









十大排序算法小结
1.堆排序
解释:
int[ ] nums数组的长度为length,
则nums[ i ]的左子节点是nums[2 * i + 1],右子节点是nums[2 * i + 2]
第一个非叶子结点是nums[ length / 2 - 1]
思路:构建大顶堆的步骤是从第一个非叶子节点倒退到根节点进行HeapSort操作,
如果交换了根节点(最大值)和最后一个节点,且把最后一个节点在下一阶段排除之后的话,相当于只有根节点未进行HeapSort,因此只需要一次HeapSort即可
public class HeapSort {
public void sort(int[] nums){
//构建大顶堆
for(int i = nums.length / 2 - 1; i >= 0; i--){
adjustHeap(nums, i, nums.length);
}
for(int i = nums.length - 1; i >= 0; i--){
swap(nums, 0, i);
adjustHeap(nums,0, i);
}
}
public void adjustHeap(int[] nums, int parent, int length){
int temp = nums[parent]; // temp保存当前父节点
int child = 2 * parent + 1; // 先获得左孩子
while (child < length) {
// 如果有右孩子结点,并且右孩子结点的值大于左孩子结点,则选取右孩子结点
if (child + 1 < length && nums[child] < nums[child + 1]) {
child++;
}
//至此child指的是两个孩子较大的下标,也就是可能要和父节点交换的下标
if (temp >= nums[child]) {
break;
}
// 把孩子结点的值赋给父结点
nums[parent] = nums[child];
// 选取孩子结点的左孩子结点,继续向下筛选
parent = child;
child = 2 * child + 1;
}
//此时parent为交换的最下标
nums[parent] = temp;
}
public void swap(int[] nums, int a, int b){
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
}
2.快速排序
class QuickSort{
public void sort(int[] nums){
qSort(nums,0, nums.length - 1);
}
public void qSort(int[] nums, int left, int right){
if(left >= right) return;
int pivot = left + (int)(Math.random() * (right - left + 1)) + left;
int value = nums[pivot];
swap(nums, left, pivot);
int l = left, r = right;
while(left < right){
while(left < right && nums[r] >= value){
r--;
}
while(left < right && nums[l] <= value){
l++;
}
if(l < r){
swap(nums, l , r);
}
}
swap(nums, l, left);
qSort(nums,left, l - 1);
qSort(nums,l + 1, right);
}
public void swap(int[] nums, int a, int b){
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
}
3.归并排序
需要构造一个新的数组来保存当前排序后的数组;
class MergeSort{
public void sort(int[] nums){
}
public void mSort(int[] nums, int left, int right){
if(left >= right) return;
