







一、scrapy框架工作大致流程
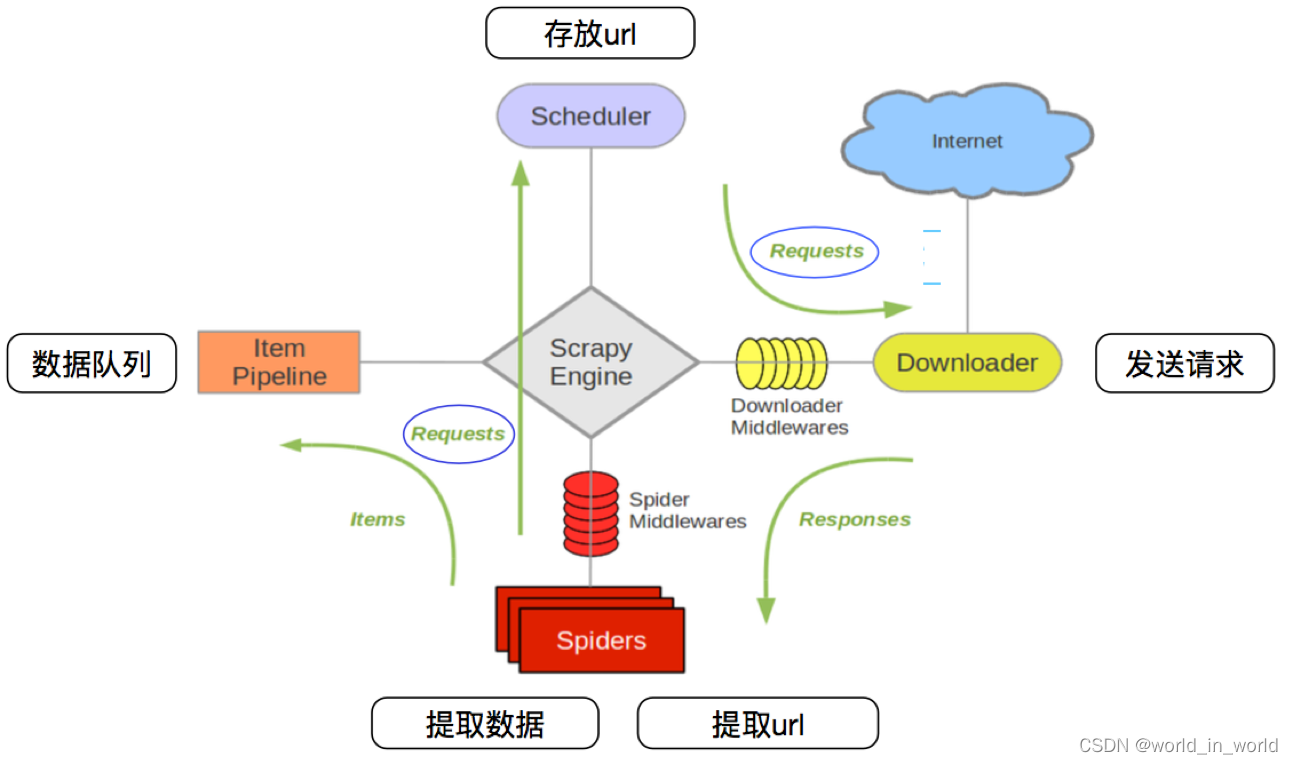
爬虫文件将url构造成request对象,发送给引擎,引擎将request对象发送给调度器,调度器处理引擎发送过来的request对象,将request对象储存到队列,再将request对象发送给引擎,引擎将request对象经过下载中间件发送给下载器,(下载中间件可以拦截修改request对象和response对象,返回None,或request对象,或response对象),下载器发送网络请求并获取response对象,并将response对象经过下载中间件发送给引擎,引擎将response对象经过爬虫中间件发送给爬虫文件,(爬虫中间件可以拦截修改response对象和request对象,返回request对象,或response对象),爬虫文件对response对象进行数据解析,将目标数据构造成item对象,将url构造成request对象,并yield,发送给引擎,引擎检测到如果是request对象就发送给调度器,如果是item对象就发送给管道,管道处理和存储目标数据。scrapy是一个异步多线程框架,由引擎统一调度。
二、虚拟环境
创建python虚拟环境
D:\App_Install\Python 3.7.5 -m venv D:\Projects\venv\环境名
激活指定虚拟环境
activate 环境名
安装scrapy框架
pip install scrapy==2.5.0
退出指定虚拟环境
deactivate 环境名
删除指定虚拟环境
直接删除对应的文件夹
三、scrapy项目
切换环境
在终端创建scrapy项目
scrapy startproject projectname
在终端创建爬虫文件
cd projectname
scrapy genspider spidername 域名
在items.py中定义字段
name = scrapy.Field()
title = scrapy.Field()
……
……
在settings.py中设置
更改:
ROBOTSTXT_OBEY = False
打开注释,更改:
USER_AGENT = 'scrapy_one (+http://www.yourdomain.com)'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
······· ······ ······ ······
}
通过管道储存数据,打开注释,更改:
ITEM_PIPELINES = {
'scrapy_one.pipelines.ScrapyOnePipeline': 300,
}
打开注释,更改:
DOWNLOADER_MIDDLEWARES = {
'scrapy_one.middlewares.ScrapyOneDownloaderMiddleware': 543,
}
添加:
LOG_LEVEL = 'WARNING' # 设置等级为DEBUG、INFO、WARNING、ERROR、CRITICAL的日志显示
LOG_FILE = './log.txt' # 将日志信息全部记录到log.txt文件中
异步报错TypeError: ProactorEventLoop is not supported, got: <ProactorEventLoop running=False closed=False debug=False> 添加:
import asyncio
if hasattr(asyncio, "WindowsSelectorEventLoopPolicy"):
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
在终端运行爬虫文件
scrapy crawl spidername [--nolog]
直接运行爬虫文件.py
from scrapy.items import ScrapyOneItem
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute('scrapy crawl spidername'.split())
# 通过scrapy框架内置方法将数据储存为json、csv,需先关闭管道
cmdline.execute('scrapy crawl spidername -o xxx.json -s FEED_EXPORT_ENCODING="utf-8"'.split())
cmdline.execute('scrapy crawl spidername -o xxx.csv -s FEED_EXPORT_ENCODING="utf-8"'.split())
在pipelines.py中编写
# 只在爬虫开启时,自动调用一次
def open_spider(self, spider):
pass
def process_spider(self, item, spider):
return item
# 只在爬虫关闭时,自动调用一次
def close_spider(self, spider):
pass
在middlewares.py中更改
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
四、注意点
版本冲突AttributeError: module 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD' 安装:
pip install cryptography==3.4.8
pip install pyOpenSSL==21.0.0
yield:
后面只能接 BaseItem, Request, dict, None
response对象属性:
url, status, body, text, encoding, request, selector, xpath, css, urljoin等
request对象属性:
url, callback, method, headers, body, cookies, meta, encoding, dont_filter等
meta参数:
是一个字典,有两个固定的键:proxy, download_timeout,分别设置代理和请求超时时间
五、爬虫事件监控
可视化管理工具(以ScrapeOps为例)
在终端中安装
pip install scrapeops-scrapy
在settings.py中设置
添加:
SCRAPEOPS_API_KEY = '你的密钥'
打开注释,添加:
EXTENSIONS = {
'scrapeops_scrapy.extension.ScrapeOpsMonitor': 500,
}
打开注释,添加:
DOWNLOADER_MIDDLEWARES = {
