







老师有个项目,为了提高速度,要求我们要使用多线程。连进程都还不懂的我于是开始一段多线程编程的学习过程。
以下参考自:浮云比翼
1、初识线程
线程在Unix系统下,通常被称为轻量级的进程,线程虽然不是进程,但却可以看作是Unix进程的表亲,同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。 一个进程可以有很多线程,每条线程并行执行不同的任务。
线程可以提高应用程序在多核环境下处理诸如文件I/O或者socket I/O等会产生堵塞的情况的表现性能。在Unix系统中,一个进程包含很多东西,包括可执行程序以及一大堆的诸如文件描述符地址空间等资源。在很多情况下,完成相关任务的不同代码间需要交换数据。如果采用多进程的方式,那么通信就需要在用户空间和内核空间进行频繁的切换,开销很大。但是如果使用多线程的方式,因为可以使用共享的全局变量,所以线程间的通信(数据交换)变得非常高效。
2、相关函数。
使用多线程编程要包含头文件:#include <pthread.h>,编译时加上编译参数 -pthread。
创建线程函数: pthread_create()
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
特别注意第三个参数实际是程序地址。该程序的返回值为 void * 而非 void 。
结束线程函数: pthread_exit()
void pthread_exit(void *retval);
Description: The pthread_exit() function terminates the calling thread and returns a value via retval that (if the thread isjoinable) is available to another thread in the same process that calls pthread_join().线程等待函数: pthread_join()
int pthread_join(pthread_t thread, void **retval);
3、cpu的拓扑结构。
在软件分析之前,我们先要对cpu的拓扑结构有个比较清晰的认识。
Red Hat官网一段话有很清晰的介绍,原文摘抄如下:
在现代计算机技术中,一个"中央"处理单元的观念是误导性的,因为大部分现代化的系统都有多个处理器。这些处理器是如何相互连接,并且如何连接至其他系统资源 —"系统拓扑"— 会对系统和应用程序的性能以及系统调节选项产生巨大的影响。
现代计算机技术主要运用两种主要的拓扑类型
1) SMP 拓扑
SMP(对称多处理器)拓扑允许所有的处理器同时访问内存。然而,由于内存访问权限的共享性和平等性,固然会迫使所有 CPU 及 SMP 系统序列化的内存访问权限的局限性增加,目前这种情况常不被接受。因此,几乎所有现代服务器系统都是 NUMA(非一致性内存访问)机器。
2) NUMA 拓扑
比起 SMP 拓扑,NUMA(非一致性内存访问)拓扑是近来才开发的。在 NUMA 系统中,多个处理器物理分组至一个 socket。每个 socket 都有一个专用内存区,对该内存进行本地访问的服务器统称为一个节点。同一个节点上的服务器能高速访问该节点的存储体,但访问其他节点上的存储体速度就较慢。因此,访问非本地存储体会造成性能的损失。考虑到性能损失,服务器执行应用程序时,NUMA 拓扑结构系统中对性能敏感的应用程序应访问同一节点的内存,并且应尽可能地避免访问任何远程内存。因此,在调节 NUMA 拓扑结构系统中的应用程序性能时,重要的是要考虑这一应用程序的执行点以及最靠近此执行点的存储体。
在 NUMA 拓扑结构系统中,/sys 文件系统包含处理器、内存及外围设备的连接信息。
/sys/devices/system/cpu 目录包含处理器在系统中相互连接的详情。
/sys/devices/system/node 目录包含系统中 NUMA 的节点信息以及节点间的相对距离。
我们一般使用 lscpu 或cat /proc/cpuinfo 这两个指令来查看计算机cpu的各种信息。
容易的:我们可以通过 lscpu 有无 NUMA 信息知道系统是 NUMA 拓扑结构还是 SMP 结构。
此处我们还要在简单分析一下里面的参数含义。
比如我的机器参数如下:
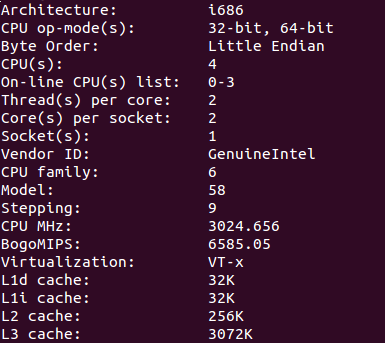
为理解方便,我们从大往小讲:
可以看出我的机器没有NUMA那项,也即我的机器是SMP结构。
Socket(s): 指的是物理CPU的个数(不同的物理CPU独立封装)。我这里是1 。
Core(s) per socket: 指的是每个独立封装的CPU里的核的个数。我的是2 。
Thread(s) per core: 指的是每个核的最大线程数,若为2,则表示是超线程。
CPU(s):指的是逻辑cpu的个数(即 所有核数(2) ×每个核的线程数(2) = 4)。逻辑cpu的编号从0 ~ (cpu个数-1) 。
