1.2通过Grok自定义规则对日志进行分析(使用自带规则)
grok正则匹配的语法是 %{内置/自定义匹配变量:自定义别名}
日志格式
55.3.244.1 GET /index.html 15824 0.043
使用Grok拆分
# 观察这段日志组成(对应内置变量)
55.3.244.1 --> IP(ip地址)
GET --> WORD(文档)
/index.html --> URIPATHPARAM(请求)
15824 --> NUMBER(数字)
0.043 --> NUMBER(数字)
# 拆分的正则为(要匹配到你的日志,空格等也需要匹配)
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
在logstash的过滤配置
input {
file {
path => "/var/log/http.log"
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
输出样式会得到如下结果
client: 55.3.244.1method: GETrequest: /index.htmlbytes: 15824duration: 0.043
1.3通过Grok自定义规则对日志进行分析(自定义)
- 方法1:通过Oniguruma语法去捕捉匹配日志中的一段文字进行保存
- 语法 (?<字段名>匹配条件)
- 示例 (?[0-9A-F]{10,11})
- 方法2:创建一个文件夹,然后创建规则文件
- 前提 创建文件夹并编写规则文件(比如创建文件夹patterns并创建规则文件postfix)
- 规则文件语法 POSTFIX_QUEUEID [0-9A-F]{10,11}
- Grok中通过patterns_dir参数指定规则文件位置 grok { patterns_dir => ["./patterns"] }
官方示例:
创建规则和编写规则文件
# contents of ./patterns/postfix: 抓取
POSTFIX_QUEUEID [0-9A-F]{10,11}
日志格式
**Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>**
grok过滤规则
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
输出结果
timestamp: Jan 1 06:25:43logsource: mailserver14program: postfix/cleanuppid: 21403queue_id: BEF25A72965 通过正则就将需要的字段抓取并命名syslog_message: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
2.Grok通用选项
2.1 remove_field 移除指定字段
# 移除单个字段
filter {
grok {
...
remove_field => [ "ecs" ]
}
}
# 移除多个字段
filter {
grok {
.....
remove_field => [ "ecs", "agent" ]
}
}
2.2 add_field 添加指定字段
# 添加单个字段
filter {
grok {
add_field => { "host_field" => "Hello world, from %{host}" }
}
}
# 添加多个字段
filter {
grok {
add_field => {
"host_field_one" => "Hello world, from %{host}"
"new_field" => "new_static_value"
}
}
}
2.3 remove_tag 移除指定字段
# 删除单个tag
filter {
grok {
remove_tag => [ "foo_%{somefield}" ]
}
}
# 删除多个tag
filter {
grok {
remove_tag => [ "foo_%{somefield}", "sad_unwanted_tag"]
}
}
2.4 add_tag 添加指定字段
# 添加单个tag
filter {
grok {
add_tag => [ "foo_%{somefield}" ]
}
}
# 添加多个tag
filter {
grok {
add_tag => [ "foo_%{somefield}", "taggedy_tag"]
}
}

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









