







抖音视频数据获取流程如下
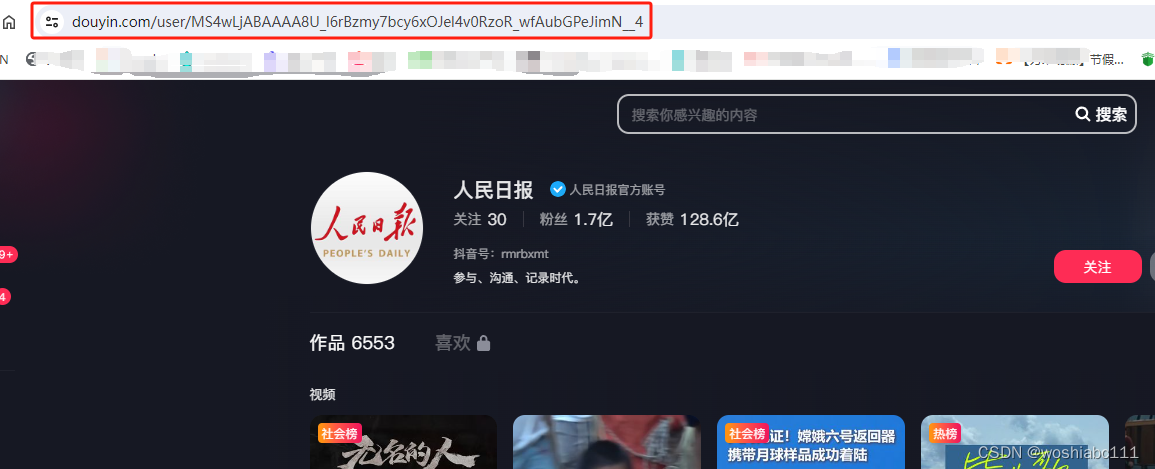
每个抖音账号都有自己的主页地址,且这个地址不用登录。
人民日报的抖音账号主页地址如下
https://www.douyin.com/user/MS4wLjABAAAA8U_l6rBzmy7bcy6xOJel4v0RzoR_wfAubGPeJimN__4
但是在视频列表地址加载的时候会有随机且唯一的key跟在url后面,浏览器F12和postApi都不好使。
只有使用selenium通过chromedriver直接打开浏览器操作了
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from datetime import datetime
import logging
import json
import pymysql
# 创建一个logger
logger = logging.getLogger('my_logger')
logger.setLevel(logging.DEBUG) # 设置日志级别
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('dy.log', encoding='utf-8') # 日志文件名
# 定义handler的输出格式
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
chrome_option = Options()
chrome_option. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