int mid = left + (right - left) / 2;
mSort(nums, left, mid);
mSort(nums,mid + 1, right);
int[] newNums = new int[right -left + 1];
int l1 = left, l2 = mid + 1, i = 0;
while(l1 <= mid && l2 <= right){
if(nums[l1] < nusm[l2]){
newNums[i++] = nums[l1++];
}else{
newNums[i++] = nums[l2++];
}
}
while(l1 <= mid){
newNums[i++] = nums[l1++];
}
while(l2 <= right){
newNums[i++] = nums[l2++];
}
for(int i = left; i <= right; i++){
nums[i] = newNums[i - left];
}
}
}
4.冒泡排序
public class BubbleSort{
public void sort(int[] nums){
int len = nums.length;
for(int i = len - 1; i >= 0; i--){
for(int j = 1; j <= i; j++){
if(nums[j] < nums[j - 1]){
swap(nums, j, j - 1);
}
}
}
}
public void swap(int[] nums, int a, int b){
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
}
5.选择排序
public class ChooseSort {
public static void sort(int[] nums){
int len = nums.length;
for(int i = len - 1; i >= 0; i--){
int max = Integer.MIN_VALUE;
int index = 0;
for(int j = 0; j <= i; j++){
if(nums[j] > max){
index = j;
max = nums[j];
}
}
swap(nums,index, i);
}
}
public static void swap(int[] nums, int a, int b){
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
}
6.插入排序
public class InsertSort {
public void sort(int[] nums){
int len = nums.length;
for(int i = 1; i < len; i++){
if(nums[i] < nums[i - 1]){
int index = i - 1;
int value = nums[i];
while(index >= 0 && nums[i] < nums[index]){
index--;
}
for(int j = index + 1; j < i ; j++){
swap(nums, j, j + 1);
}
nums[index + 1] = value;
}
}
}
public void swap(int[] nums, int a, int b){
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}
}
7.希尔排序(插入排序的升级版)
如果序列是基本有序的,使用直接插入排序效率就非常高。时间复杂度可以达到O(n^1.3)。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
8.桶排序
划分多个范围相同的区间,每个子区间自排序,最后合并。
桶排序需要尽量保证元素分散均匀,否则当所有数据集中在同一个桶中时,桶排序失效。
public static void bucketSort(int[] arr){
// 计算最大值与最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
// 计算桶的数量
