






1.问题模型:
1.1回归问题(Regression):
eg:房价预测,温度预测;
1.2分类(Classification):
eg:邮件分类,输入图片输出预测;
2.问题求解

2.1建立模型
一般根据domain knowledge建立模型,例如y=w*x+b,x为输入,y为输出,w和b为参数,w为weight,b为bias。domain knowledge是先验知识即部分已有的知识。
2.2定义损失函数
MAEloss/MSEloss/Cross-entropy:

2.3优化参数
优化的目标是找到使L最小的参数,即找到使得loss最小的参数w和b
优化方法:梯度下降(gradient descend)
先进行参数的随机初始化,求出梯度,进行参数更新。

其中为learning rate,其大小控制学习速率,为一个hyperparameters(超参数是需要自己所设定的参数)
可能存在local minima问题。
2.4 测试
对test集运用模型进行测试,观察效果。
由于根据domain knowledge得出的模型可能不准确,即存在model bias,这时需要将线性模型转变为神经网络。一个曲线可以用多个sigmoid组合而成,如图

sigmoid函数如下:

sigmoid函数参数:
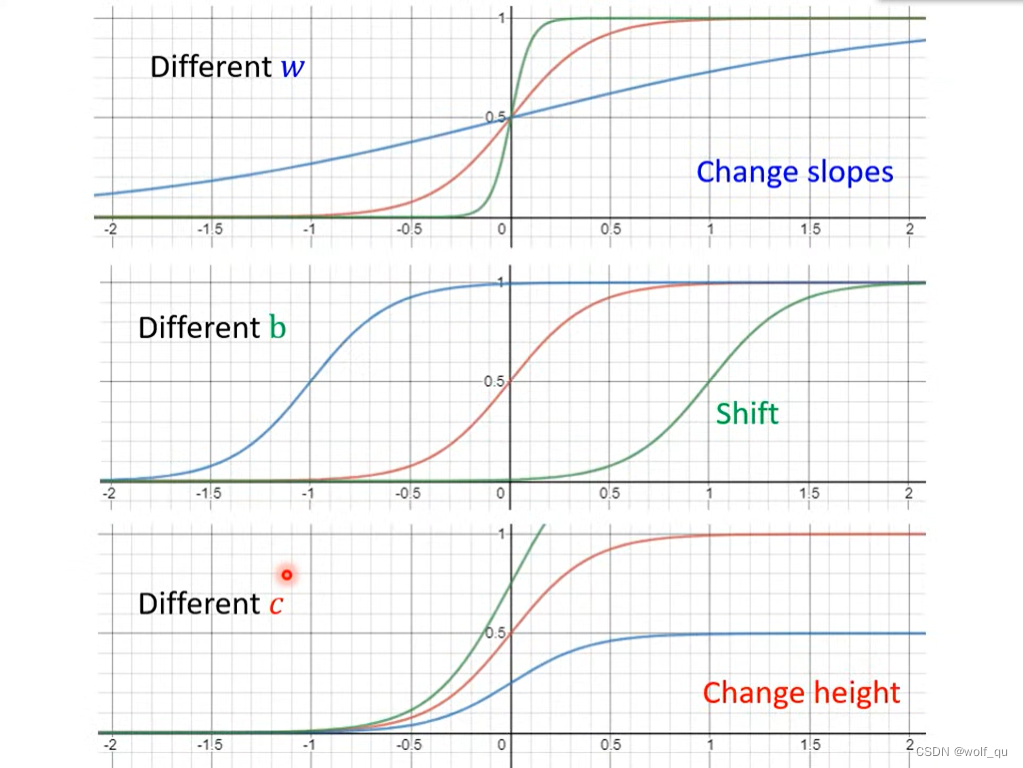
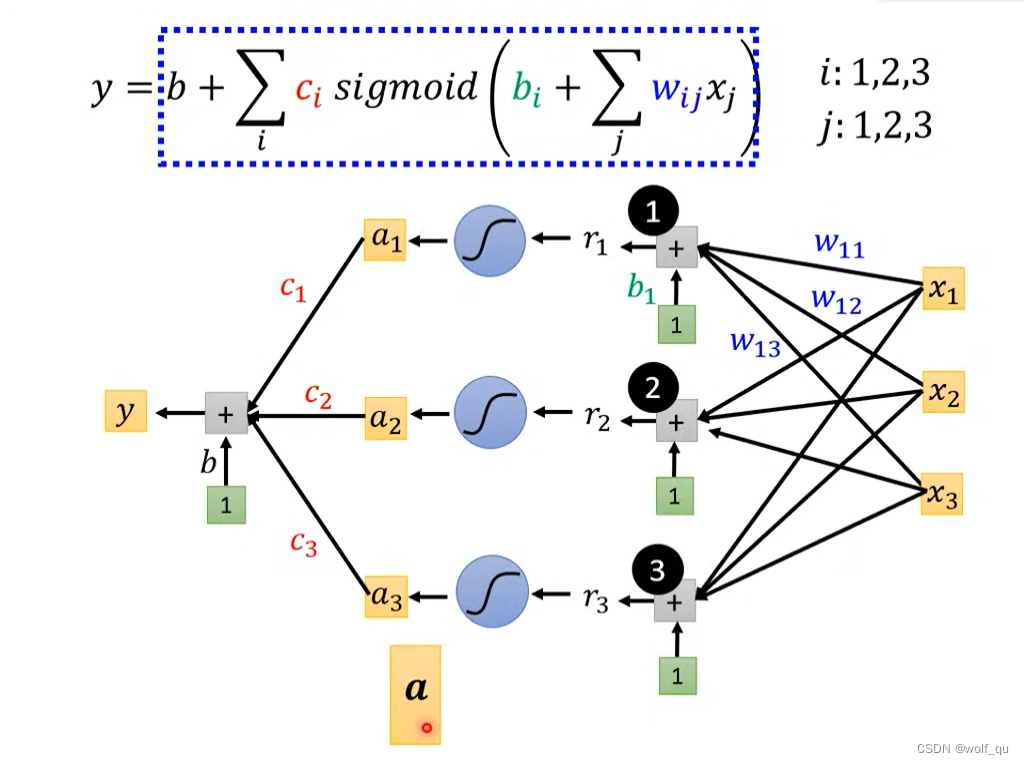
最后得出的模型为:

此时引入了更多的参数,进行运算时可以进行向量化转化为矩阵运算。注意这个sigmoid的数目是可以自己定的(就是神经网络里的神经元的数目是可以自己定的),而且sigmoid越多,可以产生出的piecewise linear function就越复杂(可以产生和sigmoid一样多的线段)。
也可以用RELU函数替换sigmod函数,一个sigmod函数需要替换为两个RELU函数,且通常用RELU而不用sigmod。RELU函数如下:
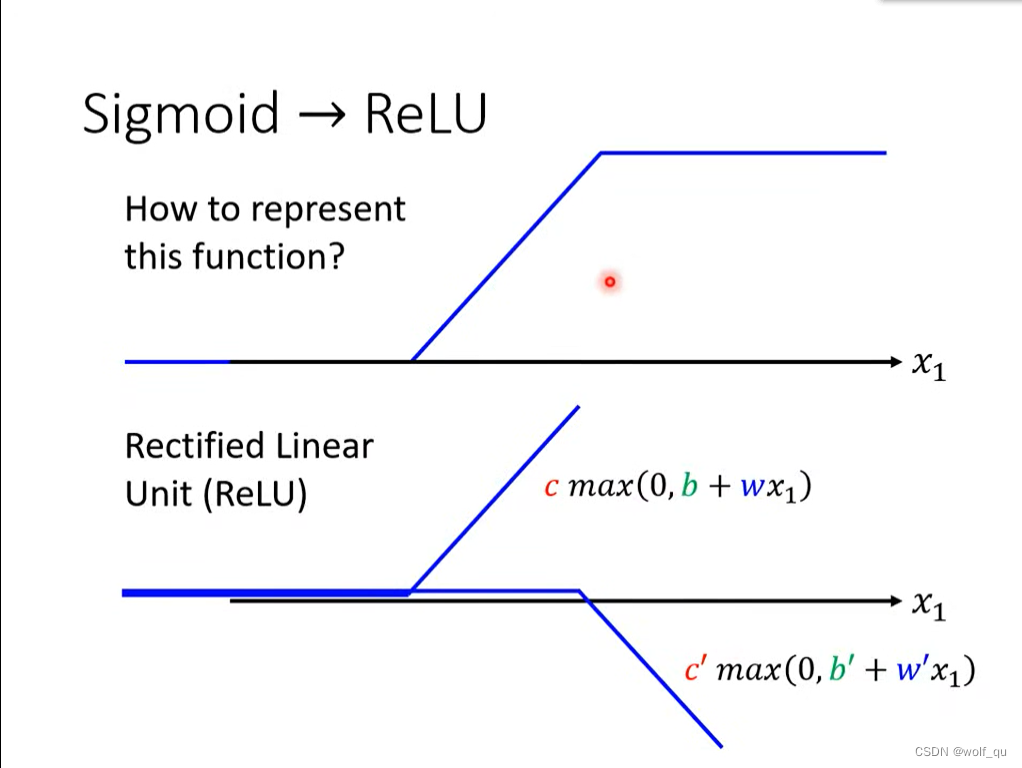 Sigmoid函数和RELU函数均为activation function
Sigmoid函数和RELU函数均为activation function
模型更新后,模型的loss为

进行优化参数时所有参数都需要更新

在实际运行中,不会一次运行所有数据,而会用batch:将整个数据分成很多batch,每次运行一个batch,update一次参数;将所有batch运行完一次,是为一个epoch。

超参数(hyperparameter):模型中需要自己手动设置的参数,例如batchsize,learning rate等















 5409
5409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









