








文 | 阿甘兄
发布 | 阿甘兄(blog: https://yanglinwei.blog.csdn.net)
一、前言
声明:本文为《Kubernetes权威指南:从Docker到Kubernetes实践全接触(第5版)》的读书笔记
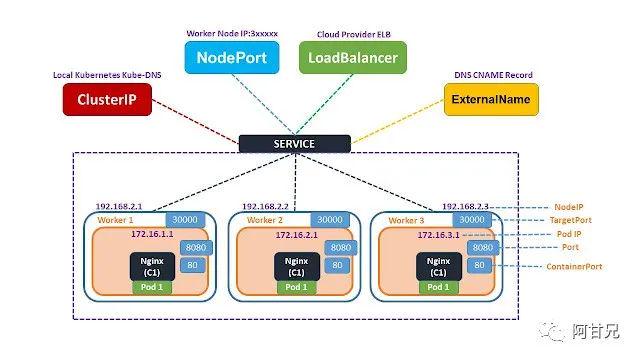
Service 主要用于提供网络服务,通过Service的定义,能够 为客户端应用提供稳定的访问地址(域名或IP地址)和负载均衡功能,以及屏蔽后端Endpoint的变化,这也是Kubernetes实现微服务的核心资源。
本文详细讲解下Service的相关概念及原理。
二、Service的概念
下面演示在没有Service之前,是如何访问一个多副本的应用容器组提供的服务。
以Tomcat容器为例,其Deployment资源文件定义如下:
apiVersion: apps/v1kind: Deploymentmetadata: name: webappspec: replicas: 2 selector: matchLabels: app: webapp template: metadata: labels: app: webapp spec: containers: - name: webapp image: kubeguide/tomcat-app:v1 ports: - containerPort: 8080创建完成后,查看每个pod的ip地址:
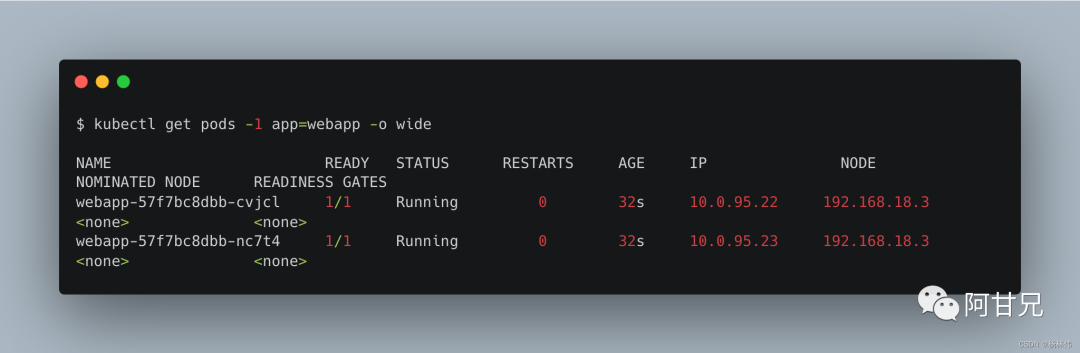
客户端应用可以直接通过这两个Pod的IP地址和端口号8080访问Web服务,例如:curl 10.0.95.22:8080 :
但是,提供服务的容器应用通常是分布式的,通过多个Pod副本共同提供服务(还需要考虑扩缩容的问题),要实现动态感知服务后端实例的变化,会大大增加客户端系统实现的复杂度,为了解决这个问题,Kubernetes引入 Service资源类型 。
Service实现的是微服务架构中的几个核心功能:全自动的服务注册、服务发现、 服务负载均衡等。
2.1 创建Service(使用kubectl expose命令创建)
命令如下:
kubectl expose deployment webapp service/webapp exposed查看新创建的Service,可以看到系统为它分配了一个虚拟IP地址(ClusterIP 地址),Service的端口号则从Pod中的containerPort复制而来:
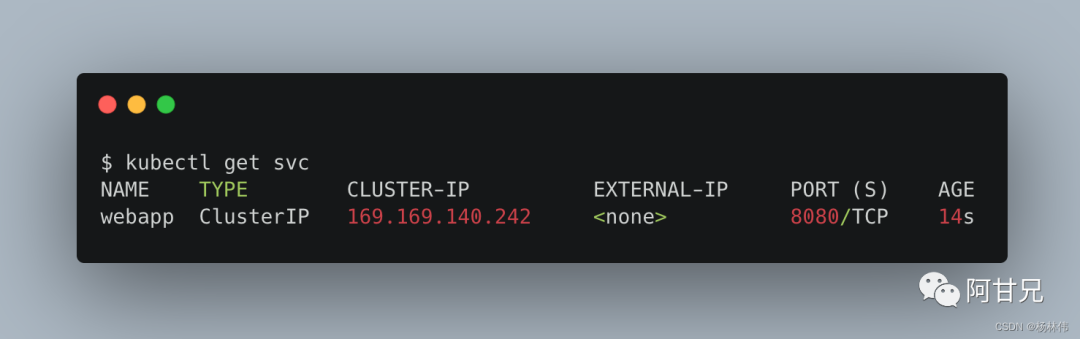
通过curl 169.169.140.242:8080 也是可以访问的。访问时,会被自动负载分发到了后端两个Pod之一:10.0.95.22:8080或10.0.95.23:8080。
2.2 创建Service(资源文件的方式创建)
除了使用命令,还可以使用yaml资源文件的方式来创建:
apiVersion: v1kind: Servicemetadata: name: webappspec: ports: - protocol: TCP port: 8080 targetPort: 8080 selector: app: webappService定义中的关键字段是ports和selector:
ports:定义部分指定了Service本身的端口号为8080;
targetPort:指定后端Pod的容器端口号;
selector:定义部分设置的是后端Pod所拥有的 label:app=webapp。
使用kubectl create命令创建后,能看到和使用kubectl expose命令创建Service的效果一样。
2.3 Endpoint
一个Service对应的 “后端” 由Pod的IP和容器端口号组成,这在k8s系统中称为Endpoint。
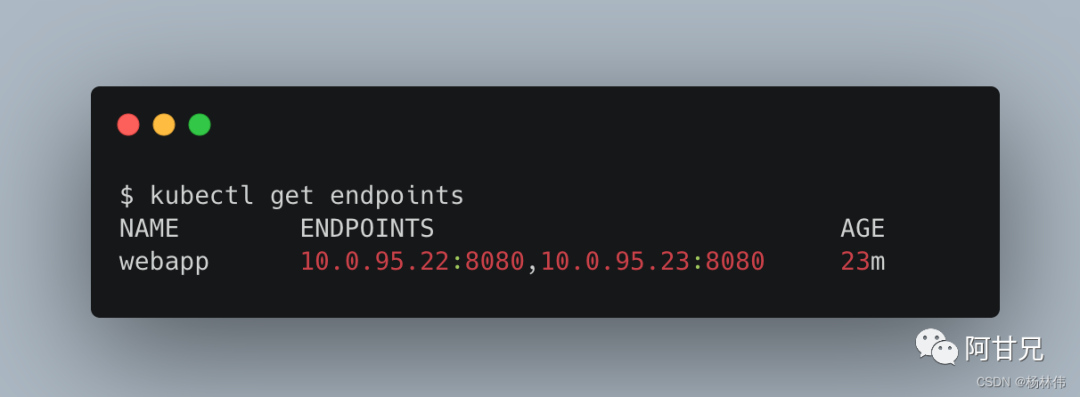
可以通过kubectl descirbe svc 命令查看Endpoint列表,如:
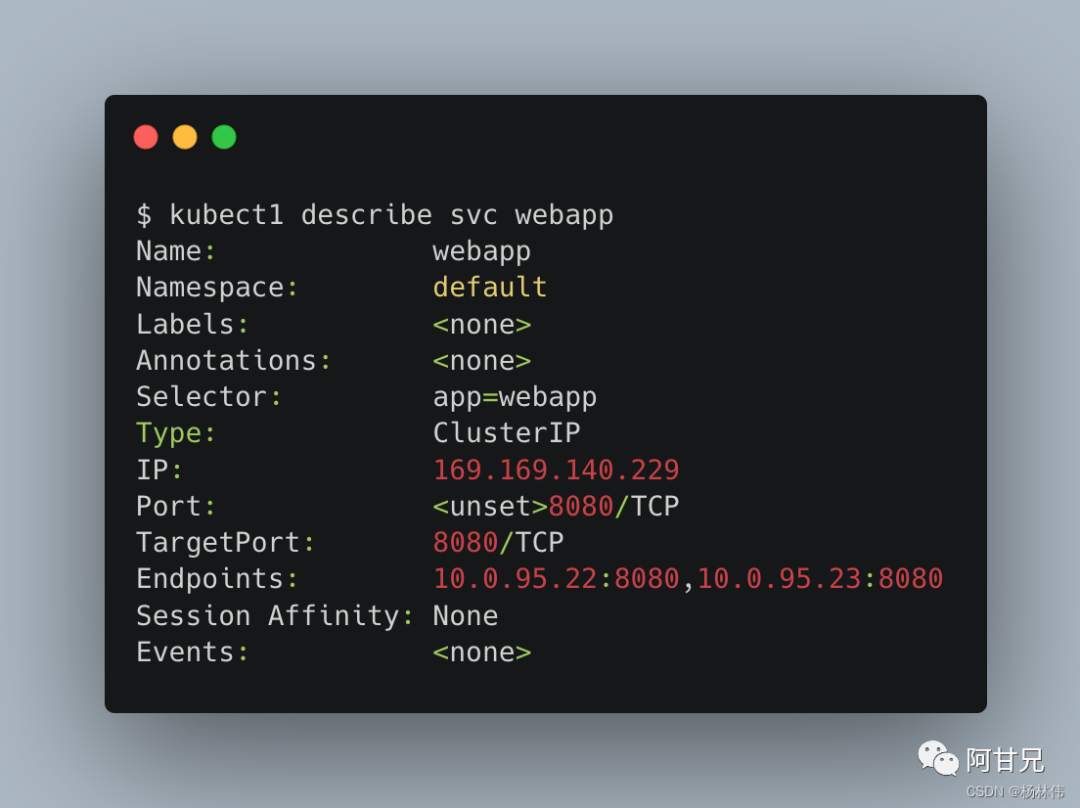
Kubernetes自动创建了与Service关联的Endpoint资源对象,这可以通过查询Endpoint对象命令行查看:
三、负载均衡机制
当一个 Service 对象在 Kubernetes 集群中被定义出来时,集群内的客户端应用就可以通过服务IP访问到具体的Pod容器提供的服务了。
从服务IP到后端Pod的负载均衡机制,则是由每个Node上的kube-proxy负责实现的。通过Service的负载均衡机制,Kubernetes实现了一种分布式应用的统一入口,免去了客户端应用获知后端服务实例列表和变化的复杂度。
