






链接:https://www.zhihu.com/question/431924548
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:石塔西
https://www.zhihu.com/question/431924548/answer/1605681597
如果你工作在推荐、搜索领域,我强烈你学习、掌握FM算法。我不敢说它是最简单的(FM的确很简单),但是作为一个推荐算法调参工程师,掌握FM一定是性价比最高的。我推崇FM算法的原因,有以下三点。
功能齐全
众所周知,推荐算法有三个应用领域:召回、粗排、精排。推荐算法千千万,但是有的算法只能用于召回,有的算法只能用于排序。像FM这样实现三个领域全覆盖的多面手,目前为止,孤陋寡闻的我尚不知道有第二个。
但是需要强调的是,我们不能只训练一个FM排序模型 ,然后直接拿这个排序模型用于召回。尽管都是基于FM算法,但是FM召回与排序,有以下不同:
使用的特征不同。
FM召回,由于未来要依赖Faiss进行线上检索,所以不能使用user与doc的交叉特征。只有如此,我们才能独立计算user embedding与doc embedding
FM排序,则没有这方面的限制,可以使用user与doc的交叉特征。是的,你没看错。因为FM所实现自动二阶交叉,仅能代表“共现”。但是user与doc之间还有其他形式的交叉,比如user tag与doc tag之间的重合度,喂入这样的交叉,对于排序性能提升,仍然有很大帮助。
使用的样本不同。
训练FM做排序时,必须使用“曝光未点击”这样的“真负”样本。
训练FM做召回时,起码不能只使用“曝光未点击”做负样本。大部分的负样本必须通过随机采样得到。个中原因见我的文章《负样本为王:评Facebook的向量化召回算法》https://zhuanlan.zhihu.com/p/165064102。
使用的Loss不同。
FM排序时,由于负样本是真实的,可以采用CTR预估那样的point-wise loss
FM召回时,由于负样本是随机采样得到的,存在一定的噪声,最好采用BPR, hinge这样的pair-wise loss。
性能优异
推荐系统的两大永恒主题,“记忆”与“扩展”,FM也能实现全覆盖。
FM存在一阶项,实际就是LR,能够“记忆”高频、常见模式
FM存在feature embedding。如我在《无中生有:论推荐算法中的Embedding思想》据说,Embedding是提升推荐算法“扩展性”的法宝。FM通过feature embedding,能够自动挖掘低频、长尾模式。在这一点上,基于embedding的二阶交叉,并不比DNN的高阶交叉,逊色多少。