接着我们看一下 cat /proc/cpuinfo 这个指令的结果。有4张,如下(只截取相关部分):
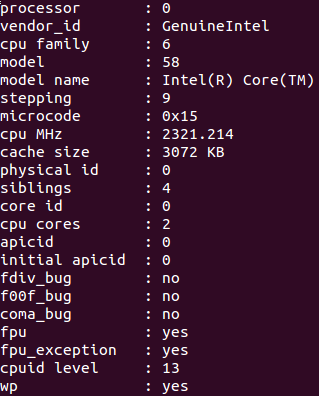
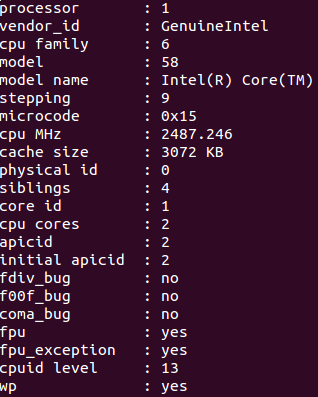
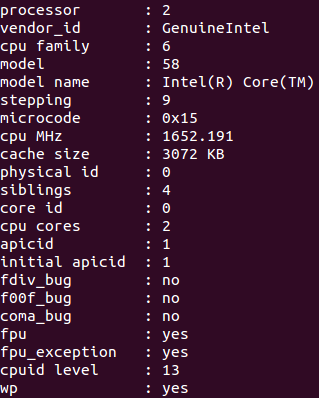
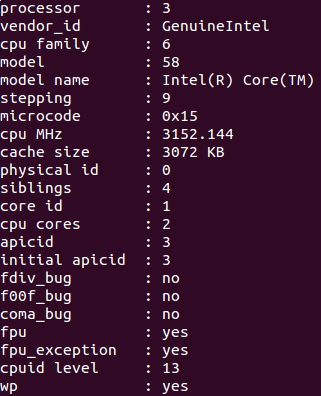
分析上图:
physical id: 顾名思义,即物理CPU的 id,有几个就说明有几个物理CPU。我的只有id = 0 这一种。
cpu cores : 表示每个物理CPU有几个核,我的是 2 。
core id:表示该逻辑cpu对应的核编号,为该核在其物理CPU中的编号,我的主机和服务器的核编号都是从0 ~ (每个物理CPU核数 - 1),可是网上的几个例子中貌似核编号不一定按这个规则来,比如一个四核的CPU,其编号可以是:0,1,9 , 10这样。。。不懂
siblings:表示每个物理CPU里的逻辑cpu的个数。
processor : 对应每一个逻辑cpu。
相应的我们再看一下服务器的架构:
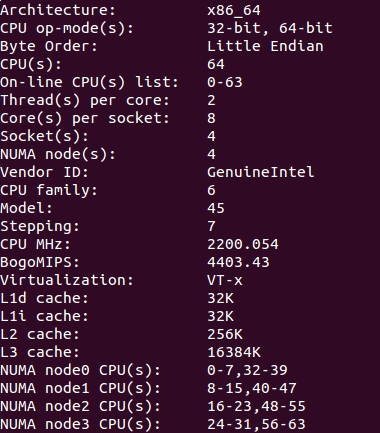
最明显的差别就是多了 NUMA 部分,表明服务器是 NUMA 架构。从前面的论述我们知道,NUMA 架构中多个核封装在一起,组成一个NUMA节点(Red Hat中说一个NUMA节点就是一个Socket,也有人说是多个Socket组成一个NUMA节点,我的服务器与Red Hat一致)。
仔细观察后得出服务器的结构图如下(编号为逻辑cpu的编号):o(╯□╰)o
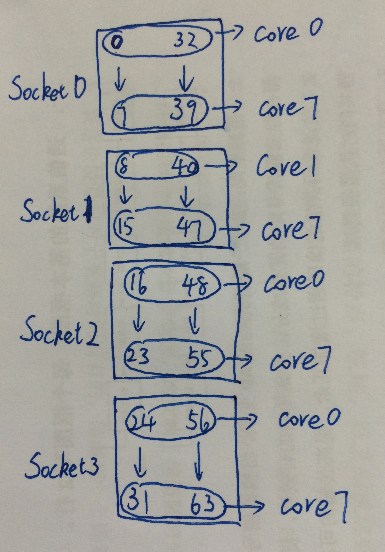
不同的机器编号方式不同,可以参见Red Hat的例子。
第三节参考自:
4、一个简单的例子
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* print_message_function (void *ptr);
int main()
{
int tmp1, tmp2;
void *retval;
pthread_t thread1, thread2;
char *message1 = "thread1";
char *message2 = "thread2";
int ret_thrd1, ret_thrd2;
/*for(long long k = 0; k < 10e8; )
++k;
*/
ret_thrd1 = pthread_create(&thread1, NULL, print_message_function, (void *) message1);
ret_thrd2 = pthread_create(&thread2, NULL, print_message_function, (void *) message2);
// 线程创建成功,返回0,失败返回失败号
if (ret_thrd1 != 0) {
printf("线程1创建失败\n");
} else {
printf("线程1创建成功\n");
}
if (ret_thrd2 != 0) {
printf("线程2创建失败\n");
} else {
printf("线程2创建成功\n");
}
//同样,pthread_join的返回值成功为0
tmp1 = pthread_join(thread1, &retval);
printf("thread1 return value(retval) is %d\n", (int)retval);
printf("thread1 return value(tmp) is %d\n", tmp1);
if (tmp1 != 0) {
printf("cannot join with thread1\n");
}
printf("thread1 end\n");
tmp2 = pthread_join(thread2, &retval);
printf("thread2 return value(retval) is %d\n", (int)retval);
printf("thread2 return value(tmp) is %d\n", tmp2);
if (tmp2 != 0) {
printf("cannot join with thread2\n");
}
printf("thread2 end\n");
}
void* print_message_function( void *ptr ) {
for (int i = 0; i< 5; i++) {
printf("%s:%d\n", (char *)ptr, i);
}
}由于我的机器有4个逻辑cpu(最大4个线程),如果不特定配置程序的运行,那么在运行过程中系统会把每个线程分配到不同的逻辑cpu上去运行,并且与产生这两个线程的当前进程也不同(即尽量让逻辑cpu平均分担工作)。