kube-proxy的代理模式
目前kube-proxy提供了以下代理模式(通过启动参数--proxy-mode设置):
模式 | 描述 |
userspace模式 | 用户空间模式,由kube-proxy完成代理的实现,效率最低,不再推荐使用 |
iptables模式 | kube-proxy通过设置Linux Kernel的iptablesi规则,实现从Service到后端Endpoint列表的负载分发规则,效率很高。 但是,如果某个后端Endpoint在转发时不可用,此次客户端请求就会得到失败的响应,相对于 userspace模式来说更不可靠,此时应该通过为Pod设置readinessprobe(服务可用性健康检查)来保证只有达到ready状态的Endpoint才会被设置为Service的后端Endpoint。 |
ipvs模式 | 在Kubernetes1.11版本中达到Stable阶段,kube-proxy通过设置Linux Kernel的netlink接口设置IPVS规则,转发效率和支持的吞吐率都是最高的。 ipvs模式要求Linux Kernel启用IPVS模块,如果操作系统未启用IPVS内核模块,kube-proxy则会自动切换至iptables模式。同时ipvs模式支持更多的负载均衡策略,如下所述:
|
kernelspace模式 | Windows Server上的代理模式 |
会话保持模式
Service支持通过设置sessionAffinity实现基于客户端IP的会话保持机制,即:首次将某个客户端来源IP发起的请求转发到后端的某个Pod上,之后从相同的客户端 IP发起的请求都将被转发到相同的后端Pod上。
配置参数为 service.spec.sessionAffinity,也可以设置会话保持的最长时间(service.spec.sessionAffinityConfig.clientIP.timeoutSeconds),例如下面的服务将会话保持时间设置为10800s(3h):
apiVersion: v1kind: Servicemetadata: name: webappspec: sessionAffinity: ClientIP sessionAffinityConfig: clientIP: timeoutSecondes: 10080 ports: - protocol: TCP port: 8080 targetPort: 8080 selector: app: webapp四、Service的多端口设置
一个容器应用可以提供多个端口的服务,在Service的定义中也可以相应地设置多个端口号。
在下面的例子中,Service设置了两个端口号来分别提供不同的服务,如web服务和management服务(下面为每个端口号都进行了命名,以便区分):
apiversion: v1kind: Servicemetadata: name: webappspec:ports:- port: 8080 targetPort: 8080 name: web- port: 8005 targetPort: 8005 name: managementselector:app: webapp另一个例子是同一个端口号使用的协议不同,如TCP和UDP,也需要设置为多个端口号来提供不同的服务:
apiVersion: v1kind: Servicemetadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" kubernetes.io/name: "KubeDNS"spec: selector: k8s-app: kube-dns clusterIP: 169.169.0.100 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP五、将外部服务定义为Service
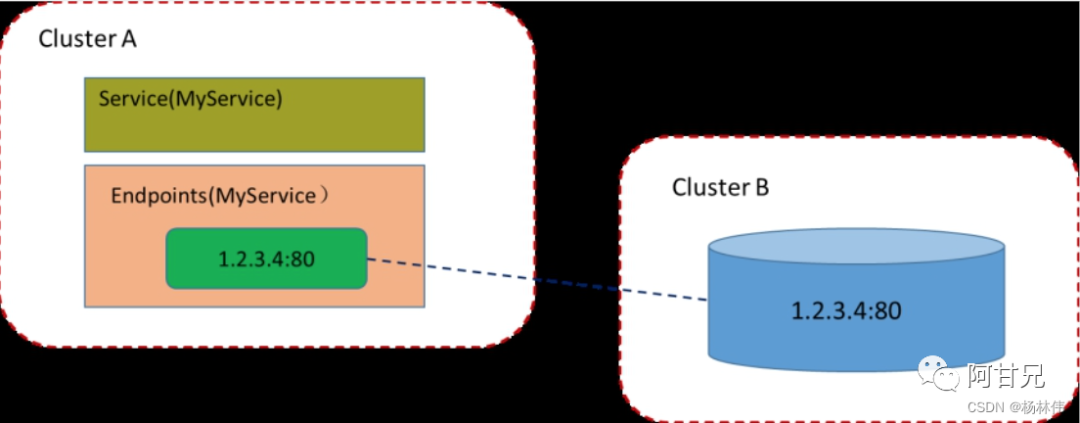
普通的Service通过Label Selector对后端Endpoint列表进行了一次抽象,如果后端的Endpoint不是由Pod副本集提供的,则Service还可以抽象定义任意其他服务,将一个Kubernetes集群外部的已知服务定义为Kubernetes内的一个Service, 供集群内的其他应用访问。
场景
常见的应用场景包括:
已部署的一个集群外服务:例如数据库服务、缓存服务等;
其他Kubernetes集群的某个服务;
迁移过程中对某个服务进行Kubernetes内的服务名访问机制的验证。
Service指向外部服务如下图所示:
定义