便于上线
现在深度学习是推荐领域的宠儿,LR/FM/GBDT这样的传统机器学习算法,不招人待见。
DNN虽然性能优异,但是它有一个致命缺点,就是上线困难。训练的时候,各位调参侠,把各种酷炫的结构,什么attention, transformer, capsule,能加上的都给它加上,看着离线指标一路上涨,心里和脸上都乐开了花,却全然无视旁边的后端工程师恨得咬紧了牙根。模型越复杂,离线和线上指标未必就更好,但是线上的时间开销肯定会增加,轻则影响算法与后端的同事关系(打工人何苦为难打工人),重则你那离线指标完美的模型压根没有上线的机会。虽说,目前已经有TF Serving这样的线上serving框架,但是它也不是开箱即用的,也需要一系列的性能调优,才能满足线上的实时性要求。
所以,如果你身处一个小团队,后端工程人员的技术能力不强,DNN的线上实时预测,就会成为一个难题,这个时候,FM这样的传统机器学习算法,就凸显出其优势。
FM排序,虽然理论上需要所有特征进行二阶交叉,但是通过公式化简,可以在 O(n)的时间复杂度下完成。n是样本中非零的特征数目,由于推荐系统中的特征非常稀疏,所以预测速度是非常快的。
召回,由于候选集巨大,对于实时性的要求更高。很多基于DNN的召回算法,由于无法满足线上实时生成user embedding的需求,只能退而离线生成user embedding ,对于用户实时兴趣的捕捉大打折扣。FM召回,这时就显现其巨大的优势。事先把doc embedding计算好,存入Faiss建立索引,user embedding只需要把一系列的feature embedding相加就可以得到,再去faiss中进行top-k近邻搜索。FM召回,可以实现基于用户最新的实时兴趣,从千万量级候选doc中完成实时召回。
总结与参考
由于以上优点,我心目中,将FM视为推荐、搜索领域的"瑞士军刀"。风头上虽然不及DNN那么抢眼,但是论在推荐系统中发挥的作用,丝毫不比DNN逊色,有时还能更胜一筹。FM有如此众多的优点,优秀的调参侠+打工人,还等什么,还不赶快学起来。想迅速掌握FM,我推荐如下参考文献:
掌握FM原理,推荐读美团的博客《深入FFM原理与实践》https://tech.meituan.com/2016/03/03/deep-understanding-of-ffm-principles-and-practices.html。FFM的部分可以忽略,在我看来,FFM更像是为了Kaggle专门训练的比赛型选手,损失了FM的很多优点。这就好比,奥运会上的射击冠军,未必能够胜任当狙击手一样。