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 将每个元素放入桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
// 对每个桶进行排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
// 将桶中的元素赋值到原序列
int index = 0;
for(int i = 0; i < bucketArr.size(); i++){
for(int j = 0; j < bucketArr.get(i).size(); j++){
arr[index++] = bucketArr.get(i).get(j);
}
}
}
9.基数排序
基数排序又是一种和前面排序方式不同的排序方式,基数排序不需要进行记录关键字之间的比较。基数排序是一种借助多关键字排序思想对单逻辑关键字进行排序的方法。所谓的多关键字排序就是有多个优先级不同的关键字。基数排序是通过多次的收分配和收集来实现的,关键字优先级低的先进行分配和收集。
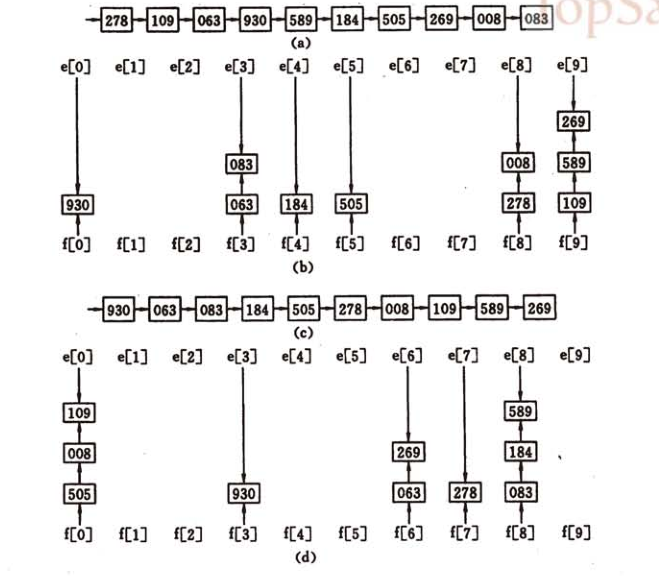
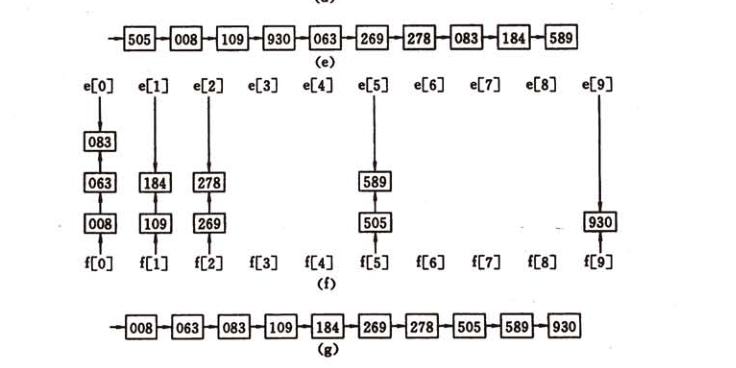
10.计数排序
经典空间换时间,算法时间复杂度可以达到O(N),找到最小值和最大值,分配空间并计数
public int[] countSort2(int[] A) {
// 找出数组A中的最大值、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for (int num : A) {
max = Math.max(max, num);
min = Math.min(min, num);
}
// 初始化计数数组count
// 长度为最大值减最小值加1
int[] count = new int[max-min+1];
// 对计数数组各元素赋值
for (int num : A) {
// A中的元素要减去最小值,再作为新索引
count[num-min]++;
}
// 创建结果数组
int[] result = new int[A.length];
// 创建结果数组的起始索引
int index = 0;
// 遍历计数数组,将计数数组的索引填充到结果数组中
for (int i=0; i<count.length; i++) {
while (count[i]>0) {
// 再将减去的最小值补上
result[index++] = i+min;
count[i]--;
}
}
// 返回结果数组
return result;
}
11.排序性能总结和使用场合
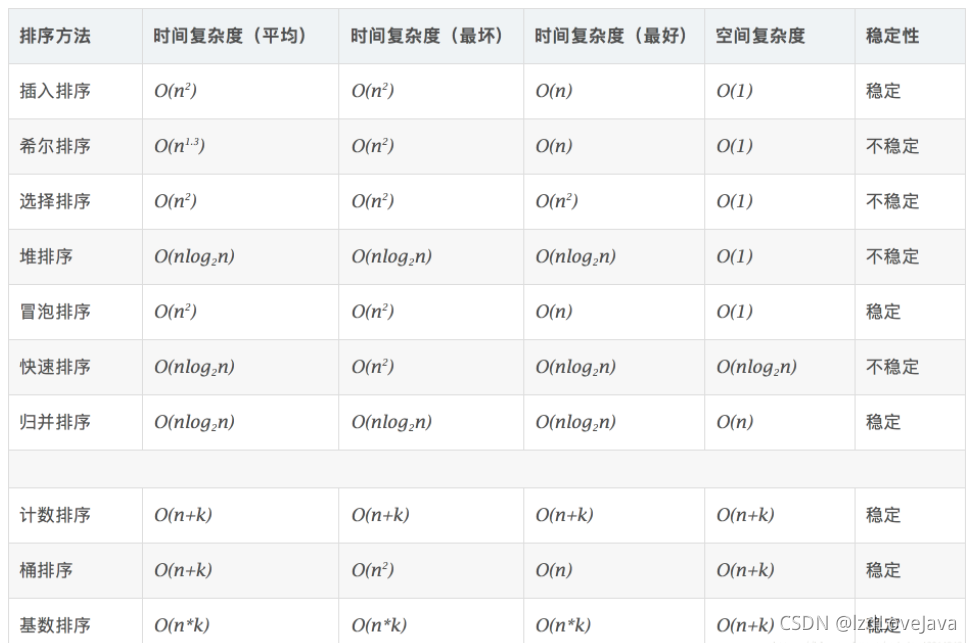
一些基本的术语
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:如果a原本在b的前面,而a=b,排序之后a可能出现在b的后面;
内排序:所有的排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
时间复杂度:一个算法执行所消耗的时间;
空间复杂度:运行完一个程序所需内存的大小。
堆排序应用场景
堆排序适合于数据量非常大的场合(百万数据)。
堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
归并排序应用场景
能够使用并行计算的时候使用归并排序。
计数排序应用场景
计数排序需要占用大量空间,它仅适用于数据比较集中的情况。比如 [0100],[1000019999] 这样的数据。
基数排序 vs 计数排序 vs 桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
基数排序:根据键值的每位数字来分配桶
计数排序:每个桶只存储单一键值
桶排序:每个桶存储一定范围的数值
场景选择:
数据中包含有大量重复的元素:三路快排
数据的取值范围很小,数据集中:计数排序
数据是否需要稳定排序:归并排序,快排不稳定不可以
数据的存储状况:链表存储的采用快排,其他采用归并排序















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