对于这种应用场景,用户在创建Service资源对象时不设置Label Selector(后端Pod也不存在),同时再定义一个与Service关联的Endpoint资源对象,在Endpoint中设置外部服务的IP地址和端口号,例如:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: ports: - protocol: TCP port: 80 targetPort: 80-----------apiversion: v1kind: Endpointsmetadata: name: my-servicesubsets:- addresses: - IP: 1.2.3.4 ports: - port: 80六、将Service暴露给外部集群
Kubernetes为Service创建的ClusterIP地址是对后端Pod列表的一层抽象,对于集群外部来说并没有意义,但有许多Service是需要对集群外部提供服务的,Kubernetes提供了多种机制将Service暴露出去,供集群外部的客户端访问。
这可以通过Service资源对象的类型字段“type”进行设置。
目前Service的类型如下:
类型 | 描述 |
ClusterIP | Kubernetes默认会自动设置Service的虚拟IP地址,仅可被集群内部的客户端应用访问。当然,用户也可手工指定一个ClusterIP地址,不过需要确保该IP在Kubernetes集群设置的ClusterIP地址范围内(通过kube-apiserver 服务的启动参数-service-cluster--ip-range设置),并且没有被其他Service使用 |
NodePort | 将Service的端口号映射到每个Node的一个端口号上,这样集群中的任意Node都可以作为Service的访问入口地址,即NodeIP:NodePort |
LoadBalancer | 将Servicel映射到一个已存在的负载均衡器的IP地址上, 通常在公有云环境中使用 |
ExternalName | 将Service映射为一个外部域名地址,通过externalName字段进行设置 |
NodePort类型
下面的例子设置Service的类型为NodePort,并且设置具体的nodePort端口号为8081:
apiVersion: v1kind: Servicemetadata: name: webappspec:type: NodePortports:- port: 8080 targetPort: 8080 nodePort: 8081selector: app: webapp使用kubectl create创建了Service之后,就可以通过任意一个Node的IP地址+ NodePort 8081端口号 访问服务了。
另外,如果用户在Service定义中不设置具体的nodePort端口号,则Kubernetes会自动分配一个NodePort范围内的可用端口号。
在默认情况下,Node的kube-proxy会在全部网卡(0.0.0.0)上绑定NodePort端口号。在很多数据中心环境中,一台主机会配置多块网卡,作用各不相同(例如:存在业务网卡和管理网卡等)。
从Kubernetes1.10版本开始,kube-proxy可以通过设置特定的IP地址将NodePort绑定到特定的网卡上,而无须绑定在全部网卡上, 其设置方式为配置启动参数 “-nodeport-addresses”,指定需要绑定的网卡IP地址,多个地址之间使用逗号分隔。
例如:仅在10.0.0.0和192.168.18.0对应的网卡上绑定NodePort端口号,对其他IP地址对应的网卡不会进行绑定,配置如下:
--nodeport-addresses=10.0.0.0/8,192.168.18.0/24LoadBalance类型
通常在公有云环境中设置Service的类型为 “LoadBalancer‘” ,可以将Service映射到公有云提供的某个负载均衡器的IP地址上,客户端通过负载均衡器的IP和Service的端口号就可以访问到具体的服务,无须再通过kube-proxy提供的负载均衡机制进行流量转发。公有云提供的LoadBalancer可以直接将流量转发到后端Pod上,而负载分发机制依赖于公有云服务商的具体实现。
举例:
apiVersion: v1kind: Servicemetadata: name: my-servicespec:type: LoadBalancer selector: app: MyApp ports: - protocol: TCP port: 80 targetPort: 9376 clusterIP: 10.0.171.239在服务创建成功之后,云服务商会在Service的定义中补充LoadBalancer的IP 地址(status字段):