FM用于召回,推荐读《推荐系统召回四模型之:全能的FM模型》https://zhuanlan.zhihu.com/p/58160982。注意,如我所述,FM虽然万能,但是FM排序与FM召回,在特征、样本、Loss都存在不同,不可能训练一个FM排序就能直接拿来做召回。这一点,《全能FM》一文没有提到,需要读者特别注意。
如果想亲手实践,可以尝试alphaFM。该项目只不过是作者八小时之外的课外作品,却被很多公司拿来投入线上实际生产环境,足见该项目性能之优异和作者功力之深厚,令人佩服。强烈建议不满足只当“调参侠”的同学,通读一遍alphaFM的源代码,一定收获满满。
作者:刘启林
https://www.zhihu.com/question/431924548/answer/1648969041
2007年论文《Top 10 Algorithms in Data Mining》给出数据挖掘10大算法:https://www.researchgate.net/publication/29467751_Top_10_algorithms_in_data_mining
1、C4.5
2、K-Means
3、SVM
4、Apriori
5、EM
6、PageRank
7、AdaBoost
8、kNN
9、Naive Bayes
10、CART
这些都是机器学习中较为简单的算法。
《机器学习实战》这本书就是参考这篇论文写的,该书基于Python手动实现了其中8个算法(除了EM、PageRank),偏实战,实效性差,建议有针对性参考。
这10大算法虽然简单,但是个人不推荐。因为:
(1)这些算法有点过时;
(2)不够实用,算法工业级落地才有价值;
(3)机器学习领域很大,算法聚焦比较好。
所以个人认为机器学习中较为简单的算法:
推荐系统方向
LR、GBDT、FM
刘启林:FM因子分解机的原理、公式推导、Python实现和应用https://zhuanlan.zhihu.com/p/145436595
自然语言处理方向:
HMM 、CRF
刘启林:CRF条件随机场的原理、例子、公式推导和应用https://zhuanlan.zhihu.com/p/148813079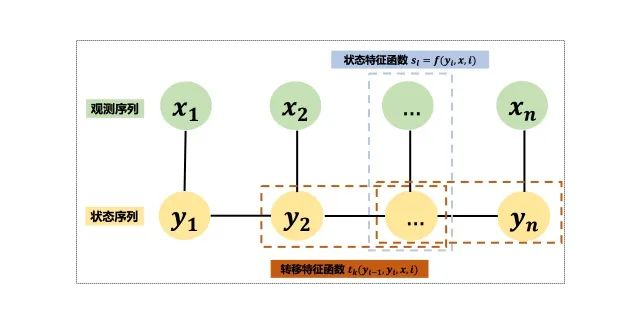
数据挖掘方向:
K-Means、LSA、GBDT
刘启林:GBDT的原理、公式推导、Python实现、可视化和应用https://zhuanlan.zhihu.com/p/280222403
结束语:
限于当前能力和水平,我的可能是错的,或者不全面的。