由top指令可以知道两个线程是同时运行的,输出是交错的也可以证明这点。

借助top命令我们可以清楚看到所有进程,线程的运行状态。
在终端输入:
top -d 1 -H //-d 1 表示刷新时延为1秒, -H表示显示线程状态
我们可以使用cset命令使得所有程序都执行在一个逻辑cpu里面。
1)首先使用 sudo cset shield -c 0 空出 cpu 0,等待用户使用,cpu 1 ~3被系统使用。(即我们的代码被限制在cpu0之内)
2)将代码运行在cpu0上,sudo cset shield 0 -e ./test ,top指令显示2个线程同时运行在cpu0上。
代码如下:
//Version 1
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* print_message_function (void *ptr);
int main()
{
int tmp1, tmp2, tmp3;
void *retval;
pthread_t thread1, thread2, thread3;
char *message1 = "thread1";
char *message2 = "thread2";
char *message3 = "thread3";
int ret_thrd1, ret_thrd2, ret_thrd3;
ret_thrd1 = pthread_create(&thread1, NULL, print_message_function, (void *) message1);
if (ret_thrd1 != 0)
{
printf("线程1创建失败\n");
}
else
{
printf("线程1创建成功\n");
}
for(int j = 0; j < 1e9; j++)
{}
ret_thrd2 = pthread_create(&thread2, NULL, print_message_function, (void *) message2);
if (ret_thrd2 != 0)
{
printf("线程2创建失败\n");
}
else
{
printf("线程2创建成功\n");
}
ret_thrd3 = pthread_create(&thread3, NULL, print_message_function, (void *) message3);
if (ret_thrd3 != 0)
{
printf("线程3创建失败\n");
}
else
{
printf("线程3创建成功\n");
}
//for(long long k = 0; k < 10e8; )
// ++k;
// 线程创建成功,返回0,失败返回失败号
//同样,pthread_join的返回值成功为0
tmp1 = pthread_join(thread1, &retval);
printf("thread1 return value(retval) is %d\n", (int)retval);
printf("thread1 return value(tmp) is %d\n", tmp1);
if (tmp1 != 0)
{
printf("cannot join with thread1\n");
}
printf("thread1 end\n");
tmp2 = pthread_join(thread2, &retval);
printf("thread2 return value(retval) is %d\n", (int)retval);
printf("thread2 return value(tmp) is %d\n", tmp2);
if (tmp2 != 0)
{
printf("cannot join with thread2\n");
}
printf("thread2 end\n");
tmp3 = pthread_join(thread3, &retval);
printf("thread3 return value(retval) is %d\n", (int)retval);
printf("thread3 return value(tmp) is %d\n", tmp3);
if (tmp3 != 0)
{
printf("cannot join with thread3\n");
}
printf("thread3 end\n");
}
void* print_message_function( void *ptr )
{
for (int i = 0; i< 7; i++)
{
printf("%s:%d\n", (char *)ptr, i);
}
}
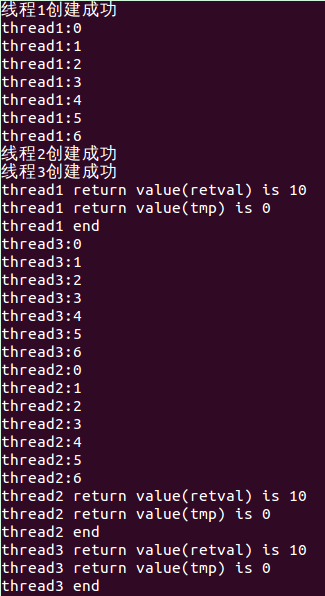
