







{{TOC}}
第 10 章 容器:数组(下)
我们在上一章讨论了数组的表示法、构造方法,以及存取其中元素值的各种方式。对于一般的应用场景来说,我觉得这些内容应该是足够的。但是,我们还应该了解更多,尤其是那些可以提高我们的编码效率的知识。
下面,我们就来介绍几个比较重要的专题。我会先接续上一章的内容,从修改数组的方式讲起。
10.1 广播式的修改
视图为我们改动数组中的元素值提供了一个很好的途径。不过,在真正改动的时候,我们仍然需要通过索引去定位元素值,并且需要分别修改每一个元素值或者告知每一个元素的新值。当改动量较大的时候,这种方式就显得很繁琐了。
为了减少我们的代码量,Julia 提供了一种名为广播(broadcast)的操作方式。这一操作的首要代表就是broadcast函数。该函数可以批量地操作某个数组复本中的所有元素值。示例如下:
julia> operand1 = copy(array2d)
5×6 Array{Int64,2}:
1 6 11 16 21 26
2 7 12 17 22 27
3 8 13 18 23 28
4 9 14 19 24 29
5 10 15 20 25 30
julia> broadcast(*, operand1, 10)
5×6 Array{Int64,2}:
10 60 110 160 210 260
20 70 120 170 220 270
30 80 130 180 230 280
40 90 140 190 240 290
50 100 150 200 250 300
julia>
在这里,broadcast函数调用的含义是,让数组operand1的复本中的每一个元素值都与10相乘,并返回该复本。
这个函数的第一个参数值(或称操作值)的含义,不但取决于它本身,还取决于后续的参数值(或称被操作值)。比如,在下面的调用中,操作符-会让数组中的所有元素值都变成相应的负数:
julia> broadcast(-, operand1)
5×6 Array{Int64,2}:
-1 -6 -11 -16 -21 -26
-2 -7 -12 -17 -22 -27
-3 -8 -13 -18 -23 -28
-4 -9 -14 -19 -24 -29
-5 -10 -15 -20 -25 -30
julia>
而像下面这样做则可以让一个数组中的元素值都被减去10:
julia> broadcast(-, operand1, 10)
5×6 Array{Int64,2}:
-9 -4 1 6 11 16
-8 -3 2 7 12 17
-7 -2 3 8 13 18
-6 -1 4 9 14 19
-5 0 5 10 15 20
julia>
另外,操作值不仅可以是一个操作符,还可以是一个普通的函数或者构造函数。例如:
julia> broadcast(isodd, operand1)
5×6 BitArray{2}:
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
julia> broadcast(Int, ans)
5×6 Array{Int64,2}:
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
julia>
上面的第一个调用表达式会分别判断数组operand1中的每一个元素值是否为奇数,并用一个具有相同尺寸的数组承载这些判断的结果。更确切地说,它用来承载判断结果的是一个位数组。而第二个调用表达式则会基于这个位数组生成一个元素类型为Int的新数组,并返回后者。
你应该已经看出来了,broadcast函数中的被操作值可以是数组这样的容器,也可以是像整数这样的标量。或者说,被该函数的第一个参数值所操作的值可以是容器或标量。虽然没有什么优势,但是像下面这样做也是可以的:
julia> broadcast(+, 5, -10)
-5
julia>
显然,鉴于broadcast函数的功能特点,我们应该让被操作值中至少有一个是数组或元组。当然了,所有的被操作值都是数组也是可以的。就像这样:
julia> operand2 = [2, 4, 6, 8, 10];
julia> broadcast(+, operand1, operand2)
5×6 Array{Int64,2}:
3 8 13 18 23 28
6 11 16 21 26 31
9 14 19 24 29 34
12 17 22 27 32 37
15 20 25 30 35 40
julia>
让我来解释一下这个广播操作。先看两个被操作值,第一个被操作值operand1是一个 5 行 6 列的二维数组,而第二个被操作值operand2则是一个列向量。它们的维数是不同的,但它们在第一个维度上的长度是相同的,都是5。此操作的含义是,把两个数组中的所有对应位置上的元素值分别相加,并以此生成一个新的数组。可是,这两个数组的维数都不同,又怎么相加呢?
在这种情况下,broadcast函数会先对operand2进行扩展,使它的维数和尺寸都都与operand1一致。更确切地说,由于operand2比operand1少了一个维度,因此需要进行扩展。
在这里,扩展的具体方式是,把operand2再复制出 5 份,并将它们横向地拼接在一起,共同组成一个 5 行 6 列的二维数组。然后,让这个拼接而成的数组成为新的第二个被操作值。下面是示意代码:
julia> operand2_ext = [operand2 operand2 operand2 operand2 operand2 operand2]
5×6 Array{Int64,2}:
2 2 2 2 2 2
4 4 4 4 4 4
6 6 6 6 6 6
8 8 8 8 8 8
10 10 10 10 10 10
julia> broadcast(+, operand1, operand2_ext)
5×6 Array{Int64,2}:
3 8 13 18 23 28
6 11 16 21 26 31
9 14 19 24 29 34
12 17 22 27 32 37
15 20 25 30 35 40
julia>
一定要注意,虽然这些数组的维数可以不同,但是它们在对应维度上的长度都必须相同。因为只要有一个对应的长度不同,broadcast函数就无法确定数组扩展的具体方式,从而导致广播操作无法进行,并抛出一个DimensionMismatch类型的错误。例如:
julia> broadcast(+, zeros(Int, 5, 3), ones(Int, 5, 2, 3))
ERROR: DimensionMismatch("arrays could not be broadcast to a common size")
# 省略了一些回显的内容。
julia>
下面,我们来讲一个可以表达广播操作的语法——点语法(dot syntax)。
所谓的点语法,就是把英文点号.放在我们要使用的操作符之前(或要调用的函数之后),使得此操作(或此函数)可以逐个地施加在被操作值中的每一个元素值之上,并以此达到广播操作的目的。例如:
julia> operand1 .* 10
5×6 Array{Int64,2}:
10 60 110 160 210 260
20 70 120 170 220 270
30 80 130 180 230 280
40 90 140 190 240 290
50 100 150 200 250 300
julia> .- operand1
5×6 Array{Int64,2}:
-1 -6 -11 -16 -21 -26
-2 -7 -12 -17 -22 -27
-3 -8 -13 -18 -23 -28
-4 -9 -14 -19 -24 -29
-5 -10 -15 -20 -25 -30
julia> isodd.(operand1)
5×6 BitArray{2}:
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
julia> Int.(ans)
5×6 Array{Int64,2}:
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
0 1 0 1 0 1
1 0 1 0 1 0
julia>
注意,当点语法作用于操作符时,英文点号要与操作符紧挨在一起。而当点语法作用于函数调用时,英文点号则要写在函数名称和包裹参数值列表的圆括号之间。另外,与broadcast函数一样,点语法改动的也只是被操作值的复本,而不是其本身。
broadcast还有一个孪生函数,名为broadcast!。与前者不同,后者中的第三个参数值才是第一个被操作值。它的第二个参数值专用于存储广播操作的结果。我们可以称之为目的(destination)值。不过,broadcast!函数仍然会返回操作的结果值。特别提示一下,我们一定不要搞混这两种参数值。当一个值确实需要既充当目的值又充当被操作值的时候,我们一定要多一份谨慎。
最后,顺便说一下,虽然点语法看上去更加方便,但当被操作值的数量多于两个的时候,我们就不得不重复写入多个操作符了,如:
julia> operand1 .+ operand2 .+ 10 .+ 100 .+ 1000
5×6 Array{Int64,2}:
1113 1118 1123 1128 1133 1138
1116 1121 1126 1131 1136 1141
1119 1124 1129 1134 1139 1144
1122 1127 1132 1137 1142 1147
