









效果展示:
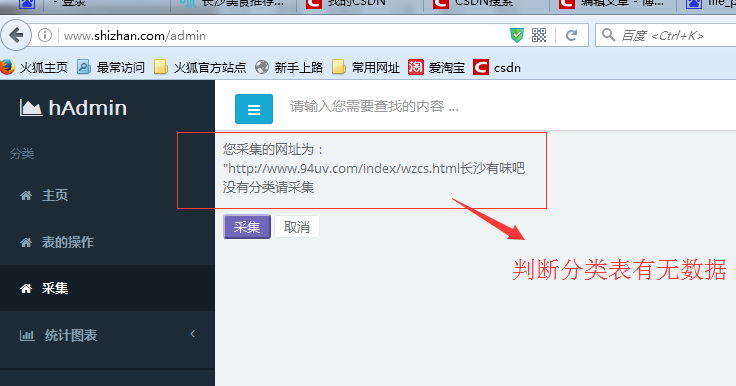
采集分类
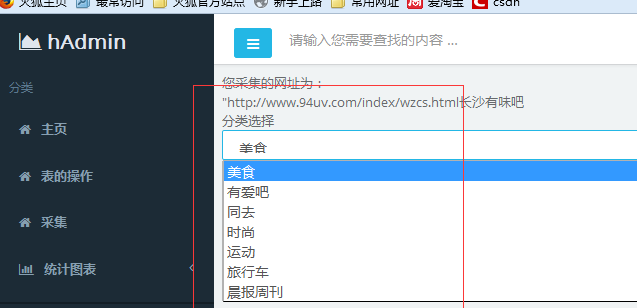
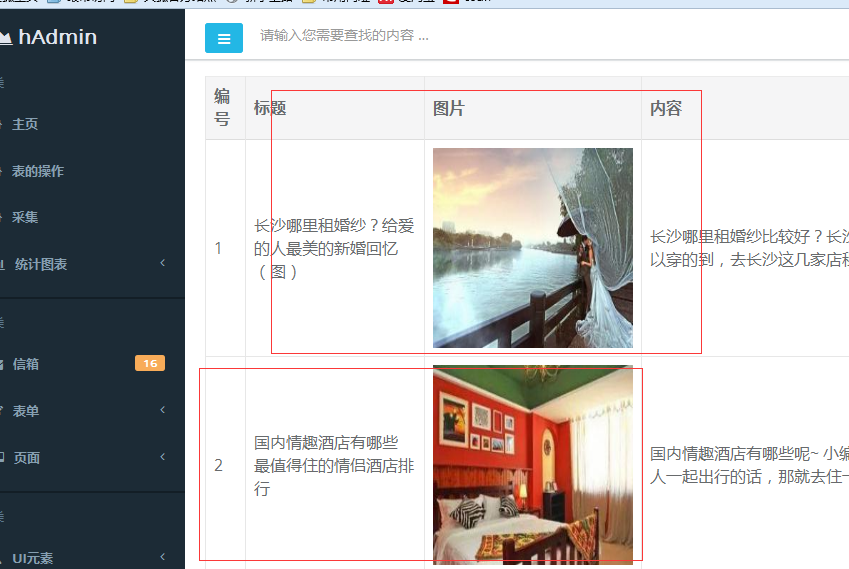
代码实现:
<?php
namespace App\Http\Controllers;
use Illuminate\Support\Facades\Input;
use Illuminate\Http\Request;
use DB;
class GatherController extends NewBaseController
{
/**
* 采集首页
* @param Request $request [description]
* @return [array] [分类数据]
*/
public function index(Request $request){
//查询分类信息
$typeList = DB::table('type')->get();
// print_r($typeList);exit;
return view('gather',['typeList'=>$typeList ]);
}
/**
* 采集操作
* @param Request $request [description]
* @return [array] [分类|详细数据]
*/
public function show(Request $request){
set_time_limit(0);
if($request->input('type_id')){
//分类采集成功
$data=$request->input();
$typeId = $data['type_id'];
$typeList = DB::table('type')->where('type_id',$typeId)->first();
//确定分类链接
$typeLink=$typeList['type_link'];
$url=$typeLink;
// $typeLink="";
//开始采集
if (function_exists('curl_init')) {
$url = $typeLink;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$dxycontent = curl_exec($ch);
// echo $dxycontent;exit;
$reg='#<div class="article-list">.*<div class="pager">#isU';
preg_match($reg,$dxycontent,$p);
// print_r($p);exit;
// print_r($reg);
$reg1 = '#<p>(.*)</p>#isU';
$reg2 = '#<img class=".*" src=".*" data-original="(.*)" alt="(.*)">#isU';
preg_match_all($reg2, $p[0], $img);
// print_r($img);exit;
//标题
$titleList = $img[2];
preg_match_all($reg1, $p[0], $content);
//内容
// $contentList=array();
$contentList = $content[1];
// print_r($contentList);exit;
//图片
$img1 = $img[1];
// print_r($img1);exit;
for($i=0;$i<=9;$i++){
// $imgList[] = $img1[$i];
$suff = substr($img1[$i],strrpos($img1[$i],'.'));
$fileName = rand(10000,90000).time().$suff;
$imgList[] = $fileName;
// echo $filename;
$v=file_get_contents($img1[$i]);
file_put_contents("upload/".$fileName,$v);
}
// exit;
//入库
$arr=array();
foreach($titleList as $k=>$v){
$arr[$k]['news_title'] = $v;
$arr[$k]['news_content'] = $contentList[$k];
$arr[$k]['news_img'] = $imgList[$k];
$arr[$k]['type_id'] = $typeId;
$res=DB::table('news')->insertGetId($arr[$k]);
}
// exit;
if($res){
$newsList = DB::table('news')->get();
// print_R($newsList);exit;
return view('news_list',['newsList'=>$newsList]);
}
}
}else{
//采集分类
$link=$request->input('link');
//开始采集
if (function_exists('curl_init')) {
$url = $link;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$dxycontent = curl_exec($ch);
// echo $dxycontent;
$reg='#<li ><a href="(.*)">(.*)</a></li>#isU';
preg_match_all($reg, $dxycontent, $list);
// print_r($list);exit;
// $typeName
$arr=array();
foreach($list[1] as $k=>$v){
$arr[$k]['type_link'] = $v;
}
foreach($list[2] as $k=>$v){
$arr[$k]['type_name'] = $v;
}
//分类入库
foreach($arr as $k=>$v){
$res = DB::table('type')->insertGetId($v);
}
//跳转到首页
if($res){
return redirect('/gather');
}else{
echo "添加失败";
}
// print_r($arr);exit;
} else {
echo '主人的服务器尚未开启curl扩展';
}
print_r($request->input());
}
}
}
?>恶心人的地方:正则匹配
需要注意的地方:file_put_contents 的使用















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