status: loadBalancer: ingress: - ip:192.0.2.127ExternalName类型
ExternalName类型的服务用于将集群外的服务定义为Kubernetes的集群的Service,并且通过externalName字段指定外部服务的地址,可以使用域名或IP格式,集群内的客户端应用通过访问这个Service就能访问外部服务了。
这种类型的Service没有后端Pod,所以无须设置Label Selector。例如:
apiVersion: v1kind: Servicemetadata: name: my-service namespace: prodspec: type: ExternalName externalName: my.database.example.com在本例中设置的服务名为my-service,所在namespace为prod,客户端访问服务地址my-service.prod.svc.cluster.local时,系统将自动指向外部域名my.database.example.com。
七、Service支持的网路协议
目前Service支持的网络协议如下:
类型 | 描述 |
TCP | Service的默认网络协议,可用于所有类型的Service |
UDP | 可用于大多数类型的Service,LoadBalancer类型取决于云服务商对UDP的支持 |
HTTP | 取决于云服务商是否支持HTTP和实现机制 |
PROXY | 取决于云服务商是否支持HTTP和实现机制 |
SCTP | 从Kubernetes1.12版本引入,到1.19版本时达到Beta阶段,默认启用,如需关闭该特性,则需要设置kube-apiserver的启动参数--feature- gates=-SCTPSupport=-false进行关闭 |
Kubernetes从1.17版本开始,可以为Service和Endpoint资源对象设置一个新的段"AppProtocol",用于标识后端服务在某个端口号上提供的应用层协议类型,例如HTTP、HTTPS、SSL、DNS等。
要使用AppProtocol,需要设置kube-apiserver的启动参数--feature-gates=ServiceAppProtocol=true进行开启,然后在Service或Endpoint的定义中设置AppProtocol字段指定应用层协议的类型,例如:
apiVersion: v1kind: Servicemetadata: name: webapp spec: ports: - port: 8080 targetPort: 8080 AppProtocol: HTTP selector: app: webapp八、k8s的服务发现机制
服务发现机制指客户端应用在一个Kubernetes集群中如何获知后端服务的访问地址,一共有两种方式,下面来讲讲。
环境变量的方式
在一个Pod运行起来的时候,系统会自动为其容器运行环境注入所有集群中有效Service的信息。
Service的相关信息包括服务IP、服务端口号、各端口号相关的协议等,通过{SVCNAME_SERVICE_HOST}和{SVCNAME_SERVICE_PORT}格式进行设置。
其中,SVCNAME的命名规则为:将Service的name字符串转换为全大写字母,将中横线“”替换为下划线 “_”,以webapp服务为例:
apiVersion: v1kind: Servicemetadata: name: webappspec: ports: - protocol: TCP port: 8080 targetPort: 8080 selector: app: webapp在一个新创建的Pod(客户端应用)中,可以看到系统自动设置的环境变量如下:
WEBAPP_SERVICE_HOST=169.169.81.175WEBAPP_SERVICE_PORT=8080WEBAPP_P0RT=tcp://169.169.81.175:8080WEBAPP_P0RT_8080_TCP=tcp://169.169.81.175:8080WEBAPP_PORT_8080_TCP_PROTO=tcpWEBAPP_PORT_8080_TCP_PORT=8080WEBAPP_PORT_8080_TCP_ADDR=169.169.81.175然后,客户端应用就能够根据Service相关环境变量的命名规则,从环境变量中获取需要访问的目标服务的地址了,例如:
curl http://{WEBAPP_SERVICE_HOST}:${WEBAPP_SERVICE_HOST}DNS的方式