1125 1130 1135 1140 1145 1150
julia>
这个时候,broadcast函数的优势就得以显现了:
julia> broadcast(+, operand1, operand2, 10, 100, 1000)
5×6 Array{Int64,2}:
1113 1118 1123 1128 1133 1138
1116 1121 1126 1131 1136 1141
1119 1124 1129 1134 1139 1144
1122 1127 1132 1137 1142 1147
1125 1130 1135 1140 1145 1150
julia>
这种优势并不在于更少的代码量,而在于更少的重复代码。重复的代码越少,我们犯错的概率也就越小。
10.2 元素值的排序
排序的一个重要的前提条件是,数组中的所有元素值之间都是可比较的。在 Julia 中,我们最常用的排序函数莫过于sort和issorted。前者会对一个数组的复本中的所有元素值进行排序,并返回这个已排序的复本。而后者用于判断一个数组是否已经是有序的。
在默认情况下,sort函数会使用快速排序算法以整体升序的方式(或者说以元素值整体由小到大的顺序)对数组进行排序。并且,它只能排序一维数组中的元素值。例如:
julia> vector_int = [115, 65, 18, 2, 117, -102, 123, 66, -93, -102];
julia> sort(vector_int)
10-element Array{Int64,1}:
-102
-102
-93
2
⋮
115
117
123
julia>
然而,这个函数的行为也是可定制的。进一步讲,通过为该函数的关键字参数进行赋值,我们就可以设定排序过程的一些细节。sort函数共有 6 个关键字参数,分别名为dims、alg、lt、by、rev和order。我们下面就来对它们逐一说明。
首先要讲的是参数dims。这个参数的值用于确定哪一个维度中的元素值将会被排序。它的值只能是一个代表了某个有效维度的正整数。下面是相关的例子:
julia> array2d_bool = Bool[0 0 1 0 0 1; 1 0 1 0 0 0; 0 0 0 1 0 0; 1 0 0 0 1 1; 0 1 0 1 0 0]
5×6 Array{Bool,2}:
0 0 1 0 0 1
1 0 1 0 0 0
0 0 0 1 0 0
1 0 0 0 1 1
0 1 0 1 0 0
julia> sort(array2d_bool, dims=1)
5×6 Array{Bool,2}:
0 0 0 0 0 0
0 0 0 0 0 0
0 0 0 0 0 0
1 0 1 1 0 1
1 1 1 1 1 1
julia> sort(array2d_bool, dims=2)
5×6 Array{Bool,2}:
0 0 0 0 1 1
0 0 0 0 1 1
0 0 0 0 0 1
0 0 0 1 1 1
0 0 0 0 1 1
julia>
我们可以看到,我们在对array2d_bool排序的时候,若dims=1,则它的每一列中的元素值就都会被分别排序。而若dims=2,则它的每一行中的元素值就都会被分别排序。倘若这时我们不为dims参数赋值,那么就会立即引发一个错误。比如:
julia> sort(array2d_bool)
ERROR: UndefKeywordError: keyword argument dims not assigned
# 省略了一些回显的内容。
julia>
其原因是,array2d_bool是一个多维数组,而sort函数只能对一维数组中的元素值进行排序。所以,要让它在多维数组的某一个维度上排序是没有问题的,但要让它排序多个维度上的所有元素值,就超出了它的能力范围。
另外还要注意,当sort函数对一维数组排序时,dims参数就不应该被赋值了,否则照样会引发一个错误,如:
julia> sort(vector_int, dims=1)
ERROR: MethodError: no method matching sort!(::Array{Int64,1}; dims=1)
# 省略了一些回显的内容。
julia>
你也许会有个疑问,错误信息中的sort!是什么?它其实是sort函数内部使用的一个函数。我们也可以直接调用它,不过我稍后再讲。
现在来说alg参数。这个参数的名称是 algorithm 的缩写,代表排序算法。Julia 为它预定义的可选值有InsertionSort(插入排序)、QuickSort(快速排序)、PartialQuickSort(局部快速排序)和MergeSort(归并排序)。这 4 个标识符各代表了一个常量,它们都被定义在了Base.Sort模块中。alg参数的默认值是QuickSort。
至于这几种排序算法孰优孰略,我就不多说了。它们都是很有知名度的算法。几乎所有的算法教程中都会对它们有所介绍。不过要注意,如果我们通过dims参数指定的那个维度的长度不大于 20,那么 Julia 就会自动地把排序算法替换为InsertionSort。这主要是因为在小数组上做插入排序会更快一些,而且它的空间复杂度也更低。
参数lt代表的是,比较两个元素值的函数。lt是 less than 的缩写。因此,这个函数的功能就应该是判断它接受的第一个参数值是否小于第二个参数值。该参数的默认值是isless函数。
lt参数虽然不能左右排序的算法,但是却能决定排序当中一个非常重要的细节——怎样比较各个元素值。请考虑下面的数组:
julia> vector_tuple = [(115, 65), (18, 2), (117, -102), (123, 66), (-93, -102)]
5-element Array{Tuple{Int64,Int64},1}:
(115, 65)
(18, 2)
(117, -102)
(123, 66)
(-93, -102)
julia>
数组vector_tuple中的每个元素值都是一个包含了两个整数值的元组。这些元组其实就是利用vector_int数组中的元素值两两组合而成的。这倒是没有什么特殊的含义,只是为了方便你做对比罢了。
在默认情况下,sort函数会怎样对vector_tuple数组的复本做排序呢?在比较其中的两个元组时,它会先对两者中的第一个元素值进行比较。若不同则比较完成,否则会再比较第二个元素值。倘若这两个元组完全相同,那么它们是否需要被交换就要看用的是哪一种排序算法了。示例如下:
julia> sort(vector_tuple)
5-element Array{Tuple{Int64,Int64},1}:
(-93, -102)
(18, 2)
(115, 65)
(117, -102)
(123, 66)
julia>
现在,我们来自定义上述的比较过程。我们想让sort函数先去比较两个元组中的第二个元素值,然后如有必要再去比较两者中的第一个元素值。为此,我们需要先编写一个比较函数。如果这个函数不需要被复用的话,我们就可以用一种简单的方式来编写,就像这样:
(i,j) -> reverse(i) < reverse(j)
这个简单的函数没有名字,所以它是一个匿名函数。它的定义其实只有两个部分。第一个部分是,在符号->左边的参数列表。这里有两个参数,即:i和j。第二个部分是,在符号->右边的函数体。函数体可以产生一个或多个结果值。不过,上例中的函数体,即表达式reverse(i) < reverse(j),只会产生一个结果值。顺便说一句,reverse函数会把其参数值中的所有元素值完全颠倒并返回新的值,如:调用表达式reverse((-93, -102))的结果值会是(-102, -93)。
好了,我们现在可以用这个自定义的比较函数来调用sort函数了。代码如下:
julia> sort(vector_tuple, lt=(i,j)->reverse(i)<reverse(j))
5-element Array{Tuple{Int64,Int64},1}:
(-93, -102)
(117, -102)
(18, 2)
(115, 65)
(123, 66)
julia>
这种自定义的方式其实是很灵活的。因为当我们编写的函数拿到两个元素值的时候,基本上可以对它们的比较过程做出任意的干预。所以,不论你想自己制定什么样的比较规则,为lt参数赋予适当的值通常都可以达到目的。
不过,如果你只想在做比较之前对相关的元素值进行预处理,而在比较它们的时候依然使用默认的isless函数的话,那么只为参数by赋值就可以了。
参数by的值也应该是一个函数。这个函数可以决定的是,数组中的各个元素值将会以哪一种形态参与比较。这种形态可能只代表了元素值中的一部分(如只提取元组中的第二个元素值),也可能是元素值的某一种转换形式(如完全颠倒元组中的所有元素值)。这个参数的默认值是identity函数,意味着数组中的各个元素值会以原本的形态来参与比较。
下面是一些示例:
julia> sort(vector_tuple, by=(e)->e[2])
5-element Array{Tuple{Int64,Int64},1}:
(117, -102)
(-93, -102)
(18, 2)
(115, 65)
(123, 66)
julia> sort(vector_tuple, by=(e)->reverse(e))
5-element Array{Tuple{Int64,Int64},1}:
(-93, -102)
(117, -102)
(18, 2)
(115, 65)
