







一、四次 AI 关键发展点
1. 第一次发展:AI的诞生(1950年代)核心:科学家开始思考“机器能否像人一样思考”。 关键事件:
- 图灵测试(1950年):计算机科学家图灵提出,如果一台机器能和人对话到让人分不清它是机器还是人,就算通过了“智能测试”。
- 达特茅斯会议(1956年):一群科学家聚在一起,正式提出“人工智能”这个词,并认为未来机器可以模仿人类的学习、推理等能力。 通俗理解:就像科幻电影里第一次有人提出“机器人可能有大脑”的想法。
2. 第二次发展:专家系统(1980年代)核心:让计算机成为某个领域的“专家”。 关键事件:
- 程序员给计算机输入大量专业规则(比如医学诊断、法律咨询),让它像人类专家一样回答问题。
- 例如:早期的医疗AI能根据症状判断疾病。 缺点:这些系统只能按设定好的规则工作,不够灵活,遇到新问题就“傻眼”了。
3. 第三次发展:深度学习的突破(2010年代)核心:计算机学会“自己学习”。 关键技术:
- 神经网络:模仿人脑结构,让计算机通过大量数据(比如图片、文字)自动总结规律。
- AlphaGo(2016年):谷歌的AI程序击败世界围棋冠军,震惊世界。它通过反复和自己下棋,学会了人类都没想到的战术。 影响:从此,AI能处理更复杂的任务,比如人脸识别、语音助手(如Siri)、推荐算法(如抖音)。
4. 第四次发展:生成式AI(2020年代)核心:AI不仅能回答问题,还能“创造内容”。 代表技术:
- ChatGPT:能写作文、编故事、写代码,像真人一样聊天。
- AI绘画(如Midjourney):输入文字就能生成逼真的图片。 特点:这些AI通过“读”海量数据,自己总结出创作规律,甚至能模仿人类风格。
总结: AI从“模仿规则”到“自己学习”,再到“主动创造”,发展速度越来越快。你现在用的智能手机、刷到的短视频推荐,背后都有AI的影子哦!
二、解码注意力机制(Attention Mechanism)
1、什么是注意力机制(Attention Mechanism)?
想象你在读一本很厚的书,书里有一句话特别重要,但这句话藏在第100页的某个角落。如果让你回答关于这句话的问题,你可能会直接“翻到第100页”仔细看它,而不是从头到尾把整本书再读一遍——这就是“注意力机制”的核心:让AI学会“主动关注重点”。
比如:
- 翻译句子:AI要把“我爱吃苹果”翻译成英文。当它翻译“苹果”(apple)时,会专门“注意”原句中的“苹果”这个词,而不是平均看待所有字。
- 生成回复:如果你问AI:“夏天的巴黎有什么好玩的?”,它会自动“注意”关键词“夏天”“巴黎”“好玩”,再生成回答
2、 注意力机制对AI的贡献
- 解决“健忘症”问题: 以前的AI(比如传统神经网络)处理长句子时,容易“忘记”开头的内容(比如翻译一本小说,看到后面忘了前面)。注意力机制让AI能随时“回头看”关键信息。
- 让AI更“聪明”: 比如,AI读“他打了篮球,然后去弹钢琴”,如果要回答“他弹了什么乐器”,注意力机制会直接“聚焦”在“钢琴”这个词上,而不是被“篮球”干扰。
- 推动技术革命: 注意力机制是如今ChatGPT、语音助手、自动驾驶的核心技术之一。它让AI能处理更复杂的任务,比如写文章、画图、和你聊天时“记住上下文”。
举个生活化的例子
假设你妈妈让你去超市买:牛奶、鸡蛋、草莓,但别买香蕉,因为家里还有。
- 没有注意力机制的AI:可能会漏掉“别买香蕉”,最后买了香蕉回家。
- 有注意力机制的AI:会特别“注意”“别买香蕉”这句话,自动忽略香蕉。
再比如下面这个例子:
“昨天,我在一个繁忙的一天结束后,决定去我最喜欢的咖啡店放松一下.我走进咖啡店,点了一杯拿铁,然后找了一个靠窗的位置坐下.我喝着咖啡,看着窗外的人们匆匆忙忙,感觉非常惬意.然后,我从咖啡店出来,回到了家中。“
问:我去了几次咖啡店?
在这个例子中,“咖啡店”出现了三次,但并非每次都是关键信息.
·当我们理解“我走进咖啡店,点了一杯拿铁”时,“走进”和“点了一杯拿铁”是关键动作,而
“咖啡店”的信息已经被我们知道了.