Service在Kubernetes系统中遵循DNS命名规范,Service的DNS域名表示方法 为<servicename>.<namespace>.svc.<clusterdomain>,其中:
servicename:为服务的名称;
namespace:为其所在namespace的名称;
clusterdomain:为Kubernetes集群设置的域名后缀(例如cluster.local),服务名称的命名规则遵循RFC 1123规范的要求。
另外,Service定义中的端口号如果设置了名称(name),则该端口号也会拥有一个DNS域名,在DNS服务器中以SRV记录的格式保存:_<portname>._<protocol>.<servicename>.<namespace>.svc. <clusterdomain>,其值为端口号的数值。
当Service以DNS域名形式进行访问时,就需要在Kubernetes集群中存在一个DNS服务器来完成域名到ClusterIP地址的解析工作了,经过多年的发展,目前由CoreDNS作为Kubernetes集群的默认DNS服务器提供域名解析服务。
以webapp服务为例,将其端口号命名为“http”:
apiversion: v1kind: Servicemetadata: name: webappspec: ports: - protocol: TCP port: 8080 targetPort: 8080 name: http selector: app: webapp解析名为 "http" 端口的DNS SRV记录
"_http._tcp.webapp.default.svc.cluster.local'",可以查询到其端口号的值为8080。

九、Headless Service的概念与应用
在某些应用场景中,客户端应用不需要通过Kubernetes内置Service实现的负载均衡功能,或者需要自行完成对服务后端各实例的服务发现机制,或者需要自行实现负载均衡功能,此时可以通过创建一种特殊的名为 “Headless‘”的服务来实现。
Headless Service的概念是这种服务没有入口访问地址(无ClusterIP地址), kube-proy不会为其创建负载转发规则,而服务名(DNS域名)的解析机制取决于该Headless Service是否设置了Label Selector。
已设置Label Selector
如果Headless Service设置了Label Selector,Kubernetes则将根据Label Selector查询后端Pod列表,自动创建Endpoint列表,将服务名(DNS域名)的解析机制设置为:当客户端访问该服务名时,得到的是全部Endpoint列表(而不是一个确定的IP地址)。
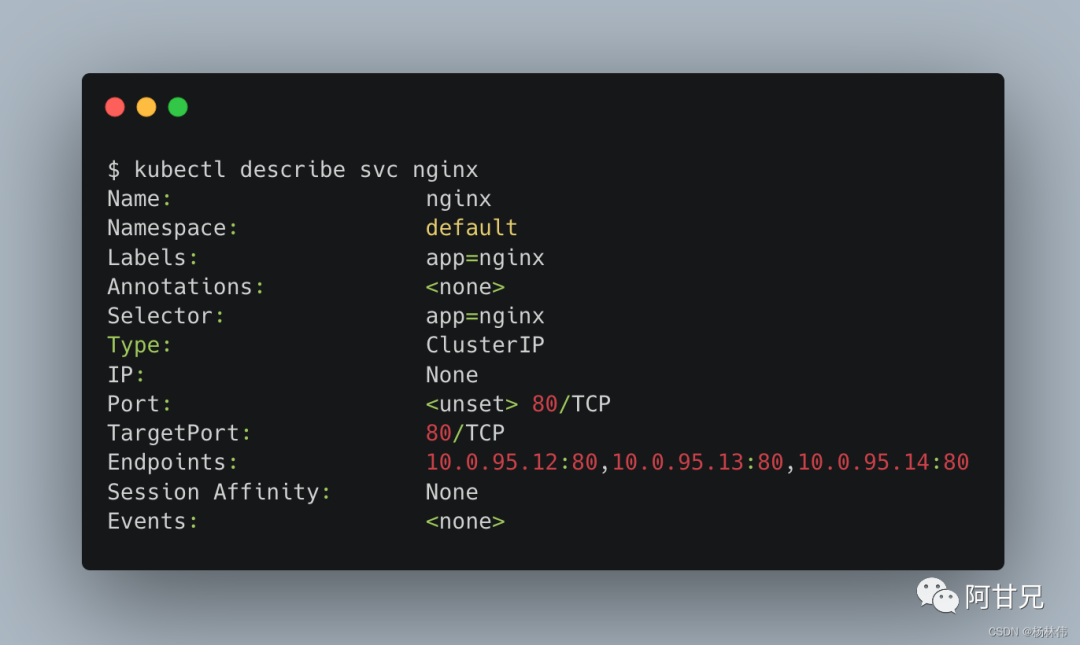
以下面的Headless Service为例,其设置了Label Selector:
apiversion: v1kind: Servicemetadata: name: nginx labels: app: nginxspec: ports: - port: 80 clusterIP: None selector: app: nginx使用kubectl create命令创建完之后,可以查看该Headless Service的详细信息,可以看到后端的Endpoint列表:
用nslookup工具对Headless Service名称尝试域名解析,将会看到DNS系统返回的全部Endpoint的IP地址,例如:
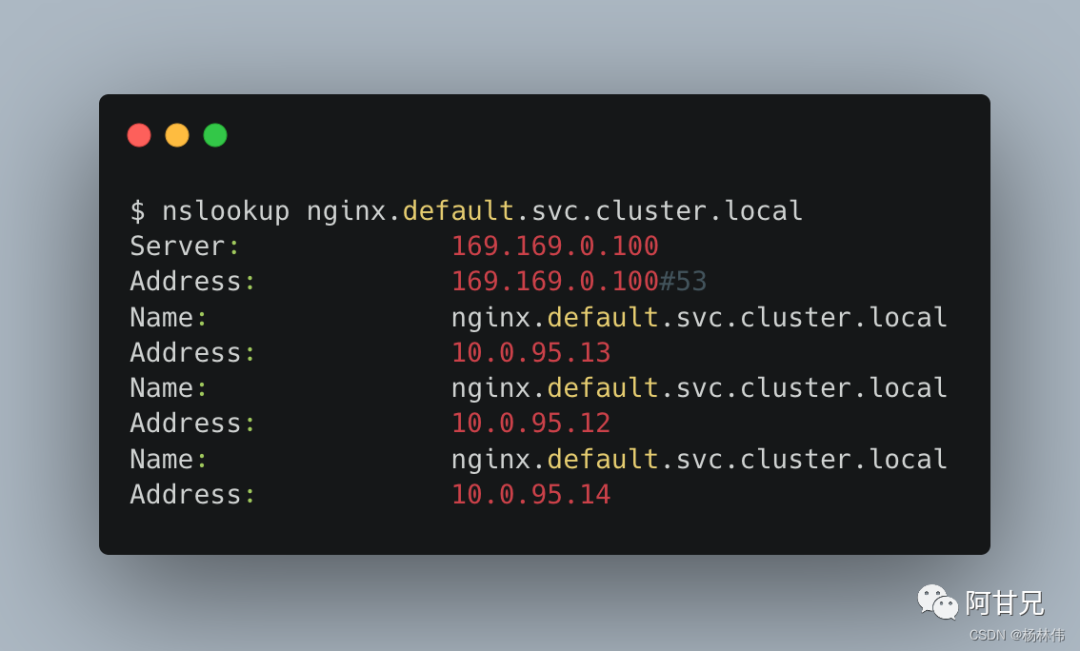
当客户端通过DNS服务名 "nginx"(或其FQDN全限定域名"nginx.<namespace>.svc.cluster.local")和服务端口号访问该Headless服务(URL=nginx:80)时,将得到Service后端Endpoint列表"10.0.95.12:80,10.0.9513:80,10.0.95.14:80",然后由客户端程序自行决定如何操作,例如:通过轮询机制访问各个Endpoint。
没设置Label Selector
如果Ieadless Service没有设置Label Selector,则Kubernetes将不会自动创建对应的Endpoint列表。
DNS系统会根据下列条件尝试对该服务名设置DNS记录:
如果Servicel的类型为ExternalName,则对服务名的访问将直接被DNS系统转换为Service设置的外部名称(externalName);
如果系统中存在与Service同名的Endpoint定义,则服务名将被解析为Endpoint定义中的列表,适用于非ExternalName类型的Service。