(123, 66)
julia> sort(vector_tuple, by=(e)->sum(abs,e))
5-element Array{Tuple{Int64,Int64},1}:
(18, 2)
(115, 65)
(123, 66)
(-93, -102)
(117, -102)
julia>
可以看到,即使我们只为by参数赋值,也足以颠覆排序的结果了。所以说,这个参数在sort函数中的地位仅次于lt参数。
下一个参数的名称rev是 reverse 的缩写。这个参数的值可以决定是否反转数组中两个元素值的比较结果。无论sort函数使用的是默认的比较规则还是我们利用lt和by自定义的比较规则,它的作用都会是如此。
参数rev的值可以是nothing也可以是一个布尔值,而且其默认值是前者。在这里,默认值nothing与false的效果是一样的,即:不反转比较结果。之所以该参数的可选值中有nothing,只是因为sort函数的底层实现需要如此。而当rev的值为true时,sort函数中的所有比较两个元素值的结果都会被反转,从而导致对数组的排序结果也会被完全反转。比如,在默认情况下,若rev=true则意味着sort函数会以整体降序的方式(或者说以元素值整体由大到小的顺序)对数组进行排序。
参数order的类型是Base.Order.Ordering。Julia 为它预定义的可选值有Base.Order.Forward和Base.Order.Reverse。前者是它的默认值。从这些名称上看,order与rev的作用好像很相似,而事实也确实如此。该参数同样可以决定是否反转两个元素值的比较结果。但不同的是,仅当lt参数和by参数的值都为默认值时,order参数的值才会发挥作用。另外,如果同时设置了rev=true和order=Base.Order.Reverse,且两者都有效,那么它们就会相互抵消掉,如同它们的值都依然为默认值一样。
以上,就是对sort函数的调用方式的完整说明。只要你搞懂了它,那么issorted函数也就容易理解了。
对于任何的可迭代对象而言,issorted函数都有两个衍生方法可用。其中的一个衍生方法只有两个必选的参数,即:代表可迭代对象的itr和Base.Order.Ordering类型的order。后者可以是Base.Order.Forward,也可以是Base.Order.Reverse。它们分别代表着整体升序和整体降序。
这个衍生方法调用起来也很简单,例如:
julia> issorted(sort(vector_int), order=Base.Order.Forward)
true
julia> issorted(sort(vector_int), order=Base.Order.Reverse)
false
julia>
一旦被调用,该衍生方法就会沿着可迭代对象itr的线性索引号检查所有相邻的元素值,并判断它们是否都符合order所描述的比较规则。如果结果是肯定的,那么该方法就会返回true。但只要有一对相邻的元素值不符合规则,它就会返回false。
issorted函数的另一个衍生方法其实是基于上述方法的。只不过它可以让我们更加精细地描述比较的规则。该方法除了必选的参数itr之外,还有 4 个可选的关键字参数,即:lt、by、rev和order。这 4 个可选参数不但在含义上与sort函数中的同名参数一致,而且它们的默认值也与之相同。由于这个衍生方法只有一个必选的参数,所以当我们只向issorted函数传入一个参数值的时候,调用的就是该方法。
下面我再来介绍几个相关的函数。首先要说的是sort!函数,因为它正是sort函数在底层使用的排序函数。不知道你是否还记得名称以!结尾的函数意味着什么?这样的函数往往会修改我们传给它的那个最主要的参数值。
sort!函数的衍生方法有不少。其中的一个方法的参数列表与sort函数的参数列表几乎完全相同。只不过,前者的alg参数的默认值并不总是QuickSort。更详细地说,仅当该方法要排序的数组中只存在数值(以及missing)的情况下,alg的默认值才会是QuickSort,否则其默认值就会是MergeSort。下面,我们就通过调用这个衍生方法来感受一下sort!函数与sort函数在行为上的不同。代码如下:
julia> vector_temp = [115, 65, 18, 2, 117, -102, 123, 66];
julia> sort(vector_temp)
8-element Array{Int64,1}:
-102
2
18
65
66
115
117
123
julia> vector_temp
8-element Array{Int64,1}:
115
65
18
2
117
-102
123
66
julia> sort!(vector_temp)
8-element Array{Int64,1}:
-102
2
18
65
66
115
117
123
julia> vector_temp
8-element Array{Int64,1}:
-102
2
18
65
66
115
117
123
julia>
结果已经摆在这里了,我就不再描述了。你需要记住的是,在 Julia 中,由于数组总会以共享的方式被传递(passed by sharing),所以函数对数组的修改总是对外可见的。更明确地说,像sort!这样的函数修改的总是原数组。
我要介绍的第二个相关函数是sortperm。这个函数也很有特点。它返回的不是已经排好序的数组复本,而是经过排序之后的所有元素值的索引号。这些索引号会被该函数组织成一个一维数组,以便将它们一起返回。而且,它们在这个一维数组中的位置很可能会与之前不同。
请看下面的代码:
julia> show(vector_int)
[115, 65, 18, 2, 117, -102, 123, 66, -93, -102]
julia> ord_nums = sortperm(vector_int); show(ord_nums)
[6, 10, 9, 4, 3, 2, 8, 1, 5, 7]
julia> ordered_vector_int = vector_int[ord_nums]; show(y_vector_int)
[-102, -102, -93, 2, 18, 65, 66, 115, 117, 123]
julia> ordered_vector_int == sort(vector_int)
true
julia>
为了方便对比,我在这里使用了函数show,并额外添加了几个换行。show函数的功能是,打印出其参数值的文本表示形式。
可以看到,调用表达式sortperm(vector_int)返回的是一个一维数组。这个一维数组中的第 1 个元素值6的含义是,vector_int中的第 6 个元素值-102经排序后会处在第 1 的位置。而它的第 2 个元素值10的含义为,vector_int中的第 10 个元素值-102经排序后会处在第 2 的位置。以此类推。
更宽泛地讲,在sortperm函数返回的一维数组中,每一个元素值都分别是原数组中的某个元素值的索引号,而它们所处的位置都分别是原数组中的某个元素值在经过排序之后的新位置。所以,多点索引表达式vector_int[ord_nums]的求值结果就是已经排好序的原数组复本。它与调用表达式sort(vector_int)的结果值是相同的。
顺便说一下,sortperm函数也有关键字参数alg、lt、by、rev和order。而且,这些参数的含义和默认值也与sort函数中的同名参数没什么两样。这就意味着,我们在调用这个函数的时候同样可以自己定制比较规则。不过要注意,sortperm函数的第一个参数值只能是一个向量。也就是说,它无法对多维数组进行操作。
我们要说的最后一个与排序相关的函数是sortslices。它与sort函数有一个很明显的不同。
以二维数组为例,sort函数排列的是各个列或各个行中的元素值。更具体地说,当dims=1时,它会让每一个列里的元素值在各自所属的列中都是有序的。而当dims=2时,它会让每一个行里的元素值在各自所属的行中都是有序的。我们在前面已经展示过相应的示例,相信你对此已经有所体会。
然而,sortslices函数却不会对各个行或各个列中的元素值进行排序。它会把每一个行或者每一个列都分别视为不可分割的部分,并称之为切片(slice),然后对这些切片进行排序。
你还可以这样来理解:对于二维数组,sort函数面向的是其中的一个个列或者一个个行,并且它会以列中或行中的元素值为单元进行排序。而sortslices函数则是面向其中的某一个维度,并会以这个维度中的行或列为单元进行排序。
如果你觉得这些描述都比较抽象,那么可以先看完接下来的示例再回顾它们。我们先定义如下的二维数组:
julia> array2d_small = Int8[[3,1,7,2] [7,5,9,7] [3,0,1,6] [7,5,8,2]]
4×4 Array{Int8,2}:
3 7 3 7
1 5 0 5
7 9 1 8
2 7 6 2
julia>
这个名为array2d_small的二维数组有 4 个行和 4 个列。而且,无论从哪一个角度看,其中的各个元素值、各个行、各个列都是乱序的。
对于这个二维数组来说,它在第一个维度上的切片会分别包含每一行中的元素值,即:[3 7 3 7]、[1 5 0 5]、[7 9 1 8]和[2 7 6 2]。因为在第一个维度上的是各个纵向的列,所有切分就是横向的,并且会切断所有的列。又由于这些列的长度都是 4,所以一共需要切分 3 次。你现在能感受到“切片”这个词的含义了吗?