·同样,当理解“我从咖啡店出来,回到了家中”时,“从咖啡店出来”和“回到了家中”是关键信息,而“咖啡店”的信息仍然是冗余的.
注意力机制就是帮助模型在处理这样的句子时,能够更好地关注到关键的信息,而忽略冗余的信息。
总结
注意力机制就像给AI装了一个“智能手电筒”,让它能在海量信息中快速找到重点,变得更高效、更精准。没有它,就没有今天的智能聊天机器人、实时翻译和推荐算法哦!
3、注意力机制在自然语言处理任务中有哪些具体应用
注意力机制在自然语言处理(NLP)任务中非常重要,它让AI能更好地理解和生成语言。以下是几个具体的应用,我用简单的例子解释一下:
- 机器翻译
任务:把一种语言翻译成另一种语言,比如把中文翻译成英文。
注意力机制的作用:
翻译时,AI需要“注意”原句中的关键词。比如翻译“我爱吃苹果”为英文,AI会特别“注意”“苹果”这个词,并准确地翻译成“apple”。
以前的翻译模型容易漏掉重要信息,注意力机制让它能“记住”并聚焦在关键部分。
2. 文本生成
任务:让AI写文章、编故事或者生成对话。
注意力机制的作用:
比如你让AI写一段关于“夏天的巴黎”的文章,它会“注意”关键词“夏天”“巴黎”,并围绕这些词生成内容。
在生成对话时,AI会根据上下文“注意”你之前说过的话,从而生成连贯的回复。
3. 问答系统
任务:让AI回答用户的问题,比如“谁发明了电灯?”
注意力机制的作用:
AI会“注意”问题中的关键词“发明”“电灯”,并在文本中快速找到相关信息(比如“爱迪生”)。
如果没有注意力机制,AI可能会忽略关键信息,给出错误答案。
4. 情感分析
任务:判断一段文字的情感是正面、负面还是中性。
注意力机制的作用:
比如分析句子“虽然天气不好,但玩得很开心”,AI会“注意”关键词“玩得很开心”,从而判断情感是正面的。
注意力机制让AI能抓住影响情感的关键词,忽略无关内容。
5. 文本摘要
任务:把一篇长文章压缩成简短的摘要。
注意力机制的作用:
AI会“注意”文章中的重要句子或关键词,比如“研究发现”“结论是”,然后提取这些部分生成摘要。
这样生成的摘要既保留了核心信息,又不会遗漏重点。
6. 语音识别
任务:把语音转换成文字。
注意力机制的作用:
AI会“注意”语音中的关键音节或词汇,比如“我想吃苹果”中的“苹果”,从而更准确地转换成文字。
注意力机制还能帮助AI处理口音、噪声等问题。
7. 命名实体识别
任务:从文本中识别出人名、地名、日期等特定信息。
注意力机制的作用:
比如从句子“2023年,马斯克访问了北京”中,AI会“注意”“2023年”“马斯克”“北京”这些关键信息,并准确识别出它们是日期、人名和地名。
总结
注意力机制在自然语言处理中就像给AI装了一个“智能聚光灯”,让它能快速找到并处理关键信息。无论是翻译、生成、问答还是摘要,注意力机制都让AI变得更聪明、更高效。可以说,没有它,就没有今天强大的ChatGPT、语音助手和翻译工具!
4、注意力机制的特点和优势
特点(它和其他技术有什么不同?)
- 动态权重分配:
-
- 像手电筒照重点:传统AI处理信息时“平均用力”,而注意力机制像手电筒一样,随时调整光束,只照亮当前任务最相关的部分。
- 例如:翻译“我爱吃苹果”时,AI翻译到“苹果”这个词时,手电筒会突然照向原句中的“苹果”。
- 处理长距离依赖:
-
- 解决“健忘症”:传统模型处理长句子(比如一整段话)时,容易忘记开头说了什么。注意力机制让AI能随时“回头看”前面重要的词。
- 比如翻译“虽然今天下雨,但我还是决定出门,因为我想去买一本关于人工智能的书”,AI翻译到“书”时,依然记得开头的“下雨”和“出门”。
- 并行计算能力:
-
- 多任务同时处理:注意力机制可以让AI同时关注多个位置的信息(比如同时注意句子的开头、中间和结尾),而不是只能一步步按顺序处理。
- 可解释性:
-
- 知道AI在想什么:通过观察注意力权重的分布,我们能大概看出AI在处理任务时关注了哪些词。
- 比如AI回答问题时,如果注意力集中在“时间”“地点”等词上,说明它可能正在提取事件的关键信息。
优势(为什么它厉害?)