运行结果给我了一个错觉,也即当只有一个逻辑cpu为程序工作时,最多只有一个线程在跑,那么一个线程会一直跑除非运行结束或线程自己主动挂起自己(等待某个信息什么的)。结果看上去符合这个结论,因为从打印的角度看子线程的打印是连续的,即子线程是都是从开始运行到结束。可是还是有异常引起我的注意。因为既然最先打印“线程1创建成功”,说明还运行在主线程里面,可是为什么马上又有thread1的打印过程。考虑到会有“线程切换延时”的可能,在与灵哥的交流下,于是有了下面简单暴力的代码:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void* print_message_function1 (void *ptr);
void* print_message_function2 (void *ptr);
int main()
{
int tmp1, tmp2;
void *retval;
pthread_t thread1, thread2;
char *message1 = "thread1";
char *message2 = "thread2";
int ret_thrd1, ret_thrd2;
ret_thrd1 = pthread_create(&thread1, NULL, print_message_function1, (void *) message1);
if (ret_thrd1 != 0)
{
printf("线程1创建失败\n");
}
else
{
printf("线程1创建成功\n");
}
ret_thrd2 = pthread_create(&thread2, NULL, print_message_function2, (void *) message2);
if (ret_thrd2 != 0)
{
printf("线程2创建失败\n");
}
else
{
printf("线程2创建成功\n");
}
tmp1 = pthread_join(thread1, &retval);
printf("thread1 end\n");
tmp2 = pthread_join(thread2, &retval);
printf("thread2 end\n");
}
void* print_message_function1( void *ptr )
{
for (int i = 0; i< 1e7; i++)
printf("=======\n");
}
void* print_message_function2( void *ptr )
{
for (int i = 0; i< 1e7; i++)
printf("$$$$$$$\n");
}分析了下结果,从一点就证明了并不是“延时”的问题。因为,子线程的打印过程是交错的,这就说明了虽然当下只有一个逻辑cpu在运行,而且要运行多个线程,虽然不能真正的并行运行,但在系统的调用下它们会交错运行,给人一种并行的感觉。还说明之前的打印之所以没有被交错,主要是运行时间太短。通过统计发现上面的子线程打印过程,大概每打印220000行,线程切换一次,一共切换了好几次。
5、绑定线程到固定的逻辑cpu
这里主要用到三个函数:
void CPU_ZERO(cpu_set_t *set);
void CPU_SET(int cpu, cpu_set_t *set);
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset);
其中cpu_set_t数据类型是指:This data set is a bitset where each bit represents a CPU. 以下是灵哥的代码供我学习:
#include <fstream>
#include <sstream>
#include <string>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <pthread.h>
#include <errno.h>
#include <unistd.h>
#include <time.h>
using namespace std;
float* getMatrix(char* fileName, int m, int n)
{
int cnt = 0;
float* mat = new float[m * n];
ifstream file(fileName);
if (!file)
{
printf("error: cannot open %s\n", fileName);
return NULL;
}
string line;
string data;
if (file.is_open())
{
while (getline(file, line))
{
istringstream iss(line);
while(getline(iss, data, ' '))
{
if (data != "")
{
mat[cnt] = (float)atof(data.c_str());
cnt ++;
}
}
}
file.close();
}