正因为如此,我们调用sortslices函数为array2d_small中的第一个维度排序才会得到如下的结果:
julia> sortslices(array2d_small, dims=1)
4×4 Array{Int8,2}:
1 5 0 5
2 7 6 2
3 7 3 7
7 9 1 8
julia>
切片[1 5 0 5]中的第一个元素值比其他切片中的第一个元素值都要小,所以它被排在了最上面。实际上,我们仅通过这 4 个切片中的第一个元素值就可以排好它们的顺序了。
我们再换一个维度对array2d_small进行排序:
julia> sortslices(array2d_small, dims=2)
4×4 Array{Int8,2}:
3 3 7 7
0 1 5 5
1 7 8 9
6 2 2 7
julia>
这一次,array2d_small会被切分成[3, 1, 7, 2]、[7, 5, 9, 7]、[3, 0, 1, 6]和[7, 5, 8, 2]。由于在第二个维度上的是各个横向的行,所有这次的切分是纵向的,不过切分的次数依然是 3 次。
在排序的时候,sortslices函数会成对地比较切片,并依次地比较其中在对应位置上的元素值。我们只靠心算也可以知道,[3, 0, 1, 6]是最小的,会被排在最左边。而[7, 5, 9, 7]是最大的,会被排在最右边。最后,经排序的新二维数组就如上所示了。
sortslices函数的关键字参数也很丰富。sort函数中有的它也都有。因此,如果我们想在做这种排序的同时自定义比较规则,也是完全没有问题的。
最后,关于这个函数,我们还需要注意如下三点:
- 我们在调用它的时候必须要为其
dims参数赋值,否则就会立即引发一个UndefKeywordError类型的错误。 - 虽然该函数的第一个参数的类型是
AbstractArray,但它却不能对一维数组排序。其原因是一维数组无法被切分成多个切片,因而以切片为单元的排序也就无从谈起了。 - 对于三维及以上的多维数组,参数
dims的值通常必须是一个包含了多个有效维度的元组。虽然也可以把代表了某个有效维度的正整数赋给该参数,但是这样的话我们就必须要制定特殊的比较规则了。
至此,关于数组的排序,我们先后讨论了 5 个函数,分别是sort、issorted、sort!、sortperm和sortslices。其中最基础、最常用的显然是sort函数。我们一旦理解了它,再去学习其他的函数就会容易很多。而且,我们前面讲的这些函数都很有特点,也都很有用,你都应该熟知。围绕着它们,Base.Sort模块还定义了一系列功能更加复杂的函数。不过,鉴于篇幅,我就不在这里多说了,留给你自己去探索。
10.3 数组的拷贝
在 Julia 中,任何的值都可以通过两种方式进行拷贝。一种方式是浅拷贝,另一种方式是深拷贝。数组也不例外。
函数copy的功能是浅拷贝一个值。它只会拷贝原值的外层结构,然后把原结构中的各个内部对象原封不动地塞到这个新的结构中。也就是说,新的结构加上原有的内部对象就形成了新的值。
这些原有的内部对象可能是原语类型的值,也可能是复合类型的值,另外还可能是更加复杂的值,比如容器。就拿数组来说,它的内部对象通常指的是其中的元素值。至于它们有多复杂,就要看数组的元素类型是什么了。
对于元素类型属于原语类型的数组来说,从表面上看,浅拷贝与深拷贝并没有什么区别。例如:
julia> array_orig1 = [2, 4, 6, 8, 10];
julia> array_copy1 = copy(array_orig1);
julia> array_copy1[1] = 12; show(array_copy1)
[12, 4, 6, 8, 10]
julia> show(array_orig1)
[2, 4, 6, 8, 10]
julia>
我利用copy函数得到了数组array_orig1的复本,并将其赋给了array_copy1变量。然后,我又使用索引表达式为这个复本中的第一个元素赋予了新的值。可以看到,即使我没有采用深拷贝,这种改变也不会影响到原数组array_orig1。
再来看元素类型属于复合类型的数组。我们对其复本中的元素值进行替换仍然不会影响到原数组。不过,有一些改变却会给这类的原数组带来实质性的影响。请看下面的代码:
julia> mutable struct Person
name::String
age::UInt8
extra
end
julia> p1 = Person("Robert", 37, "Beijing"); p2 = Person("Andres", 32, "Madrid"); p3 = Person("Eric", 28, "Paris");
julia> array_orig2 = Person[p1, p2, p3]
3-element Array{Person,1}:
Person("Robert", 0x25, "Beijing")
Person("Andres", 0x20, "Madrid")
Person("Eric", 0x1c, "Paris")
julia> array_copy2 = copy(array_orig2)
3-element Array{Person,1}:
Person("Robert", 0x25, "Beijing")
Person("Andres", 0x20, "Madrid")
Person("Eric", 0x1c, "Paris")
julia>
数组array_orig2的元素类型是Person,是一个可变的复合类型。该数组包含了 3 个元素值,分别是我刚刚定义的p1、p2和p3。数组array_copy2是array_orig2的复本,同样是由copy函数创建的。
我将要把array_copy2中的第三个元素值替换掉。这显然会改变array_copy2,但却不会对array_orig2造成影响。如:
julia> array_copy2[3] = Person("Mark", 45, "New York")
Person("Mark", 0x2d, "New York")
julia> show(array_orig2)
Person[Person("Robert", 0x19, "Beijing"), Person("Andres", 0x20, "Madrid"), Person("Eric", 0x1c, "Paris")]
julia>
实际上,无论数组的元素类型是什么,通过索引表达式替换元素值的操作都不会对原数组产生任何的影响。但是,如果我们改变的是某个元素值的内部对象,那么结果就截然不同了。就像下面这样:
julia> array_copy2[1].age = 38; Int(array_orig2[1].age)
38
julia>
我修改了array_copy2中的第一个元素值,把它的字段age的值改成了38。可以看到,这一操作使得array_orig2中对应元素值里的age字段的值也发生了同样的改变。
其实,array_copy2中的第一个元素值就是array_orig2中的第一个元素值本身,也就是说它们完全是同一个值。所以,我对前者的修改实际上就是在修改后者。而且,对于其中任何在对应位置上的元素值来说都会是如此。其根本原因就是,数组array_copy2是经由对数组array_orig2的浅拷贝而得出的复本。copy函数只拷贝了原数组的外层结构给新数组,却在新数组上直接沿用了原数组中的所有元素值。
不但如此,我们对原Person类型值的修改,也会立即反应到这两个数组中相应的元素值上。例如:
julia> p1.age = 25
25
julia> Int(array_orig2[1].age), Int(array_copy2[1].age)
(25, 25)
julia>
这再次印证了 Julia 中的值总是以共享的方式被传递的(passed by sharing)。数组array_orig2和array_copy2中的第一个元素值实际上都是p1的值本身。p2和p3的情况也是这样。
如果我们在元素类型属于容器类型的数组上做浅拷贝,显然也会发生类似的事情。比如:
julia> a1 = [1, 3, 5]; a2 = [2, 4, 6];
julia> array_orig3 = [a1, a2]; array_copy3 = copy(array_orig3);
julia> a1[2] = 30; array_orig3[1][2], array_copy3[1][2]
(30, 30)
julia>
那么,与浅拷贝相比,深拷贝有着怎样的不同呢?
