











图:TPC-H官网
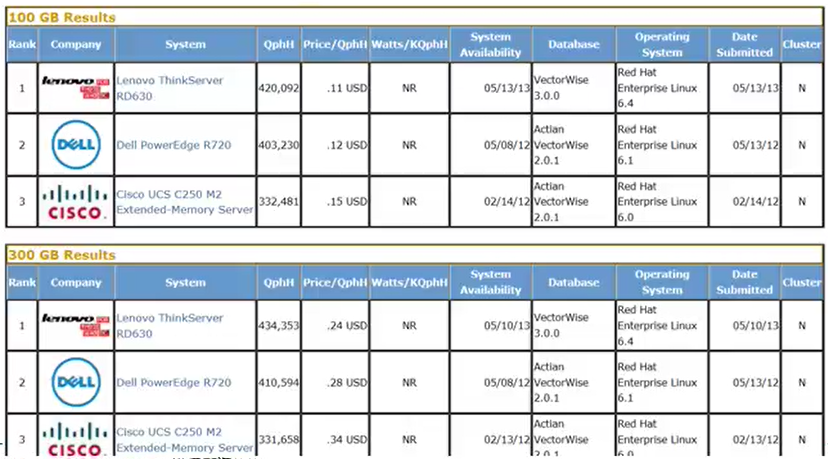
QphH:表示每小时查询的个数;
图:100G和300G的数据测试结果






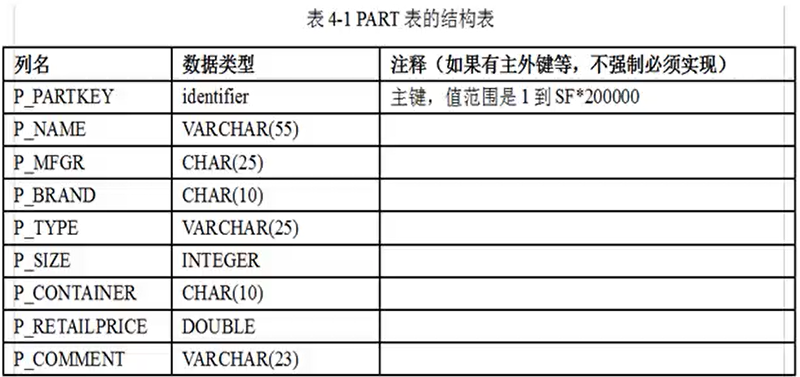
注意SF*200000中的SF是一个动态的值
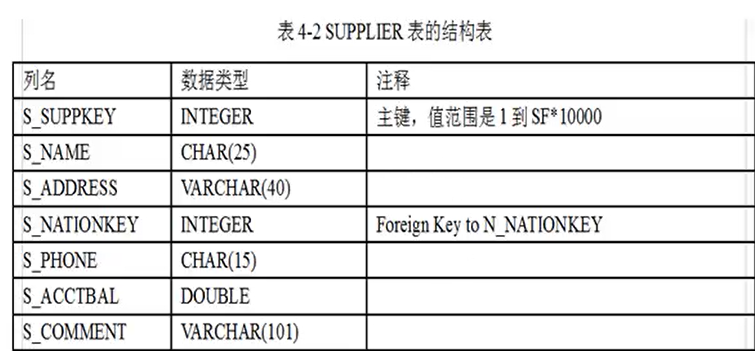
S_NATIONKEY表示该供货商来自于哪个国家。
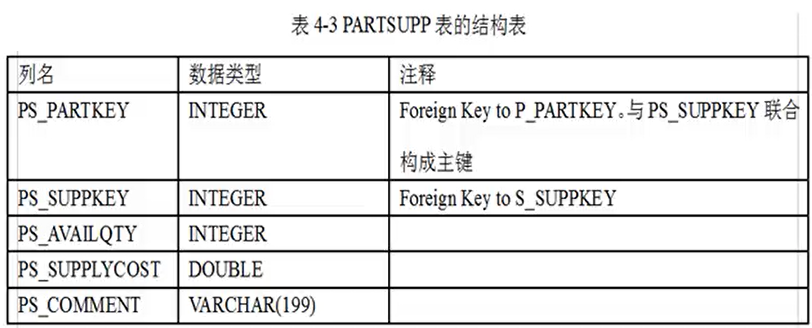
供货商与零件的中间表
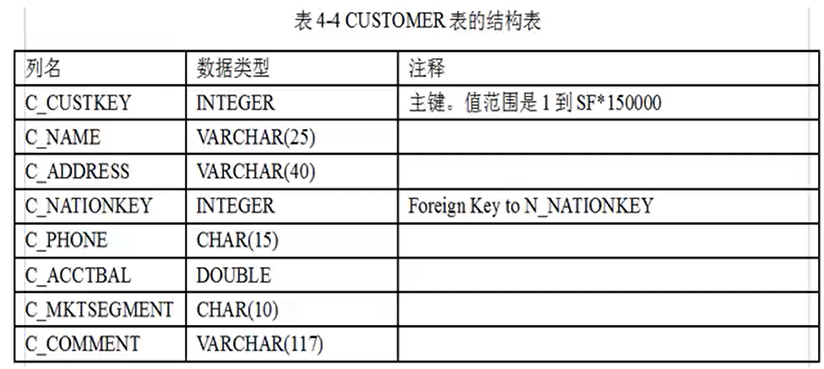
图:客户表

图:订单表

图:LINE_ITEM表
L_ORDERKEY:来自哪个订单;
L_PARTKEY:来自于哪个零件;
L_SUPPKEY:来自于哪个供货商;