'scrapeops_scrapy.middleware.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
发送邮箱提醒
在settings.py中设置
添加修改:
EXTENSIONS = {
'scrapy.extensions.statsmailer.StatsMailer': 500,
}
STATSMAILER_RCPTS = ['你的邮箱']
MAIL_FROM = '你的邮箱'
MAIL_HOST = 'smtp.qq.com'
MAIL_PORT = 465
MAIL_USER = '你的邮箱'
MAIL_PASS = '你的授权码'
MAIL_SSL = True
在爬虫文件.py中编写
from scrapy.extensions.statsmailer import MailSender
def start_requests(self):
self.emailer = MailSender.from_settings(self.settings)
def close(self, spider, reason): # 关闭爬虫时,框架会自动调用该方法
return self.emailer.send(to=['你的邮箱', '你的邮箱', ……], subject='邮件标题', body='爬虫结束原因:' + reason)
六、案例
一、
items.py文件
import scrapy
class JvchaoItem(scrapy.Item):
announcementTime = scrapy.Field()
announcementTitle = scrapy.Field()
announcementTypeName = scrapy.Field()
secCode = scrapy.Field()
secName = scrapy.Field()爬虫.py文件
import scrapy
import time
from scrapyone.items import JvchaoItem
from scrapy import cmdline
from scrapy.extensions.statsmailer import MailSender
class JvchaoSpider(scrapy.Spider):
name = 'jvchao'
allowed_domains = ['www.cninfo.com.cn']
# start_urls = ['http://www.cninfo.com.cn/']
def start_requests(self):
self.emailer = MailSender.from_settings(self.settings)
base_url = 'http://www.cninfo.com.cn/new/disclosure'
for i in range(1, 12):
data = {
"column": "szse_latest",
"pageNum": f"{i}",
"pageSize": "30",
"sortName": "",
"sortType": "",
"clusterFlag": "true"
}
# yield scrapy.Request(base_url, method='POST', body=data, callback=self.parse)
yield scrapy.FormRequest(base_url, formdata=data, callback=self.parse)
def parse(self, response, **kwargs):
item = JvchaoItem()
dic = response.json()
for i in dic['classifiedAnnouncements']:
timestamp = i[0]['announcementTime']
item['announcementTime'] = time.strftime('%Y-%m-%d', time.localtime(timestamp / 1000))
item['announcementTitle'] = i[0]['announcementTitle']
item['announcementTypeName'] = i[0]['announcementTypeName']
item['secCode'] = i[0]['secCode']
item['secName'] = i[0]['secName']
print(item)
yield item
def close(self, spider, reason): # 参数reason,表示当前爬虫中断的原因
intro = '巨潮资讯数据爬取'
return self.emailer.send(to=['xxx'], subject=intro, body='爬虫结束原因:' + reason)
if __name__ == '__main__':
cmdline.execute('scrapy crawl jvchao'.split())middlewares.py文件
from scrapyone.settings import USER_AGENT_LIST
import random
import scrapy
# 写完记得打开中间件
class UseragentDownloaderMiddleware:
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
return Nonepipelines.py文件
import pymysql
# 写完后记得打开管道
class ScrapyoneMysqlPipeline:
def open_spider(self, spider):
if spider.name == 'jvchao':
self.db = pymysql.connect(user='root', password='12345', host='localhost', database='python', port=3306, charset='utf8')
self.cursor = self.db.cursor()
create_table_sql = """
create table if not exists jvchao(
id int unsigned primary key auto_increment,
announcementTime varchar(20) not null ,
announcementTitle varchar(500) not null,
announcementTypeName varchar(50) not null,
secCode varchar(10),
secName varchar(50)