深拷贝除了会拷贝原值的外层结构,还会把原结构中的所有内部对象都复制一遍,无论这些内部对象藏得有多么深。也就是说,新的结构和新的内部对象共同形成了全新的值。如此一来,复本与原值就可以做到相互独立、毫不相干了。示例如下:
julia> array_deepcopy3 = deepcopy(array_orig3);
julia> a1[2] = 60; array_orig3[1][2], array_deepcopy3[1][2]
(60, 30)
julia>
函数deepcopy用于对一个值进行深拷贝。我利用它得到了数组array_orig3的复本array_deepcopy3。我虽然可以通过a1[2] = 60修改数组array_orig3中的元素值,但无法通过同样的方式对数组array_deepcopy3进行修改。注意,在前一个例子执行完之后,array_orig3的值已变为[[1, 30, 5], [2, 4, 6]],而array_deepcopy3正是基于那时的它的复本。因此,索引表达式array_deepcopy3[1][2]的结果值才会是30。
我们来看一个更复杂一些的例子:
julia> a3 = [7, 9, 11]; a4 = [8, 10, 12];
julia> array_orig4 = [[a1, a3], [a2, a4]]
2-element Array{Array{Array{Int64,1},1},1}:
[[1, 60, 5], [7, 9, 11]]
[[2, 4, 6], [8, 10, 12]]
julia> array_deepcopy4 = deepcopy(array_orig4);
julia>
数组array_orig4中的每一个元素值都分别是一个数组,并且在这些数组之中还有数组。也就是说,array_orig4是数组的数组的数组,即一个拥有三层结构的数组。而数组array_deepcopy4则产生自对array_orig4的深度拷贝。下面我们来看看deepcopy函数是否已将其中的所有内部对象全都拷贝了出来。代码如下:
julia> a4[1] = 80; array_orig4[2][2][1], array_deepcopy4[2][2][1]
(80, 8)
julia> array_orig4[2][2][1] = 82; array_deepcopy4[2][2][1]
8
julia>
显然,无论内部对象有多么复杂,由deepcopy函数产生的数组复本都是完全独立于原数组的。
好了,现在我们知道了,拷贝像数组这样的对象很容易,调用一个函数就可以了。copy函数用于浅拷贝,它只会拷贝原数组的外层结构,并沿用其所有的元素值。deepcopy函数用于深拷贝,它不仅会拷贝原数组的外层结构,而且还会拷贝其所有的元素值以及更深层次的内部对象(如果有的话)。
10.4 数组的拼接
我们在上一章其实已经学会了怎样利用字面量和专用符号拼接出一个数组,比如[[1;2] [3;4] [5;6]]或[[1 2]; [3 4]; [5 6]]。接下来我们会关注,怎样通过调用函数把多个数组拼接在一起。
为了避免混乱,我们先把前面定义的那 4 个一维数组还原成初始值:
julia> a1 = [1, 3, 5]; a2 = [2, 4, 6]; a3 = [7, 9, 11]; a4 = [8, 10, 12];
julia>
还记得吗?Julia 中的一维数组都是列向量。而且,我们可以使用英文分号纵向地拼接数组,并使用空格横向地拼接数组。所以,我们也可以把纵向的拼接叫做在第一个维度上的拼接,并把横向的拼接叫做在第二个维度上的拼接。下面的例子看起来会更加的形象:
julia> [a1; a2]
6-element Array{Int64,1}:
1
3
5
2
4
6
julia> [a1 a2]
3×2 Array{Int64,2}:
1 2
3 4
5 6
julia>
这两种拼接实际上都可以通过调用cat函数来实现。我们需要做的就是,把要拼接的多个数组都传给这个函数,同时确定其关键字参数dims的值。这个关键字参数代表的就是,将要在哪一个维度上进行拼接。而且,它还是一个必选的参数。我们下面就用这个函数来实现前面的那两个拼接操作:
julia> cat(a1, a2, dims=1)
6-element Array{Int64,1}:
1
3
5
2
4
6
julia> cat(a1, a2, dims=2)
3×2 Array{Int64,2}:
1 2
3 4
5 6
julia>
这很容易不是吗?不过,如果只是这样的话,我想这个cat函数就没有太大的存在意义了。实际上,我们还可以为它的dims参数赋予更大的正整数。例如:
julia> cat(a1, a2, dims=3)
3×1×2 Array{Int64,3}:
[:, :, 1] =
1
3
5
[:, :, 2] =
2
4
6
julia> cat(a1, a2, dims=4)
3×1×1×2 Array{Int64,4}:
[:, :, 1, 1] =
1
3
5
[:, :, 1, 2] =
2
4
6
julia>
如上所示。当dims=3时,cat函数会把a1和a2分别作为两个二维数组的唯一组成部分,然后再用这两个二维数组合成一个三维数组。从而,这个三维数组的尺寸就是3×1×2。更具体地说,之所以它在第一个维度上的长度是3,是因为a1和a2的长度都是3。它在第二个维度上的长度是1,是因为a1和a2都是一维的数组,并且它们分别是那两个二维数组中唯一的低维数组。至于第三个维度上的长度为2的根本原因是,我们用来做拼接的数组有两个。
当dims=4时,cat函数依然会把a1和a2分别作为两个二维数组的唯一组成部分。并且,它还会把这两个二维数组分别作为两个三维数组的唯一组成部分。最后,它会再用这两个三维数组合成一个四维数组。所以,这个四维数组的尺寸才会是3×1×1×2。至于更多的细节,我想你应该已经可以参照前面的描述自行解释了。
我们再来一起拼接一个更加复杂的数组。首先,我们要合成两个二维数组,如下:
julia> a13 = cat(a1, a3, dims=2)
3×2 Array{Int64,2}:
1 7
3 9
5 11
julia> a24 = cat(a2, a4, dims=2)
3×2 Array{Int64,2}:
2 8
4 10
6 12
julia>
这两个二维数组的尺寸都是3×2,并且它们的元素值也都很有特点。现在,我们要把它们拼接成一个四维数组:
julia> cat(a13, a24, dims=4)
3×2×1×2 Array{Int64,4}:
[:, :, 1, 1] =
1 7
3 9
5 11
[:, :, 1, 2] =
2 8
4 10
6 12
julia>
这个四维数组的尺寸是3×2×1×2。与前面那两个3×2的数组比对一下,你是不是已经看出一些规律了呢?没错,它们在前两个维度上的尺寸完全相同。并且,最后一个维度上的长度完全取决于我们用来做拼接的数组的个数。至于第三个维度上的1,是因为我们拿来做拼接的是二维数组,它们都没有第三个维度。
一旦理解了这些,我们就可以使用一些更加便捷的函数来做拼接了。比如,vcat函数仅用于纵向的拼接,我们只把要拼接的数组传给它就可以了:
julia> vcat(a1, a2)
6-element Array{Int64,1}:
1
3
5
2
4
6
julia>
又比如,hcat函数仅用于横向的拼接,它的用法与vcat函数一样:
julia> hcat(a1, a2)
3×2 Array{Int64,2}:
1 2
3 4
5 6
julia>
另外,我们还要详细地说一下hvcat这个函数。它可以同时进行纵向和横向的拼接。在使用的时候,我们先要确定拼接后的数组的尺寸,然后再传入用于拼接的值。先看一个最简单的例子:
julia> hvcat(3, a1...)
1×3 Array{Int64,2}:
1 3 5
julia>
如果我们把拼接后数组的尺寸确定为一个正整数,那么就相当于在确定新数组的列数。至于新数组会有多少行,那就要看用于拼接的值有多少个了。正如上例所示,我们传给hvcat函数的第一个参数值3代表着新数组会有 3 列。如此一来,这个函数就会依次地把a1中的各个元素值分别分配给新数组中的某一列。
注意,我们在这里传给hvcat函数的第二个参数值是a1...,而不是a1。这是为什么呢?
还记得吗?符号...的作用是,把紧挨在它左边的那个值中的所有元素值都平铺开来,让它们都成为独立的参数值。所以,上述调用就相当于hvcat(3, 1, 3, 5)。如果我们把...从中去掉,那么 Julia 就会立即报错:
julia> hvcat(3, a1)
ERROR: ArgumentError: number of arrays 1 is not a multiple of the requested number of block columns 3
# 省略了一些回显的内容。
julia>
这条错误信息的大意是:既然确定了新数组会有 3 列,那么后面提供的参数值的个数就应该是 3 的倍数。否则,这个函数就无法均匀地把参数值分配到各个列上。由于我们在后面只提供了一个参数值a1,所以就引发了这个错误。
在第一个参数值是3的情况下,如果后续参数值的数量正好是 3,那么hvcat函数就会生成一个1×3的二维数组。如果这个数量是 6,那么它就会生成一个2×3的二维数组。以此类推。
原则上,除了第一个参数,我们可以把任意的值作为参数值传给hvcat函数。但如果这些参数值都是一维数组,那么该函数就会识别出它们,并依次地把它们(包含的所有元素值)分别分配给新数组中的某一列。例如:
julia> hvcat(3, a1, a2, a3)
3×3 Array{Int64,2}:
1 2 7
3 4 9
5 6 11
julia>
此时,新数组的行数就取决于后续参数值的长度。注意,这些后续的参数值的长度必须是相同的。
下面我们考虑第一个参数值不是正整数的情况。先来看一个很近似的例子:
julia> hvcat((3), a1, a2, a3)
3×3 Array{Int64,2}:
1 2 7
3 4 9
5 6 11
julia>
这次我们传给hvcat函数的第一个参数值是一个元组,并且其中只包含了一个元素值3。这个调用表达式的求值结果与前一个例子的结果完全相同。
你可能已经猜到,这个元组里的3同样代表了新数组的列数。不过,它还有另外一个含义,即:新数组进行第一轮分配时所需的后续参数值的数量。如果还有第二轮分配的话,那么就可以是下面这样:
julia> hvcat((3,3), a1, a2, a3, a1, a2, a3)
6×3 Array{Int64,2}:
1 2 7
3 4 9
5 6 11
1 2 7
3 4 9
5 6 11
julia> hvcat(3, a1, a2, a3, a1, a2, a3)
6×3 Array{Int64,2}:
1 2 7
3 4 9
5 6 11
1 2 7
3 4 9
5 6 11
julia>
请注意,在此例中,上面的调用表达式中的第一个参数值是(3,3),而下面的第一个参数值是3。它们起到的作用是一样的。
可以看到,在这两个调用表达式中,hvcat函数都会先依次地把第 1、2、3 个一维数组中的所有元素值分别分配给新数组的第 1、2、3 列。这对应于求值结果中的前三行。然后,它会再把第 4、5、6 个一维数组中的所有元素值分别分配给新数组的那三列。这对应于求值结果中的后三行。此时,新数组的行数就等于这些一维数组的长度的 2 倍。显然,这些一维数组的长度也必须是相同的。
现在我们知道了,参数值(3,3)中的第二个3的含义是:新数组进行第二轮分配时所需的后续参数值的数量。实际上,作为传递给hvcat函数的第一个参数值,元组中的每一个正整数都必须是相同的。如果出现了像(3,2)、(3,3,2)这样的参数值,那么hvcat函数就会立即报错。
那为什么还要向hvcat函数传入元组呢?我们直接传入一个正整数不就好了吗?