图:创建索引

图:测试环境的建立
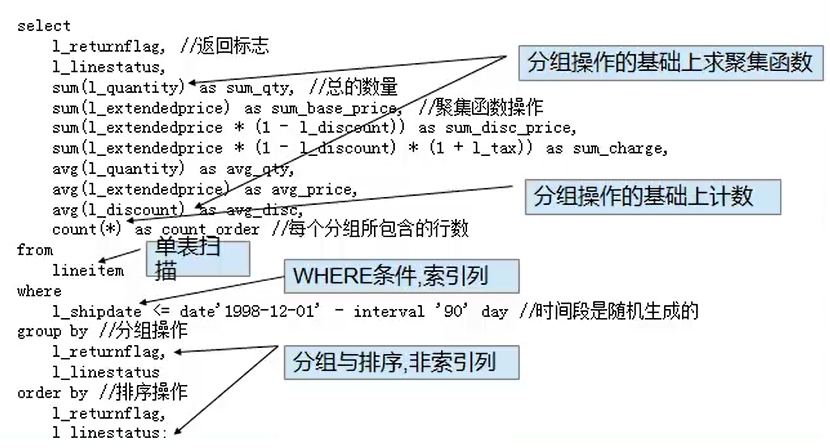
图:Q1-价格统计报告查询
查询在一段时间内,对已经付款的,已经运送的,业务量计费,发货状况以及折扣状况,上税信息,平均价格信息,根据返回标志
和在线状态进行分组,分组后进行统计,

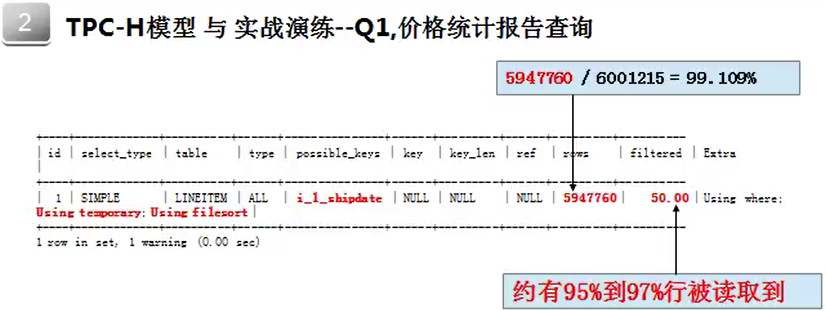
MySql选择了全表扫描的方式,使用了临时表,并做了文件排序;
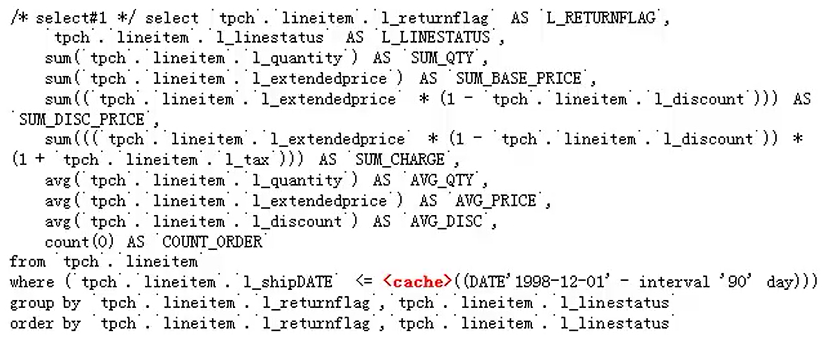
图:被查询优化器处理后的语句
cache部分说明Mysql对其进行了缓存,做了一些优化。


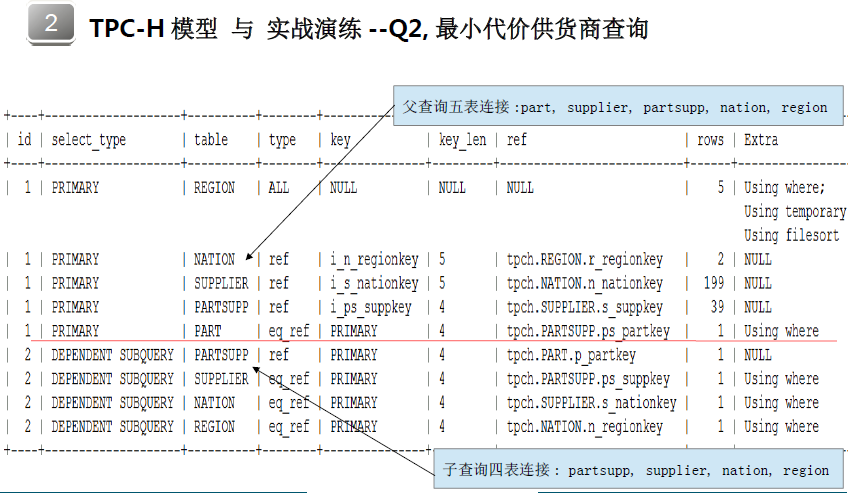

1:根据TPCH模型,我们如何书写效率高的SQL语句;
2:面对已经写好的SQL语句,我们思考该如何做优化;优先思考如何利用索引,需要关注表中索引是如何建立的,即建立了哪些索引,在
哪些列上建立了索引,出现在where条件中的字段是否是索引列;如果出现了group by和order by语句,那么关注group by和order by语句中是否
使用了索引列,如果是,那么整个查询是否可以利用索引来做优化;
3:考虑整个查询的特点,所读取的数据量是什么样的;如果要读取表的所有数据,那么使用索引是没有必要的,在这个时候全表扫描会快于
索引扫描;最后通过查询优化计划以及被优化器优化的SQL语句来验证SQL的优化是否正确;






















 7909
7909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