作者:老王
https://www.zhihu.com/question/431924548/answer/1594547629
在这里列举一些较为简单的机器学习算法。
1)k近邻算法
k近邻算法可能是最简单的机器学习算法。如下图所示,寻找与测试样本距离最接近的k个训练样本,例如k=5,大多数训练样本属于哪个类别,就判定测试样本属于哪个类别。
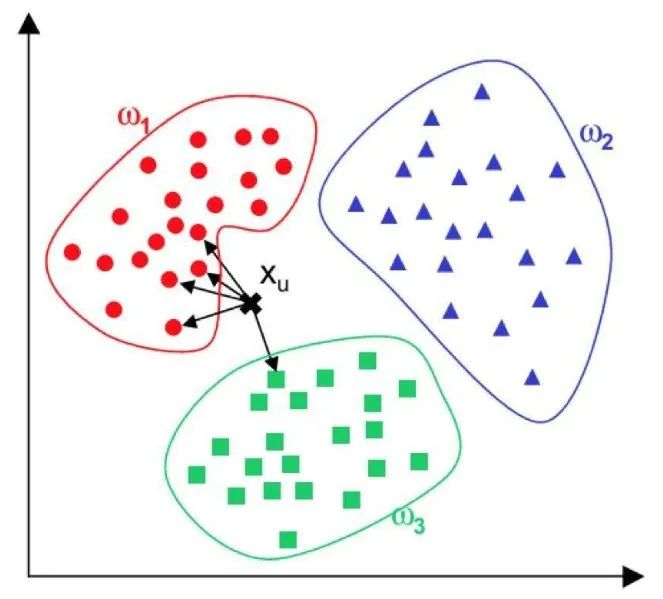
k近邻
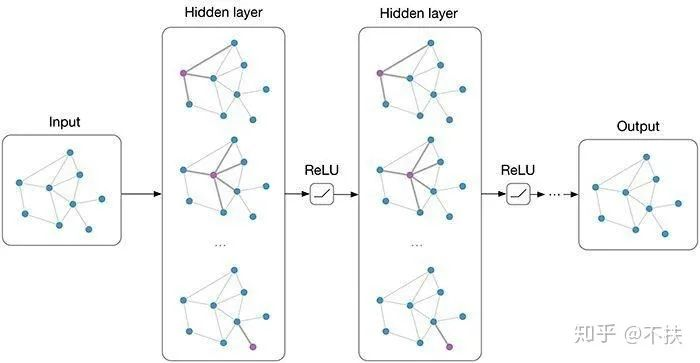
2)多层感知机
多层感知机就是由一些层的神经元组成的,其思想来源于人类的神经系统。
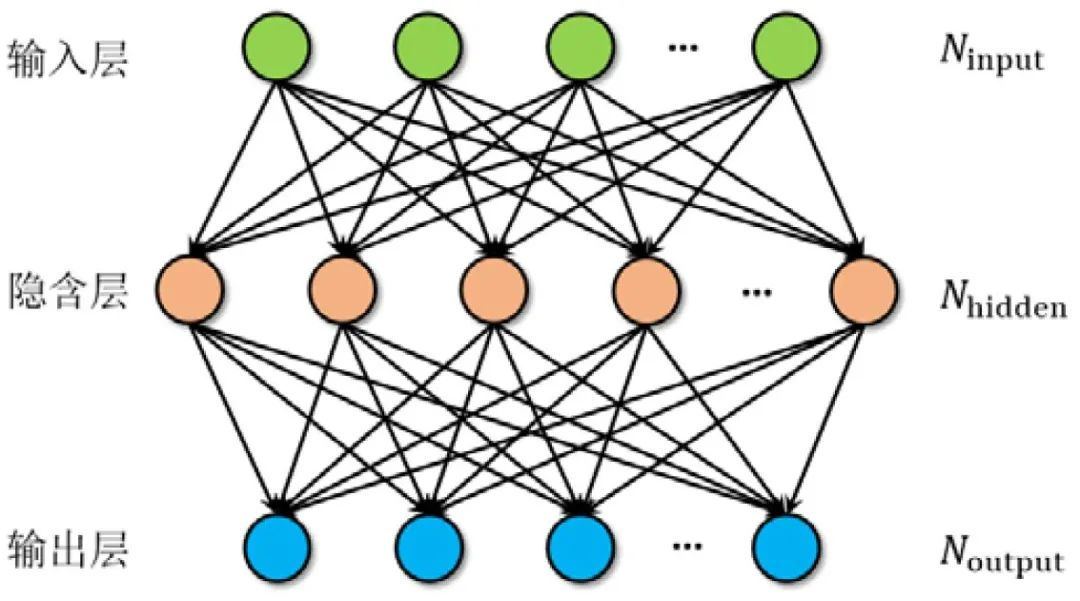
多层感知机
3)卷积神经网络
当输入数据是图像这种高维数据的时候,卷积神经网络的参数量比较少,比较适合。
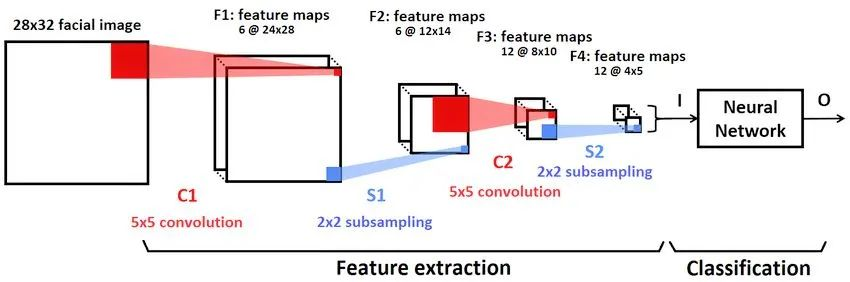
卷积神经网络
4)深度残差网络
当卷积神经网络的层数过深时,就会难以训练。这个时候,残差网络通过加入跨层连接,降低了训练难度。
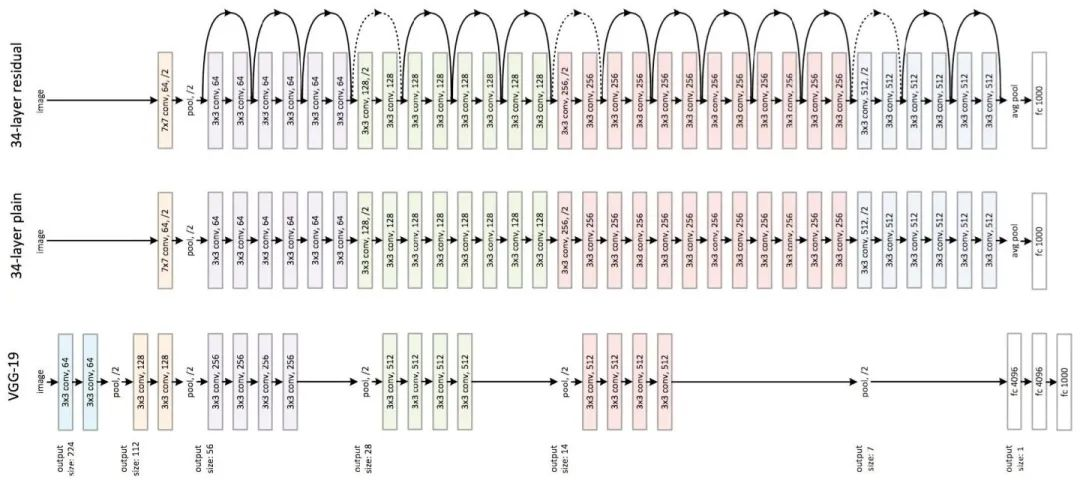
深度残差网络
5)残差收缩网络
如果数据含有较强噪声,残差收缩网络(https://ieeexplore.ieee.org/abstract/document/8850096/)在残差网络中加入了软阈值化,能够取得较好的效果。

(面向强噪、高冗余数据的)残差收缩网络
作者:不扶
https://www.zhihu.com/question/431924548/answer/1646905505
最简单的莫过于决策树,关联规则也可以,想必大家都听说过,尿不湿啤酒的传说吧,就是这个关联规则算法。
静下心来的话,神经网络也是没有传说中那么难的~
神经网络很有点儿控制理论中,闭环控制的那么点儿感觉。不同的是,大多数神经网络在训练阶段会把矩阵给算出来,当做一个固定得值,不会再变了,而闭环控制中则要在线一直调节K函数。
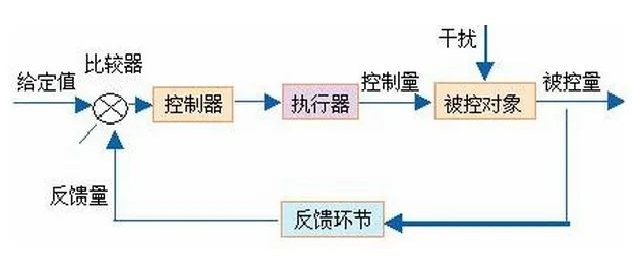
作者:莫催 https://www.zhihu.com/question/431924548/answer/1622252695
LR 应该是最简单的了吧?
其次,有监督 基于距离的 lazy study knn。
再次,无监督 kmeans。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