与只传入一个正整数相比,传入一个元组有以下两点不同:
- 传入元组可以确切地告诉
hvcat函数需要为新数组分配几轮元素值。而如果只传入一个正整数,我们可能还需要计算一下才能得知真正的分配轮数。因为后续参数值的数量可以是这个正整数的任意倍数。比如,假设后续的参数值是a5...,而我们并不知道a5里有多少个元素值,所以就无法预料到分配的轮数。 - 一旦分配的轮数由元组确定下来,后续参数值的数量就必须大于“
<元组中的首个元素值> x <元组中元素值的数量>”,否则hvcat函数就会报错。而如果只传入一个正整数,那么只要后续参数值的实际数量不是这个正整数的倍数就会引发错误。显然,传入元组可以放宽对后续参数值的约束。
因此,这里就存在一个选择的问题。我们需要根据实际情况选择“灵活”或者“严谨”。当你在编写一个供他人使用的程序的时候,这种选择尤为重要。不过,这种选择在很多时候并不意味着非0即1。
言归正传。虽然hvcat函数在二维数组的拼接方面很强大,但是它与vcat和hcat一样,都无法拼接出维数更多的数组。为了满足这样的需求,我们只能使用cat函数。当然,若我们要拼接很复杂的数组,则可以把这些函数组合起来使用。我更加推荐这种使用方式。因为这样做可以使程序的可读性更好,也更不容易出错,另外在程序的性能方面往往也不会有什么损失。
10.5 数组的比较
在这本书里,容器的比较已经不是一个新问题了。对于一维数组,我们同样可以直接使用比较操作符对它们进行比较。如:
julia> [1, 2, 3, 4] < [1, 3, 2, 4]
true
julia>
Julia 会沿着线性索引号依次地比较两个数组中的每一个元素值,直到足以做出判断为止。
在一般情况下,如果两个数组中同索引号的元素值都相同,并且两个数组的尺寸也相同,那么它们就一定是相等的。但是,如果我们使用的是===,那么就需要特别注意了。因为这个操作符比较的是两个数组在内存中的存储地址。例如:
julia> a5 = [1,1,2,3,5,8,13]; a5 === a5, a5 === [1,1,2,3,5,8,13]
(true, false)
julia>
对于多维数组,操作符==、!=、===和!==以及函数isequal都依然是有效的。但是,其他的比较操作符(如<、<=、>、>=等)就无法应用了。即使是很通用的isless函数也不能接受多维数组。
为了解决这一问题,我们可以参考cmp函数的做法。cmp是 compare 的缩写。这个函数的功能就是比较两个值的大小。它有一个衍生方法可以比较两个一维数组。例如:
julia> cmp([1,2,3,4], [1,3,2,4])
-1
julia>
当第一个数组小于第二个数组时该方法会返回-1,当第一个数组大于第二个数组时该方法会返回1,若两个数组相等它就会返回0。不过很可惜,这个方法只接受AbstractVector类型的参数值。
我们可以从这个cmp方法的源码中找到灵感。该方法被定义在了 Julia 的Base模块里的abstractarray.jl文件中。即使我们只是把它的源码复制出来、改动一下它的参数类型,也可以满足当下的需求。就像这样:
julia> import Base.cmp
julia> function cmp(A::Array, B::Array)
for (a, b) in zip(A, B)
if !isequal(a, b)
return isless(a, b) ? -1 : 1
end
end
return cmp(length(A), length(B))
end
cmp (generic function with 31 methods)
julia>
我为cmp函数定义了一个新的衍生方法。由于其中涉及到了一些我们未曾讲过的流程控制和衍生方法创建的代码,所以你在这里不用太在意它的编写细节。实际上,除了把两个参数的类型都改为Array之外,它与那个可以比较一维数组的cmp方法一模一样。
为了测试这个方法是否可用,我还定义了一些数组:
julia> a6 = [[1,2] [3,4]]
2×2 Array{Int64,2}:
1 3
2 4
julia> a7 = [[1,3] [2,4]]
2×2 Array{Int64,2}:
1 2
3 4
julia> a8 = vcat(a6, a7)
4×2 Array{Int64,2}:
1 3
2 4
1 2
3 4
julia> a9 = hcat(a6, a7)
2×4 Array{Int64,2}:
1 3 1 2
2 4 3 4
julia> a10 = cat(a6, a7, dims = 3)
2×2×2 Array{Int64,3}:
[:, :, 1] =
1 3
2 4
[:, :, 2] =
1 2
3 4
julia>
你最好先在心里估算一下它们谁大谁小,然后再来看下面的测试结果:
julia> cmp(a6, a7), cmp(a6, a8), cmp(a6, a9), cmp(a6, a10)
(-1, 1, -1, -1)
julia>
你能看出哪里不太对吗?没错,数组a6竟然比数组a8还要大!可是,a8中的第一个列向量(即[1,2,1,3])明显要比a6中的[1,2]更大啊。这是怎么回事呢?
我在前面说过,对于数组的比较,Julia 会沿着线性索引号去比较每一个对应的元素值,直到能做出判断为止。我们创建的这个cmp方法也是这么做的。因此,我们用索引表达式查看一下就可以知道原因了:
julia> a6[[1,2,3,4]]
4-element Array{Int64,1}:
1
2
3
4
julia> a8[[1,2,3,4]]
4-element Array{Int64,1}:
1
2
1
3
julia>
在数组a8中,与索引号3和4对应的是它的第一个列向量中的后两个元素值,即:1和3。然而,由于数组a6中的列向量长度为2,所以其中与索引号3和4对应的就是其第二个列向量中的那两个元素值,即:3和4。所以谁大谁小也就不言自明了。这就是所谓的“沿着线性索引号比较”。这种比较不会在意数组在各个维度上的长度,而只会关注与线性索引号对应的那些元素值。