)
"""
try:
self.cursor.execute(create_table_sql)
print('表创建成功')
except Exception as e:
print('表创建失败')
def process_item(self, item, spider):
if spider.name == 'jvchao':
insert_sql = """
insert into jvchao(id, announcementTime, announcementTitle, announcementTypeName, secCode, secName)
values(%s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(insert_sql, (0, item['announcementTime'], item['announcementTitle'], item['announcementTypeName'], item['secCode'], item['secName']))
self.db.commit()
print('保存成功')
except Exception as e:
self.db.rollback()
print('保存失败', repr(e))
return item # 记得每次 return item
def close_spider(self, spider):
if spider.name == 'jvchao':
self.db.close()settings.py文件
# Scrapy settings for scrapyone project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapyone'
SPIDER_MODULES = ['scrapyone.spiders']
NEWSPIDER_MODULE = 'scrapyone.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
import random
DOWNLOAD_DELAY = random.randint(6, 9) / 10
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapyone.middlewares.ScrapyoneSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapyone.middlewares.UseragentDownloaderMiddleware': 543,
# 'scrapyone.middlewares.ProxyDownloaderMiddleware': 544,
# 'scrapyone.middlewares.TengxunSeleniumDownloaderMiddleware': 545,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'scrapy.extensions.statsmailer.StatsMailer': 500,
}
STATSMAILER_RCPTS = ['xxx']
MAIL_FROM = 'xxx'
MAIL_HOST = 'smtp.qq.com'
MAIL_PORT = 465
MAIL_USER = 'xxx'
MAIL_PASS = 'yyy'
MAIL_SSL = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapyone.pipelines.ScrapyoneMysqlPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# LOG_LEVEL = 'INFO'
# LOG_FILE = './douban_log.txt'
USER_AGENT_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]二、selenium自动化
items.py文件
import scrapy
class TengxunItem(scrapy.Item):
title = scrapy.Field()
address = scrapy.Field()
category = scrapy.Field()
datetime = scrapy.Field()爬虫.py文件
import scrapy
from scrapy import cmdline
from scrapyone.items import TengxunItem
class TengxunSpider(scrapy.Spider):
name = 'tengxun'
allowed_domains = ['careers.tencent.com']
# start_urls = ['https://careers.tencent.com/search.html']
def start_requests(self):
for i in range(1, 12):
url = f'https://careers.tencent.com/search.html?index={i}'
yield scrapy.Request(url, callback=self.parse)
def parse(self, response, **kwargs):
divs = response.xpath('//div[@class="recruit-list"]')
for i in divs:
# item = {}
item = TengxunItem()
item['title'] = i.xpath('./a/h4[@class="recruit-title"]/text()').extract_first()
item['address'] = i.xpath('.//a/p[1]/span[2]/text()').extract_first()
item['category'] = i.xpath('./a/p[1]/span[3]/text()').extract_first()
if len(i.xpath('./a/p[@class="recruit-tips"]/span')) == 4:
item['datetime'] = i.xpath('./a/p[1]/span[4]/text()').extract_first()
else:
item['datetime'] = i.xpath('./a/p[1]/span[5]/text()').extract_first()
print(item)
yield item
if __name__ == '__main__':