- 提升准确性:
-
- 传统方法容易漏掉关键信息,而注意力机制让AI更精准地抓住重点。
- 例子:问答系统中,AI靠注意力机制从长文中快速定位答案,正确率大幅提高。
- 灵活性高:
-
- 不依赖固定规则,而是根据任务动态调整关注点,适合处理复杂多变的场景。
- 例子:ChatGPT和你聊天时,能根据你上一句话的内容调整回复重点,而不是机械地重复模板。
- 处理长文本更高效:
-
- 传统模型处理长文本时计算量大、速度慢,注意力机制通过“选择性关注”减少了不必要的计算。
- 例子:生成一篇1000字的文章时,AI不需要从头到尾反复计算每个词的关系,只需在关键位置分配注意力。
- 推动生成式AI的突破:
-
- 注意力机制是生成文本、图片、语音的核心技术,让AI能创作更连贯、更符合人类逻辑的内容。
- 例子:AI画图工具(如Midjourney)根据你输入的“星空下的鲸鱼”,自动聚焦“星空”和“鲸鱼”来生成画面。
总结
注意力机制像给AI装了一个“智能聚光灯+记忆增强器”,让它能动态聚焦重点、处理复杂任务,同时避免“捡了芝麻丢西瓜”。这些特点直接推动了翻译、对话、创作等AI应用的实用化,让今天的AI更接近人类的思维方式。
5、注意力机制的分类
注意力机制有很多种类型,不同分类适用于不同场景。我来用通俗的例子解释最常见的几种分类:
1. 自注意力(Self-Attention)
定义:让AI在处理一段信息(比如一句话)时,自己分析内部各个部分之间的关系。
例子:
读句子“猫追老鼠,结果老鼠逃到了洞里”,AI会通过自注意力发现“猫”和“老鼠”是动作的发出者,“追”和“逃”是关联的动作。 应用:ChatGPT、BERT等模型的核心技术,用于理解上下文关系。
2. 交叉注意力(Cross-Attention)
定义:让AI在处理两个不同信息源时,建立它们之间的联系。
例子:
翻译任务:把中文“我爱吃苹果”翻译成英文,AI用交叉注意力让英文的“apple”对应中文的“苹果”。
问答任务:根据问题“谁发明了电灯?”,AI从文章中找到“爱迪生”作为答案。 应用:机器翻译、问答系统。
3. 全局注意力(Global Attention) vs 局部注意力(Local Attention)
全局注意力:AI关注输入信息的全部内容。
例子:总结一篇长文章时,AI需要通读全文,关注每一个段落。
局部注意力:AI只关注输入信息的一部分(比如某个窗口内的内容)。
例子:实时语音识别时,AI只需关注当前几秒的语音片段,而不是全部历史。 应用:全局用于文本摘要,局部用于实时任务(如语音识别)。
4. 硬注意力(Hard Attention) vs 软注意力(Soft Attention)
硬注意力:AI“非黑即白”地选择关注某个位置(比如只关注一个词)。
例子:从句子“巴黎是法国的首都”中,硬注意力可能只选“巴黎”和“首都”两个词。
软注意力:AI给不同位置分配权重(比如关注多个词,但程度不同)。
例子:翻译“美味的苹果”时,软注意力会给“美味”权重30%,“苹果”权重70%。 应用:硬注意力适合需要明确决策的任务(如图像焦点识别),软注意力更常用(如翻译、生成任务)。
5. 多头注意力(Multi-Head Attention)
定义:让AI同时用多组“注意力”从不同角度分析信息,最后综合结果。
例子:
读句子“他打开银行账户,然后去河边散步”,AI用多头注意力分别分析:
第一组注意“银行”作为金融机构;
第二组注意“河边”作为地点。 应用:Transformer模型的核心技术,提升模型理解复杂语义的能力。
总结
自注意力:自己分析内部关系(适合理解上下文)。
交叉注意力:连接两个不同信息(适合翻译、问答)。
全局/局部:关注全部或部分内容(根据任务需求调整范围)。
硬/软注意力:选择关注方式(硬是二选一,软是分轻重)。
多头注意力:多角度分析,避免“偏科”(让AI更全面)。
这些分类就像不同的“工具”,AI根据不同任务选择合适的注意力机制,就像人类在不同场景下调整自己的专注方式一样。
三、Transformer
1、Transformer 是什么?