正因为数组a6和a8在第一个维度上的长度不同,所以才导致实际的比较结果与我们的直觉不一样。而其根本的原因在于,我们在做位置上的对应(或者说基于图形的对应),而 Julia 却在用线性索引号做对应。既然我们编写的是 Julia 程序,那么最好还是遵从后者。这种情况也恰恰代表了我们在编程时需要做出的一种思维转变。要想编写出优秀的程序,我们首先就要面向计算机转变思维。
言归正传。我把相关的代码放到了Programs项目中,源码文件的相对路径为src/ch10/cmp/main.jl。其中还有一些我没在这里展示的代码,是关于isless函数的。你如果有兴趣的话可以先自行探究一番。
总之,我们可以使用 Julia 中现成的操作符和函数比较一维数组,不过需要注意涉及到===的操作。对于多维数组,我们自己编写比较函数其实也并不困难。不过,这种比较应该基于位置还是基于索引号,就需要我们仔细斟酌了。我还是建议做基于索引号的比较。因为这样看起来更容易做到程序上的兼容。
10.6 再说数组的构造
现在,让我们再次转到数组值的构造这个主题上来。我们还需要知道一些关于它的方式方法。
除了直接用字面量编写(即一般表示法)或者调用构造函数,我们还可以使用另外一种方式产生数组值。这种方式被称为数组推导。先来看一个简单的例子:
julia> array_comp1 = [e*2 for e in 1:6]
6-element Array{Int64,1}:
2
4
6
8
10
12
julia>
与数组的一般表示法一样,数组推导式(comprehensions)在最外层也有一对中括号。但与之不同的是,后者的中括号内并没有元素值的排列。取而代之的是,一个针对元素值的加工表达式(以下简称加工表达式)和一个简写形式的for语句(以下简称for从句)。
在上例中,e*2就是加工表达式,而for e in 1:6则是for从句,它们之间由空格分隔。加工表达式会逐个地处理for从句迭代出的每一个值,也就是在后者迭代时先后赋予迭代变量e的那些值。这些经过处理的值都将被包含在新数组中。Julia 会严格按照迭代的顺序排列它们。由此可见,上面的代码就相当于:
julia> array_comp1 = [];
julia> for e in 1:6
append!(array_comp1, e*2)
end
julia> array_comp1
6-element Array{Any,1}:
2
4
6
8
10
12
julia>
顺便说一下,其中的函数append!的功能是,将它的第二个参数值追加进由第一个参数代表的列向量内。第二个参数值可以是一个单一值,也可以是一个列向量或元组。如果是后者,那么它里面的所有元素值都会被依次地追加进第一个参数值内。
数组推导式中的被迭代对象也可以是一个多维的数组。这时,新数组的维数和长度都仍然会依从于被迭代的对象。同时,加工表达式也仍然会分别处理被迭代对象中的每一个元素值。示例如下:
julia> array_comp2 = [e*2 for e in [[1,2] [3,4] [5,6]]]
2×3 Array{Int64,2}:
2 6 10
4 8 12
julia>
不过,新数组的元素类型却可以与被迭代对象的元素类型不同。更明确地说,它只由加工表达式决定。加工表达式的结果类型就将是新数组的元素类型。例如:
julia> array_comp3 = [Float32(e*2) for e in [[1,2] [3,4] [5,6]]]
2×3 Array{Float32,2}:
2.0 6.0 10.0
4.0 8.0 12.0
julia>
这里的加工表达式的结果类型显然是Float32。所以,新数组的元素类型也会是Float32。
另外,数组推导式中也可以同时存在多个被迭代对象。在这种情况下,它的for从句的写法会有所不同。下面是一个例子:
julia> array_comp4 = [x+y for x=1:2, y=[10,20,30]]
2×3 Array{Int64,2}:
11 21 31
12 22 32
julia>
这里有三点需要注意:
- 这时的
for从句的写法不再是“for <迭代变量> in <被迭代对象>”,而是“for <迭代变量1>=<被迭代对象1>, <迭代变量2>=<被迭代对象2>, ...”。请注意,其中的等号的含义是“每次迭代均赋值”,而不是单纯的“赋值”。另外,英文逗号在这里起到了分隔的作用。实际上,即使只有一个被迭代对象,我们也可以使用“for <迭代变量>=<被迭代对象>”这种写法。 - 这时的
for从句并不会同时迭代两个被迭代对象。它会先去迭代右边数的第一个对象,并在迭代右边数的第一个对象一次之后去遍历右边数的第二个对象一次。然后,再迭代一次第一个对象并再遍历一次第二个对象。如此交替往复,直到完全迭代完右边数的第一个对象为止。这里所说的遍历是指,从头到尾地迭代一遍。 - 新数组中的元素值数量会等于各个被迭代对象的元素值数量的乘积,而新数组的维数则会等于各个被迭代对象的维数之和。而且,第一个被迭代对象(假设为 N 维数组)中的各个维度的长度会决定新数组中前 N 个维度的长度,而第二个被迭代对象(假设为 M 维数组)中各个维度的长度则会决定新数组中第 N+1 个至第 N+M 个维度的长度,以此类推。最后,Julia 总会把加工表达式产出的一个个值按照线性索引的顺序依次地放到新数组中的各个元素位置上。
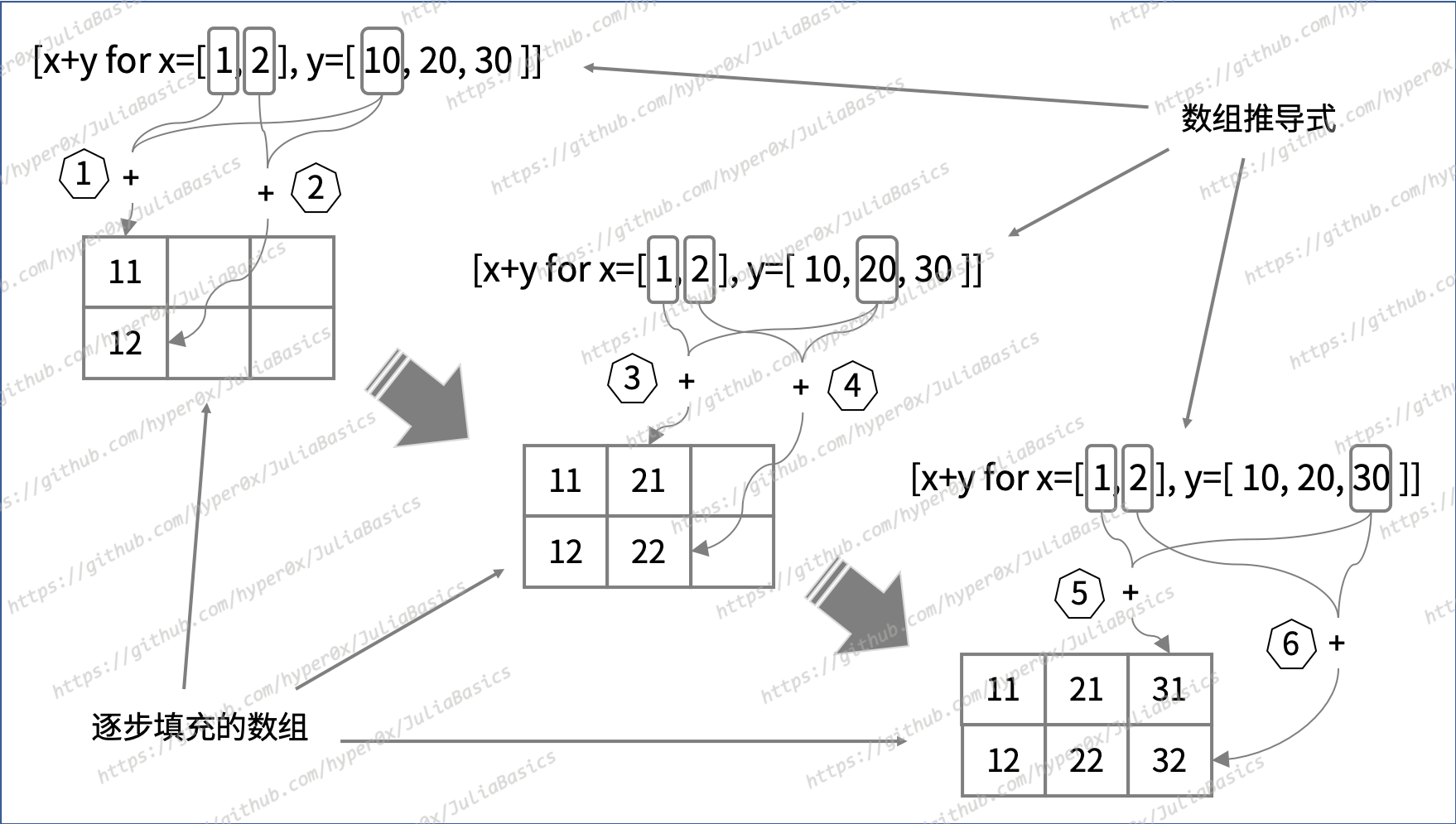
图 10-1 数组推导式的求值过程
对于第 3 个注意事项,我们再来看一个例子:
julia> array_comp5 = [x+y for x=[[1,2] [3,4]], y=10:10:30]
2×2×3 Array{Int64,3}:
[:, :, 1] =
11 13
12 14
[:, :, 2] =
21 23
22 24
[:, :, 3] =
31 33
32 34
julia>
在这个例子中,第一个被迭代对象是[[1,2] [3,4]]。它有 2 个维度,且每一个维度的长度都是 2。因此,其元素值的总数就是 4。第二个被迭代对象是10:10:30,它是StepRange类型的,表示的是一个从10开始、到30结束且相邻值间隔为10的数值序列。显然,此序列只有 1 个维度,且长度是 3。所以,新数组中的元素值共有 12 个,并且它是一个2×2×3的三维数组。我们通过上面的 REPL 环境的回显内容就可以对此进行验证。