cmdline.execute('scrapy crawl tengxun'.split())
middlewares.py文件
'''
腾讯中间件
'''
from scrapyone.settings import USER_AGENT_LIST
import random
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import scrapy
from scrapy import signals
class UseragentDownloaderMiddleware:
def process_request(self, request, spider):
ua = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
return None
class TengxunSeleniumDownloaderMiddleware:
def __init__(self):
self.browser = webdriver.Chrome()
self.browser.maximize_window()
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.close_browser, signal=signals.spider_closed)
return s
def process_request(self, request, spider):
self.browser.get(request.url)
wait = WebDriverWait(self.browser, 5)
try:
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'page-number')))
except:
self.browser.quit()
else:
body = self.browser.page_source
return scrapy.http.HtmlResponse(url=request.url, body=body, request=request, encoding='utf-8')
def close_browser(self):
self.browser.quit()
pipelines.py文件
import pymysql
# 写完后记得打开管道
class ScrapyoneMysqlPipeline:
if spider.name == 'tengxun':
self.db = pymysql.connect(user='root', password='12345', host='localhost', database='python', port=3306, charset='utf8')
self.cursor = self.db.cursor()
create_table_sql = """
create table if not exists tengxun(
id int unsigned primary key auto_increment,
title varchar(200) not null ,
address varchar(60) not null,
category varchar(60) not null,
datetime varchar(80)
)
"""
try:
self.cursor.execute(create_table_sql)
print('表创建成功')
except Exception as e:
print('表创建失败')
def process_item(self, item, spider):
if spider.name == 'tengxun':
insert_sql = """
insert into tengxun(id, title, address, category, datetime)
values(%s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(insert_sql, (0, item['title'], item['address'], item['category'], item['datetime']))
self.db.commit()
print('保存成功')
except Exception as e:
self.db.rollback()
print('保存失败', repr(e))
return item # 记得每次 return item
def close_spider(self, spider):
if spider.name == 'tengxun':
self.db.close()settings.py文件
# Scrapy settings for scrapyone project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'scrapyone'
SPIDER_MODULES = ['scrapyone.spiders']
NEWSPIDER_MODULE = 'scrapyone.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
import random
DOWNLOAD_DELAY = random.randint(6, 9) / 10
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'scrapyone.middlewares.ScrapyoneSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapyone.middlewares.UseragentDownloaderMiddleware': 543,
# 'scrapyone.middlewares.ProxyDownloaderMiddleware': 544,
'scrapyone.middlewares.TengxunSeleniumDownloaderMiddleware': 545,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapyone.pipelines.ScrapyoneMysqlPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# LOG_LEVEL = 'INFO'
# LOG_FILE = './douban_log.txt'
USER_AGENT_LIST = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