十、端点分片和服务拓扑
S ervice的后端是一组Endpoint列表,为客户端应用提供了极大的便利。
问题:随着集群规模的扩大及Service数量的增加,特别是Service后端Endpoint数量的增加,kube-proxy需要维护的负载分发规则(例如iptables规则或 ipvs规则)的数量也会急剧增加,导致后续对Service后端Endpoint的添加、删除 等更新操作的成本急剧上升。
举例:假设在Kubernetes集群中有10000个Endpoint运行在大约5000个Node上,则对单个Pod的更新将需要总计约5GB的数据传输,这不仅对集群内的网络带宽浪费巨大,而且对Master的冲击非常大,会影响Kubernetes集群的整体性能,在Deployment不断进行滚动升级操作的情况下尤为突出。
解决方式:使用端点分片(Endpoint Slices)机制。
EndpointSlice通过对Endpoint进行分片管理来实现降低Master和各Node之间的网络传输数据量及提高整体性能的目标。对于Deployment的滚动升级,可以实现仅更新部分Node上的Endpoint信息,Master与Node之间的数据传输量可以减少100倍左右,能够大大提高管理效率。
EndpointSlice根据Endpoint 所在Node的拓扑信息进行分片管理,如图所示:

Endpoint Slices要实现的第2个目标是为基于Node拓扑的服务路由提供支持,这需要与服务拓扑(Service Topology)机制共同实现。
10.1 端点分片
kubernetes从1.19版本开始,EndpointSplice机制以及EndpointSliceProxying是默认开启的:
通过设置kube-apiserver和kube-proxy服务的启动参数--feature-gates=“EndpointSlice=true“进行启用。kube-proxy默认仍然使用Endpoint对象,为了提高性能,可以设置 kube-proxy启动参数--feature-gates-=“EndpointSliceProxying=true“让kube-proxy 使用EndpointSlice,这样可以减少kube-proxy与master之间的网络通信并提高性能。
以一个3副本的webapp服务为例,Pod列表如下:
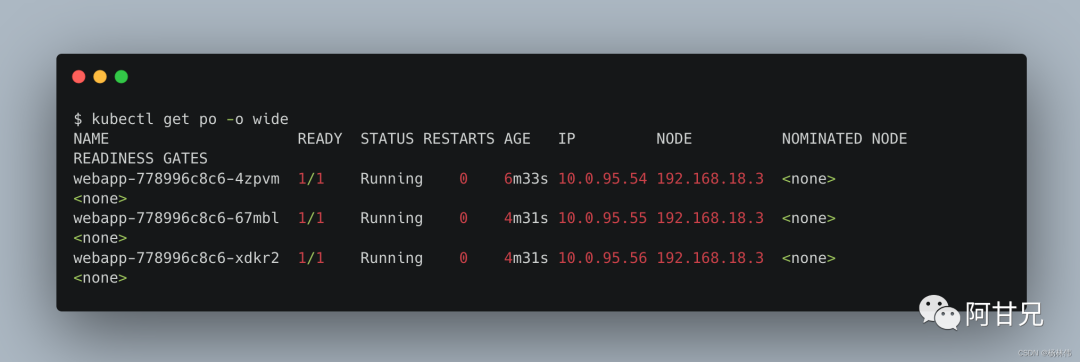
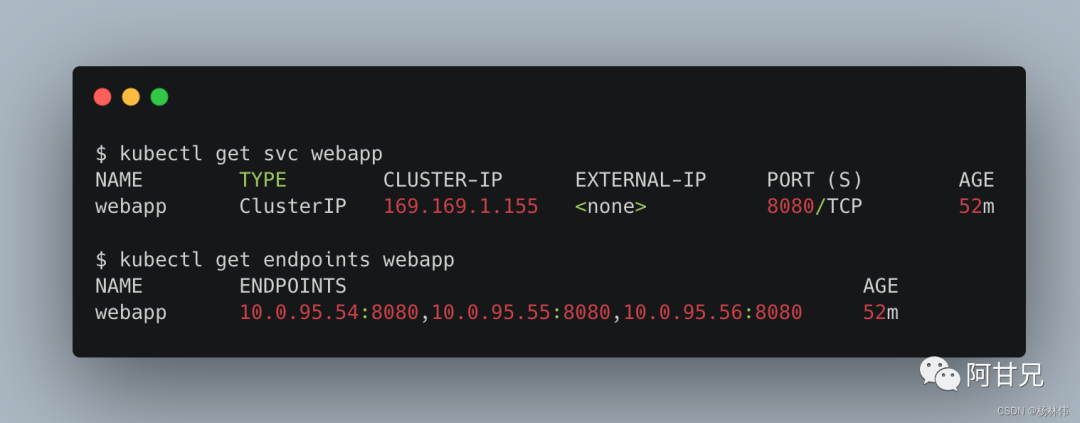
服务和Endpoint的信息如下:
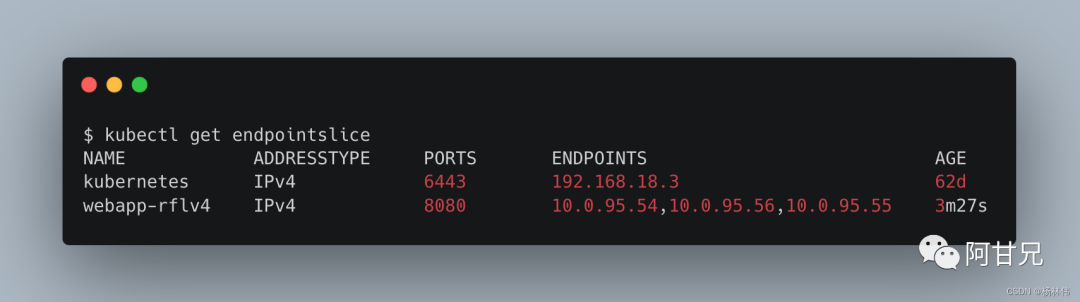
查看EndpointSlice,可以看到系统自动创建了一个名称前缀为“webapp-”的EndpointSlice:
查看EndpointSlice,可以看到系统自动创建了一个名称前缀为“webapp-”的EndpointSlice:
查看其详情信息,可以看到3个Endpoint的IP地址和端口信息,同时为Endpoint设置了Topology相关信息:
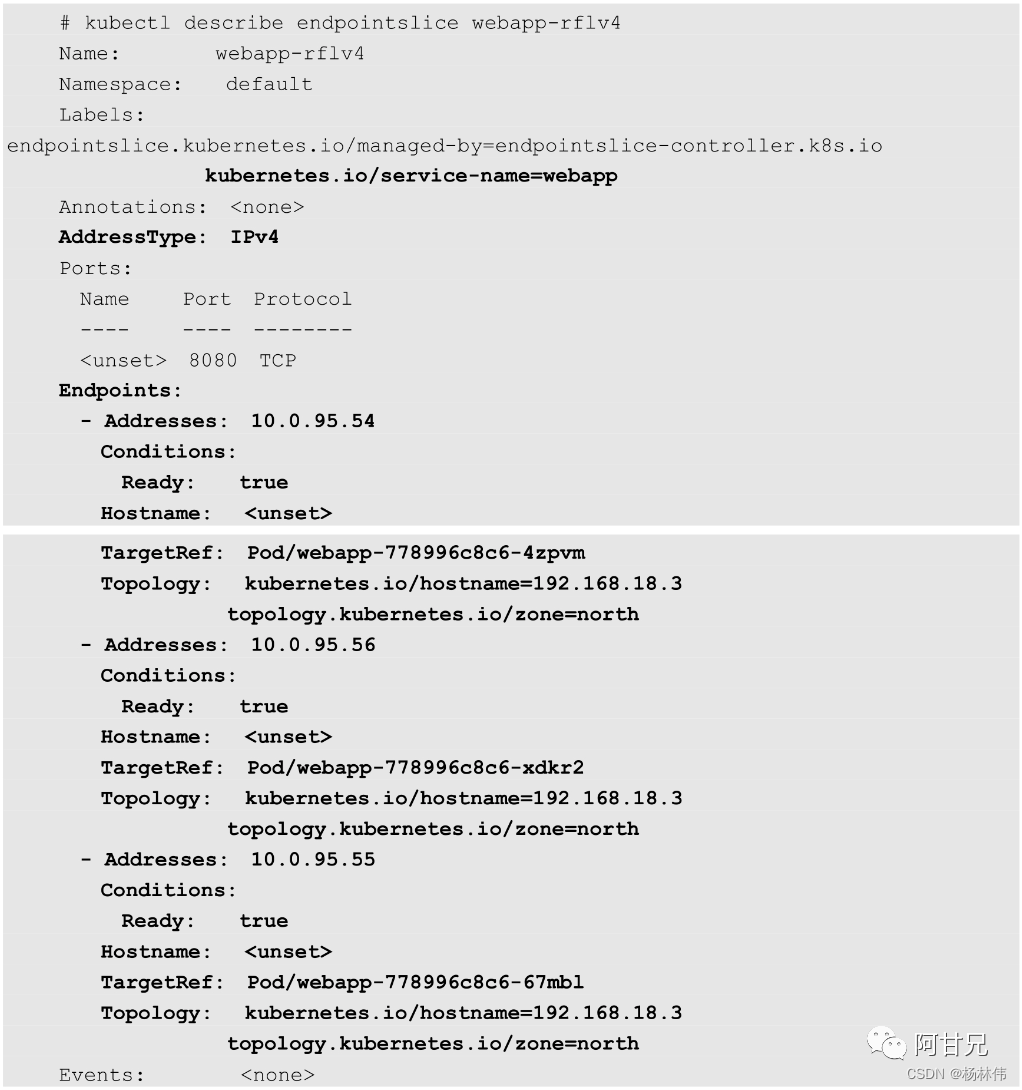
默认情况下,在由EndpointSlice控制器创建的EndpointSlice中最多包含100个Endpoint,如需修改,则可以通过kube-controller-manager服务的启动参数-- max-endpoints-per-slice设置,但上限不能超过1000。
EndpointSlice的关键信息如下:
配置项 | 描述 |
关联的服务名称 | 将EndpointSlice与Service的关联信息设置为一个标签kubernetes.io/service-name=webapp,该标签标明了服务名称 |
地址类型AddressType | 包括以下3种取值类型:
|
每个Endpoint的信息 | 在Endpoints列表中列出的每个Endpoint的信息:
目前EndpointSlice控制器自动设置的拓扑信息如下:
在大规模集群中,管理员应对不同地域或不同区域的Node设置相关的 topology标签,用于为Node设置拓扑信息. |
EndpointSlice的管理控制器 | 通过endpointslice.kubernetes.io/managed-by标签进行设置,用于存在多个管理控制器的应用场景中,例如某个Service Mesh管理工具也可以对EndpointSlice进行管理。为了支持多个管理工具对EndpointSlice同时进行管理并且互不干扰,可以通过endpointslice.kubernetes.io/managed--by标签设置管理控制器的名称,Kubernetes内置的EndpointSlice控制器自动设置该标签的值为endpointslice-controller.k8s.io,其他管理控制器应设置唯一名称用于标识. |