如果我们想把迭代出并加工好的一个个值都塞到一个一维的数组中,那么就需要换一种写法。请看下面的示例:
julia> array_comp6 = [x+y for x=[[1,2] [3,4]] for y=10:10:30]
12-element Array{Int64,1}:
11
21
31
12
⋮
33
14
24
34
julia>
在这里,for从句的写法变成了“for <迭代变量1>=<被迭代对象1> for <迭代变量2>=<被迭代对象2>”。也就是说,我只是把其中的英文逗号“,”换成了“for”(两边都有空格)。一定要注意,虽然这样的改动很小,但却会明显改变迭代的次序。
你可能也看出来了,后面这种写法会使得for从句先去迭代左边数的第一个对象,而不是右边数的第一个对象。更具体地说,它每迭代一次左边数的第一个对象就会遍历一次左边数的第二个对象。
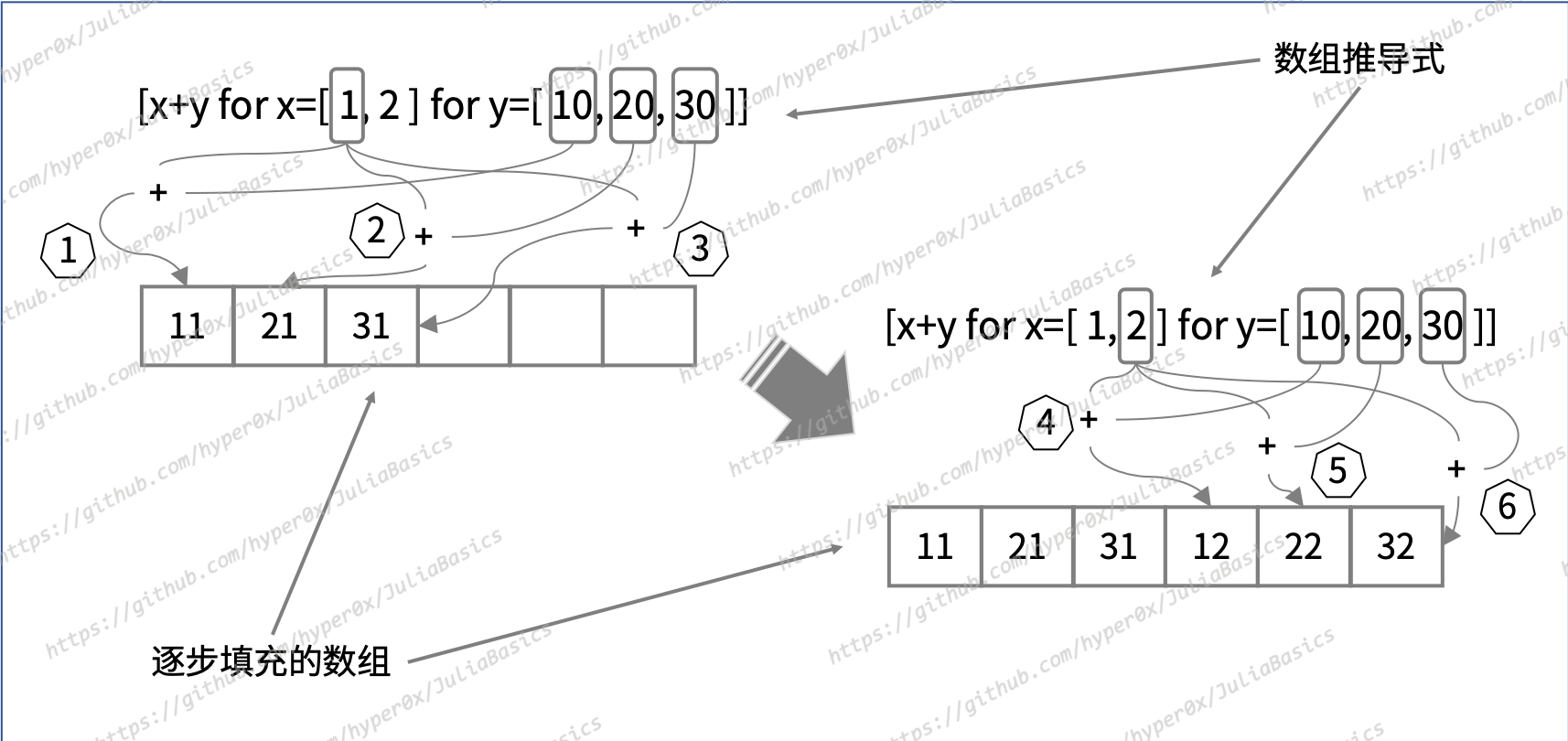
图 10-2 另一个数组推导式的求值过程
实际上,这与嵌套在一起的多条for语句所表现出的行为是一样的。
另外,数组推导式还有一种机制可以对for从句迭代出的元素值进行过滤。它只会把满足既定条件的那些元素值传给加工表达式。这种机制是用另一种从句表达的,即:if从句。
这里所说的if从句实质上是if语句的简写形式。与for语句一样,if语句也是控制代码的执行流程的一种方式。简单来说,它可以表达“如果满足这里的条件,就执行语句中的代码”的语义。类似的,数组推导式中的if从句表达的语义是“如果满足这里的条件,就把当前的元素值传给加工表达式”。我们来看一个例子:
julia> array_comp7 = [x+y for x=[[1,2] [3,4]], y=10:10:30 if isodd(x)]
6-element Array{Int64,1}:
11
13
21
23
31
33
julia>
这个例子中的数组推导式是基于array_comp5的那个数组推导式变化而来的。我没有修改已有的for从句和加工表达式,只是在for从句的右边添加了一条if从句而已。请注意,这两条从句之间需要由空格分隔。
这条if从句有两个部分,即:代表if从句起始的if关键字和代表条件表达式的isodd(x)。显然,它表达的条件是,从第一个对象迭代出的元素值是奇数。从数组推导式返回的结果我们也可以看出,新数组中的元素值都是奇数。这正是因为,新元素值的个位是由第一个被迭代对象中的元素值决定的。另外,你应该也看到了,新数组是一个一维的数组。实际上,只要加入了if从句,数组推导式的求值结果就只可能是一维数组。
我们在前面说过,数组推导式在最外层会有一对中括号。不过,这对中括号也可以没有。但是这时就不能叫它数组推导式了,而应该叫做生成器表达式(generator expressions)。
与数组推导式不同,生成器表达式既不能独立存在也不能被赋给某个变量。它只能被作为参数值传入某个函数。为了避免歧义和提高可读性,我们总是应该用一对圆括号包裹生成器表达式。请看下面的示例:
julia> reduce(*, (x for x=1:5))
120
julia> xs = [x for x=1:5]; reduce(*, xs)
120
julia>
这个例子中的前一行代码包含了一个生成器表达式,而后一行代码包含了一个数组推导式。这两行代码做了同样的事情,那就是计算了从1到5的阶乘。虽然前一行代码更短,但是显然后一行代码的可读性更好,同时也更容易修改。那么使用生成器表达式的优势到底在哪里呢?
实际上,使用生成器表达式的唯一优势就在于,它可以在不预先生成数组结构和存储元素值的情况下,进行基于那些元素值的计算。再简单一点说就是,它比较节省内存空间。我们来用代码观测一下:
julia> @allocated reduce(*, (x for x=1:10))
0
julia> @allocated reduce(*, [x for x=1:10])
160
julia>
宏@allocated的功能是,观测和显示后续代码在执行的过程中用掉的内存空间,单位是字节。可以看到,这里的生成器表达式在执行的过程中并没有申请新的内存空间,而使用数组推导式实现同样的功能则要用掉160个字节。
当然了,程序的好坏肯定不能单凭是否节省内存空间来衡量。如果我们观测程序的执行时间(可以用@timev宏),那么生成器表达式通常还不如数组推导式。再加上可读性和可扩展性方面的考虑,我建议你知道有这样一种代码编写方式就可以了,不要迷恋这种看上去很潇洒的写法,尤其不要滥用。写程序还是要优先关注可读性和可扩展性。而且,在内存如此廉价的当代,我们在考虑程序的性能时应该更加关注执行的时间而不是占用的内存。
言归正传。我们再来概括一下。数组推导式能够产生新的数组值。它可以由三个部分组成,按照从左到右的顺序,即:加工表达式、for从句和if从句。前两个部分是必须要有的,而最后一个部分是可选的。
数组推导式产生新元素值的过程简单来说是这样的:for从句从被迭代对象那里迭代出元素值,若有if从句则要对元素值进行条件判断和过滤,最后把(满足条件的)元素值传给加工表达式以生成新的元素值。数组推导式会根据被迭代对象的基本要素以及for从句的编写形式和if从句的有无来创建新的数组结构,并按照线性索引的顺序依次地把一个个新生成的元素值放到这个数组结构中的相应元素位置上。
总之,数组推导式是继一般表示法和构造函数之后的第三大数组构造方式。而且,它的功能更为强大,在灵活性方面也明显胜过后两者。
10.7 小结
在这一章,我们讨论了 6 个与数组相关的重要专题。其中,前两个专题,即:“广播式的修改”和“元素值的排序”,讲的主要是怎样根据意愿修改或调整数组中的元素值。而紧接着的三个专题则阐述了怎样把数组作为一个整体进行操作,包括:拷贝、拼接和比较。最后的一个专题揭示了第三种构造数组的方式——使用数组推导式。
我希望也相信这些专题能够帮助你在高效运用数组方面更上一层楼。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









