






以下内容摘自《Hadoop权威指南》,版权归原作者所有。
流程图
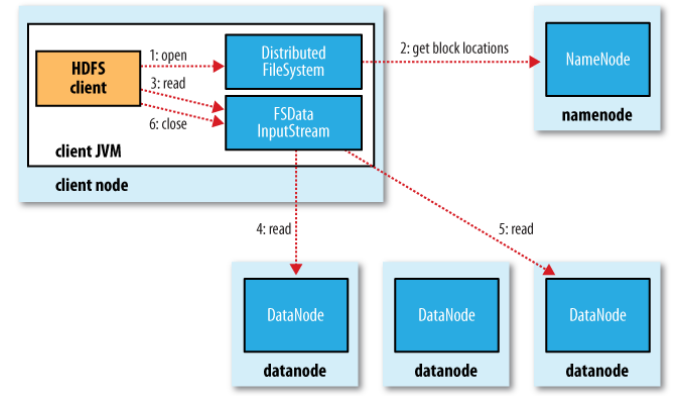
流程说明
1、客户端通过调用 FileSyste 对象的 open() 方法来打开希望读取的文件,对于HDFS 来说,这个对象是分布式文件系统的一个实例(步骤 1) 。
2、DistributedFileSystem 通过使用 RPC 来调用 namenode ,以确定文件起始块的位置(步骤 2) 。
对于每一个块, namenode 返回存有该块复本的 datanode 地址。此外,这些 datanode 根据它们与客户端的距离来排序(机架感应)。如果该客户端本身就是一个 datanode(比如,在一个 MapReduce 任务中) ,并保存有相应数据块的一个复本时,该节点将从本地 datanode 中读取数据。
3、DistributedFileSystem 类返回一个 FSDatalnputStream 对象(一个支持文件定位的输入流)给客户端并读取数据。 FSDatalnputStream 类转而封装DFSlnputStream 对象,该对象管理着 datanode 、namenode 的I/O。接着,客户端对这个输入流调用 read() 方法(步骤 3) 。
4、存储着文件起始块的datanode 地址的 DFSlnputStream 随即连接距离最近的 datanode 。通过对数据流反复调用 read() 方法,可以将数据从 datanode 传输到客户端(步骤4)。
5、到达块的末端时, DFSlnputStream 会关闭与该 datanode 的连接,然后寻找下一个块的最佳datanode (步骤 5) 。
客户端只需要读取连续的流,井且对于客户端都是透明的。
客户端从流中读取数据时,块是按照打开 DFSlnputStream与 datanode 新建连接的顺序读取的。它也需要询问 namenode 来检索下一批所需块的 datanode 的位置。6、一且客户端完成读取,就对 FSDatalnputStream 调用 close() 方法(步骤 6)。
在读取数据的时候,如果 DFSlnputStream在与datanode通信时遇到错误,它便会尝试从这个块的另外一个最邻近 datanode 读取数据 。它也会记住那个故障datanode ,以保证以后不会反复读取该节点上后续的块。DFSlnputStream也会通过校验和确认从 datanode 发来的数据是否完整。如果发现一个损坏的块,它就会在DFSlnputStream试图从其他 datanode 读取一个块的复本之前通知 namenode。
这个设计的一个重点是 namenode 告知客户端每个块中最佳的 datanode ,并让客户端直接联系该 datanode 且检索数据。由于数据流分散在该集群中的所有datanode ,所以这种设计能使 HDFS 可扩展到大量的并发客户端。同时,namenode 仅需要响应块位置的请求(这些信息存储在内存中,因而非常高效) ,而无需晌应数据请求,否则随着客户端数量的增长, namenode 很快会成为一个瓶颈。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