10.1.1 复制功能
EndpointSlice复制(Mirroring)功能:应用程序有时可能会创建自定义的Endpoint资源,为了避免应用程序在创建Endpoint资源时再去创建EndpointSlice资源,Kubernetes控制平面会 自动完成 将Endpoint资源复制为EndpointSlice资源的操作。
以下几种情况下,不会执行自动复制操作:
Endpoint资源设置了Label:endpointslice.kubernetes.io/skip-mirror=true;
Endpoint资源设置了Annotation:control-plane.alpha.kubernetes.io/leader;
Endpoint资源对应的Service资源不存在;
Endpoint:资源对应的Service资源设置了非空的Selector;
一个Endpoint资源同时存在IPv4和IPv6地址类型时,会被复制为多个EndpointSlice资源,每种地址类型最多会被复制为1000个EndpointSlice资源。
10.1.2 数据分布管理机制
如上例所示,我们可以看到每个EndpointSlice资源都包含一组作用于全部Endpoint的端口号(Ports)。如果Service定义中的端口号使用了字符串名称,则对于相同name的端口号,目标Pod 的targetPort可能是不同的,结果是EndpointSlice资源将会不同。这与Endpoint 资源设置子集(subset)的逻辑是相同的。
Kubernetes控制平面对于EndpointSlice中数据的管理机制是尽可能填满,但不会在多个EndpointSlice数据不均衡衡的情况下主动执行重新平衡(rebalance)操作,其背后的逻辑也很简单,步骤如下:
遍历当前所有EndpointSlice资源,删除其中不再需要的Endpoint,更新已更改的匹配Endpoint;
遍历第1步中已更新的EndpointSlice资源,将需要添加的新Endpoint填充进去;
如果还有新的待添加Endpoint,则尝试将其放入之前未更新的EndpointSlice中,或者尝试创建新的EndpointSlicez并添加。
重要的是,第3步优先考虑创建新的EndpointSlice而不是更新原EndpointSlice。例如,如果要添加l0个新的Endpoint,则当前有两个EndpointSlice各有5个剩余空间可用于填充,系统也会创建一个新的EndpointSlice用来填充这10个新Endpoint。换句话说,单个EndpointSlice的创建优于对多个EndpointSlice的更新。
以上主要是由于在每个节点上运行的kube-proxy都会持续监控EndpointSlice的变化,对EndpointSlice每次更新成本都很高,因为每次更新都需要Master将更新数据发送到每个kube-proxy。
上述管理机制旨在限制需要发送到每个节点的更新数据量,即使可能导致最终有许多EndpointSlice资源未能填满。实际上,这种不太理想的数据分布情况应该是罕见的。
Master的EndpointSlice控制器处理的大多数更新所带来的数据量都足够小,使得对已存在 (仍有空余空间)EndpointSlice的数据填充都没有问题,如果实在无法填充,则无论如何都需要创建新的EndpointSlice资源。
此外,对Deployment执行滚动升级操作时,由于后端Pod列表和相关Endpoint列表全部会发生变化,所以也会很自然地对EndpointSlice资源的内容全部进行更新。
10.2 服务拓扑
在默认情况下,发送到一个Service的流量会被均匀转发到每个后端Endpoint,但无法根据更复杂的拓扑信息设置复杂的路由策略。服务拓扑机制的引入就是为了实现基于Node拓扑的服务路由,允许Service创建者根据来源Node和目标Node的标签来定义流量路由策略。
通过对来源Node和目标Node标签的匹配,用户可以根据业务需求对Node进行分组,设置有意义的指标值来标识 “较近” 或者 “较远” 的属性:
例如:对于公有云环境来说,通常有区域(Zone或Region)的划分,云平台倾向于把服务流量限制在同一个区域内,这通常是因为跨区域网络流量会收取额外的费用。另一个例子是把流量路由到由DaemonSet管理的当前Node的Pod 上。又如希望把流量保持在相同机架内的Node上,以获得更低的网络延时。
