







(一),基于Spark Shell的worldcount程序
1.启动spark
首先进入/usr/local/spark/bin目录,执行spark-shell 启动spark
便成功进入Spark Shell提供以Scala和Python语言为接口的交互式Spark编程环境。
![]()

2.创建example.txt文件
新打开一个终端,进入/home/hadoop
创建一个example文件,并输入内容。


3.在交互式面板依次输入并执行程序
val textFile = sc.textFile("file:///home/hadoop/example.txt")(找到文件)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)(转换操作,将文本每行按“ ”分开成一个个单词,再整合到一起,之后将单词变为(word,1)形式,在按照key值合并value )
wordCount.collect()(动作操作,执行转换操作并输出结果)

(二),scala语言
1,基本数据类型


2.Scala语言的类和对象




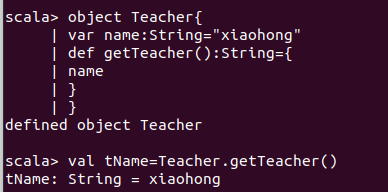
定义一个单例对象
3.Scala语言的函数

Scala中的匿名函数:lambda表达式
(参数) => {表达式}

通过lambda表达式定义一个函数变量
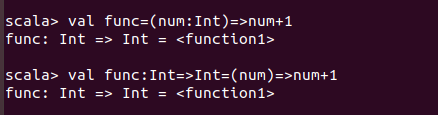
Scala中的高阶函数

Scala函数中的占位符

4.Scala语言的数组
定长数组:

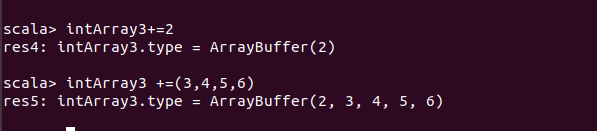
变长数组:

5.Scala语言的列表


6.Scala语言的集合

- Scala语言的元组

- Scala语言的映射


- Scala语言的控制结构
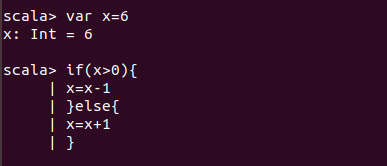
If语句
While语句

for语句



















 328
328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