return mat;
}
// a wrapper that made to make this thread to core num(0, n-1)
// n is the system's number of cores
int stick_this_thread_to_core(int core_id)
{
int num_cores = sysconf(_SC_NPROCESSORS_ONLN);
if (core_id < 0 || core_id >= num_cores)
return EINVAL;
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(core_id, &cpuset);
pthread_t current_thread = pthread_self();
return pthread_setaffinity_np(current_thread, sizeof(cpu_set_t), &cpuset);
}
// define a struct for passing argument to a thread function
struct Args{
float* a;
int rowIndex;
int colLen;
int coreId;
// Args(float* _a, int _rowIndex, int _colLen, int _coreId) : \
a(_a), rowIndex(_rowIndex), colLen(_colLen), coreId(_coreId){}
};
void* getMax(void* arg)
{
// get arguments
struct Args* m_arg = (struct Args*) arg;
float* a = m_arg->a;
int rowIndex = m_arg->rowIndex;
int colLen = m_arg->colLen;
int coreId = m_arg->coreId;
// stick this thread to coreId
if(stick_this_thread_to_core(coreId))
<span style="white-space:pre"> printf("Stick to core %d is failed", coreId); </span>
int tmp = 10e5;
while(tmp--);
// get the max
float* begin = a + rowIndex * colLen;
float max = *begin;
for (int i = 0; i < colLen; ++i)
{
if (max < *(begin+i))
max = *(begin+i);
}
// printf("thread %d max is: %f\n", rowIndex, max);
}
int main()
{
stick_this_thread_to_core(0);
char* fileName = "test_data.mat";
const int m = 1000;
const int n = 3000;
float* A = getMatrix(fileName, m, n);
if (NULL == A)
{
printf("error: get mat from %s error\n", fileName);
return -1;
}
// cal step rows in one for loop, step less than the parallel core num
int step = 2;
pthread_t* th = new pthread_t[step];
Args* arg = new Args[step];
for (int i = 0; i < m/step; ++i)
{
for (int j = 0; j < step; ++j)
{
arg[j].a = A;
arg[j].rowIndex = step*i+j;
arg[j].colLen = n;
arg[j].coreId = j+1;
if (pthread_create(&th[j], NULL, getMax, (void *)&arg[j]))
{
printf("create thread 0 failed!\n");
return -1;
}
}
for (int j = 0; j < step; ++j)
pthread_join(th[j], NULL);
}
printf("%f\n", time);
delete[] th;
delete[] arg;
return 0;
}用top指令可以看见成功将线程绑定到指定的逻辑cpu上。















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