服务拓扑机制需要通过设置kube-apiserver和kube-proxy服务的启动参数--feature-gates-=“ServiceTopology=true,EndpointSlice=true“进行启用(需要同时启用EndpointSlice功能),然后就可以在Service资源对象上通过定义 topologyKeys字段来控制到Service的流量路由了。
对于需要使用服务拓扑机制的集群,管理员需要为Node设置相应的拓扑标签,包括kubernetes.io/hostname、topology.kubernetes.io/zone 和topology.kubernetes.io/region。
然后为Service设置topologyKeys的值,就可以实现如下流量路由策略:
配置为[“kubernetes.io/hostname“]:流量只会被路由到相同Node的Endpoint上,如果Node的Endpoint不存在,则将请求丢弃。
配置为[“kubernetes.io/hostname" "topology.kubernetes.io/zone“ “topology.kubernetes.io/region“]:流量优先被路由到相同Node的Endpoint上, 如果Node没有Endpoint,流量则被路由到同zone的Endpoint,如果在zone中没有Endpoint,流量则被路由到region中的Endpoint上。
配置为[“topology.kubernetes.io/zone“,“*“]:流量优先被路由到同zone 的Endpoint上,如果在zone中没有可用的Endpoint,流量则被路由到任意可用的Endpoint上。
目前使用服务拓扑有以下几个约束条件:
服务拓扑和externalTrafficPolicy=Local是不兼容的,所以一个Service不能同时使用这两种特性。在同一个Kubernetes集群中,启用服务拓扑的Service和设置externalTrafficPolicy=Local特性的Service:是可以同时存在的。
topologyKeys目前可以设置的标签只有3个:kubernetes.io/hostname、topology.kubernetes.io/zone和topology.kubernetes.io/region,未来会增加更多 的标签。
topologyKeys必须是有效的标签格式,并且最多定义16个。
如需使用通配符“*”,则它必须是最后一个值。
下面通过Service的YAML文件对几种常见的服务拓扑应用实例进行说明。
① 只将流量路由到相同Node的Endpoint上,如果Node没有可用的Endpoint,则将请求丢弃:
apiVersion: v1kind: Servicemetadata:name: webappspec:selector:app: webappports:-port: 8080topologykeys:-"kubernetes.io/hostname"② 优先将流量路由到相同Node的Endpoint上,如果Node没有可用的Endpoint,则将请求路由到任意可用的Endpoint:
apiVersion: v1kind: Servicemetadata:name: webappspec:selector:app: webappports:-port:8080topologyKeys:-"kubernetes.io/hostname"-"*"③ 只将流量路由到相同zone或同region的Endpoint上,如果没有可用的Endpoint,则将请求丢弃:
apiVersion: v1kind: Servicemetadata:name: webappspec:selector:app: webappports:-port:8080topologyKeys:-"topology.kubernetes.io/zone" -"topology.kubernetes.io/region"④ 按同Node、同zone、同region的优先级顺序路由流量,如果Node、 zone、region都没有可用的Endpoint,则将请求路由到集群内任意可用的Endpoint上:
apiVersion: v1kind: Servicemetadata: name: webappspec:selector:app: webappports:-port:8080topologyKeys:-"kubernetes.io/hostname"-"topology.kubernetes.io/zone" -"topology.kubernetes.io/region"-"*"














 4210
4210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









