






初入爬虫的道路,找到了一篇好的指导文章,先在此献上,内部讲述了入门开始的每一步,个人是比较推荐的!!!
链接:https://zhuanlan.zhihu.com/p/21479334
(我跳过了python 2.7 基础知识的学习部分,想学的也可以在上面的文章中学习,同样可以百度找到聊雪峰老师的教程,细致入微,真心推荐。。。)
先说说我学爬虫的原因:看着大神们各种爬网站,各种秀数据,当然还看了一些爬知乎美女头像的机器人代码,本人的大脑已无力思考,被深深的吸引住了。。。,故而,不多说了,现阶段爬取网站大都需要先登录,即模拟登录场景,完美略过网站过滤器(PS:下文中的代码有部分是在百度时找到某些大神写的python3.0的部分代码改写的,的,先行声明):
# encoding: UTF-8
# CSDN模拟登陆
import urllib, urllib2, cookielib, re
# 保存 cookie文件名
filename = "d:/cookie.txt"
# 创建与Mozilla浏览器cookies.txt兼容的FileCookieJar实例
cookie = cookielib.MozillaCookieJar(filename)
# 不写入文件时使用
# cookie = cookielib.CookieJar()
# 处理HTTP Cookie
cookieProc = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(cookieProc)
h = opener.open('https://passport.csdn.net').read().decode("utf8")
patten = re.compile(r'name="lt" value="(.*?)"')
b = patten.search(h)
# 模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:32.0) Gecko/20100101 Firefox/32.0',
'Referer': 'https://passport.csdn.net'}
postData = {
'username': 'XXX',
'password': 'XXX',
'lt': b.group(1),
'execution': 'e1s1',
'_eventId': 'submit',
}
# 访问信息指定字符编码
postData = data = urllib.urlencode(postData).encode(encoding='UTF8')
request = urllib2.Request(url='https://passport.csdn.net', data=postData, headers=headers)
response = opener.open(request)
text = response.read()
print (text)
# 保存cookie到文件
# ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入
cookie.save(ignore_discard=True,ignore_expires=True)
# 测试二次访问网站直接越过登录
newlogurl = 'http://my.csdn.net/'
request = urllib2.Request(newlogurl)
request.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0')
result = opener.open(request)
print result.read()代码执行场景:
1、首先创建或打开cookie存储文件;
2、关联、处理HTTP Cookie请求;
3、打开页面连接,请求页面内容,并获取登录请求的一些必须参数(如【lt】参数,csdn登录时页面自带的参数,每次登陆不一样,所以才需要用正则表达式去页面先匹配出来)
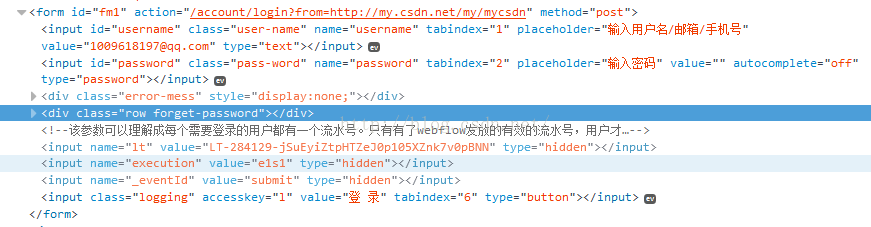
图1 CSDN页面登录请求的信息
4、页面请求头,Header信息的声明(CSDN默认拒绝爬虫请求,不声明会报403错误)
5、请求成功后保存登录的cookie信息,再次访问内部链接(即只有登录后才可以访问的链接,以前是进不去的)
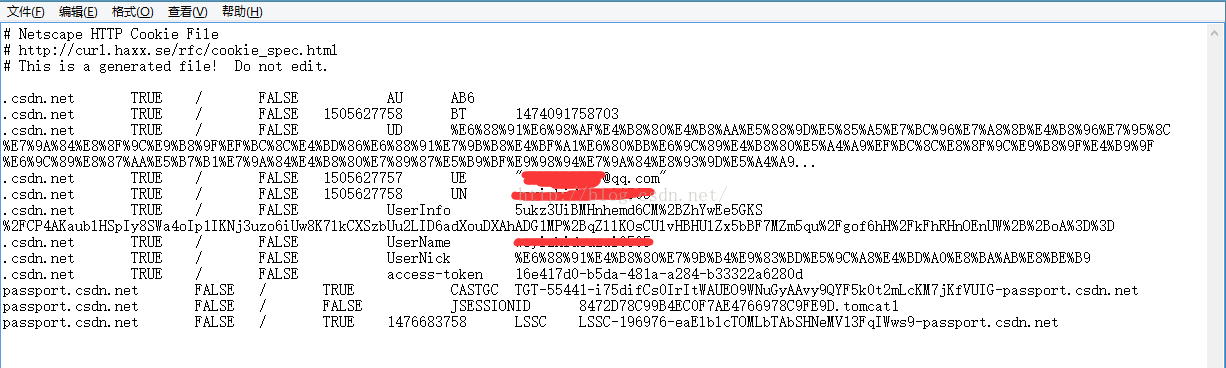
图2 成功保存的cookie信息















 2756
2756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