Transformer 是一种深度学习模型,专门用于处理序列数据(比如文字、语音)。它是当今 ChatGPT、翻译工具、语音识别的核心技术之一。
核心特点:
完全依赖注意力机制(尤其是自注意力),而不是传统的循环神经网络(RNN)。
能并行处理数据,训练速度更快,且擅长捕捉长距离依赖关系(比如理解长篇文章的上下文)。
2、Transformer 是如何诞生的?
背景:
2017年之前:主流的序列模型是 RNN(循环神经网络)和 LSTM(长短期记忆网络),但它们有两个致命缺点:
速度慢:必须按顺序逐字处理数据(比如读一句话要从左到右一个个字处理)。
健忘症:难以记住长距离的信息(比如翻译一本小说,读到后面忘了前面的关键人物)。
突破:
2017年:Google 团队在论文《Attention Is All You Need》中提出了 Transformer,彻底抛弃了 RNN,只用注意力机制构建模型,解决了上述问题。
意义:从此,Transformer 成为 NLP(自然语言处理)的基石,催生了后来的 BERT、GPT 等革命性模型。
3、Transformer 的构成
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 堆叠而成(类似乐高积木),下面拆解它的核心组件:
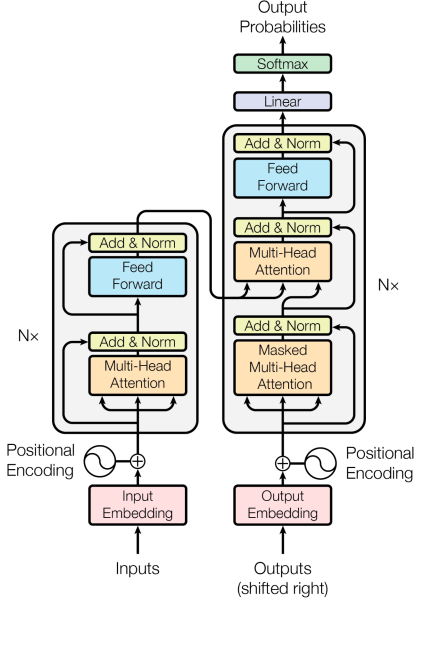
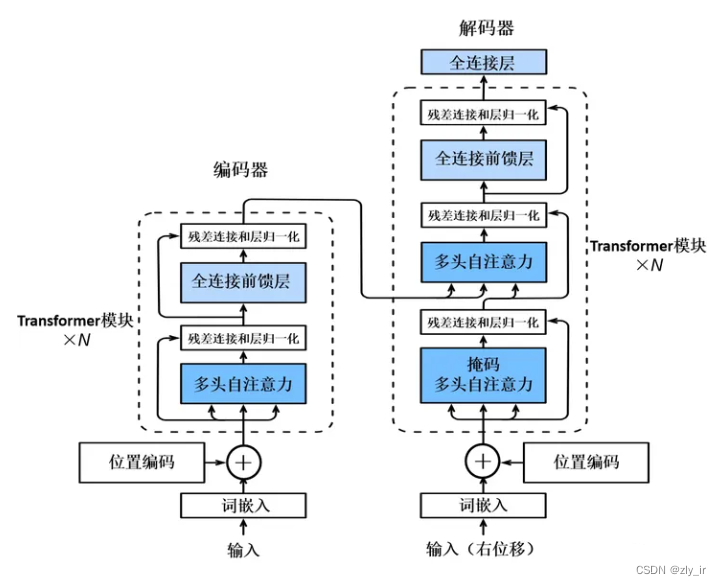
- 编码器(Encoder)
功能:把输入(比如一句话)转换成计算机能理解的“含义向量”。
结构:
① 自注意力层(Self-Attention):让模型分析输入中每个词与其他词的关系(比如“猫”和“追”的关系)。
② 前馈神经网络(Feed Forward):进一步处理自注意力层的输出,提取更复杂的特征。
③ 残差连接 & 层归一化:防止训练过程中信息丢失,稳定模型学习(类似“防崩溃装置”)。 - 解码器(Decoder)
功能:根据编码器的“含义向量”生成输出(比如翻译后的句子)。
结构:
① 掩码自注意力层(Masked Self-Attention):生成输出时,只能看到已生成的部分(防止作弊)。
② 交叉注意力层(Cross-Attention):连接编码器和解码器,让解码器关注编码器的关键信息。
③ 前馈神经网络 & 残差连接:同编码器。 - 位置编码(Positional Encoding)
功能:告诉模型每个词的位置信息(因为自注意力本身不考虑顺序)。
实现:给每个词的位置(比如第1个词、第2个词)加上一个独特的编码向量。
类比:就像给书页加上页码,即使打乱顺序也能知道原来的位置。 - 多头注意力(Multi-Head Attention)
功能:让模型同时从多个角度分析词之间的关系(比如一词多义)。
例子:
词“苹果”可以是水果,也可以是公司名。多头注意力让模型同时关注两种可能性,再综合判断。
四、举个生活化的例子
任务:用 Transformer 把中文“我爱吃苹果”翻译成英文“I love eating apples”。
编码器工作:
分析“我”“爱”“吃”“苹果”之间的关系,发现“苹果”是动作的宾语。
生成一个包含整句含义的向量。
解码器工作:
根据编码器的向量,逐步生成英文词:首先生成“I”,然后关注“爱”(对应“love”),再关注“吃”(对应“eating”),最后根据“苹果”确定复数形式“apples”。
位置编码:确保“我”在句首,“苹果”在句尾的位置信息不被忽略。
4、Transformer 的意义
优势:
并行计算 → 训练速度比 RNN 快几十倍。
自注意力 → 轻松捕捉长距离依赖(比如整篇文章的上下文)。
应用:几乎所有现代AI模型都基于 Transformer,如:
GPT(生成文本)、BERT(理解语义)、T5(文本转换)、DALL·E(生成图片)。
总结
Transformer 就像一台“超级翻译机+写作机器人”,通过自注意力机制和多层堆叠结构,实现了高效、精准的序列处理。它的诞生彻底改变了AI领域,让机器能真正理解并生成复杂的语言!
四、GPT与BERT
1、GPT 和 BERT 有什么不同
- 任务类型:
-
- BERT:像是一个“阅读理解高手”。它能同时看到一句话的前后所有词,适合做“理解类”任务,比如:
-
-
- 判断句子是夸人还是骂人(情感分析)。
- 从文章中找出人名、地名(实体识别)。
- 回答问题(比如考试中的阅读理解题)。
-
-
- GPT:像是一个“作家”。它只能从左到右逐字写文章,适合做“写作文”的任务,比如:
-
-
- 和你聊天(比如ChatGPT)。
- 编故事、写邮件、生成代码。
- 续写一段话(比如输入前半句,它补全后半句)。
-
- 工作原理:
-
- BERT:训练时像“完形填空”。比如把句子里的某个词遮住(比如“今天天气真__”),让它猜被遮住的词(可能是“好”或“差”)。
- GPT:训练时像“接龙游戏”。比如给前半句“今天天气真”,它必须接着猜下一个词(比如“好”),然后继续猜“好”后面的词,直到写完。
- 举个生活例子:
-
- 如果问:“苹果公司总部在哪里?”
-
-
- BERT会直接回答:“美国加州”。(因为它理解问题,从知识库找答案)
- GPT可能会写:“苹果公司总部位于美国加州,这里有很多创新的科技产品……”(因为它擅长生成完整句子)。
-
2、发展方向有什么不同?
- BERT:
-
- 变得更小、更快:比如开发迷你版BERT,让手机也能运行,方便用在APP里。
- 更懂专业领域:比如用在医疗领域,让它能看懂病历、诊断报告。
- 结合图片、声音:比如给一张图,它能描述图中的内容(比如:“一只猫在沙发上睡觉”)。
- GPT:
-
- 变得更大、更全能:比如GPT-4,参数更多,能写更复杂的文章,甚至理解图片和表格。
- 更像真人聊天:减少胡说八道,更符合逻辑,还能记住之前的对话(比如你让它扮演老师,它会一直保持这个角色)。
- 帮你干活:比如自动写代码、做PPT、分析数据,直接帮你完成任务。
总结
- BERT:适合“需要动脑子”的任务,比如分析、找答案。
- GPT:适合“动手写东西”的任务,比如聊天、写文章。
- 未来:两者都会更强大,但一个偏向“理解”,一个偏向“生成”,就像人脑的“左脑和右脑”分工合作。
3、除了GPT和BERT,还有哪些常见的自然语言处理模型?
除了GPT和BERT,自然语言处理(NLP)领域还有许多其他重要模型和架构。以下是几种常见的模型及其特点:
1. Transformer
- 特点:Transformer是GPT和BERT的基础架构,由编码器(Encoder)和解码器(Decoder)组成,使用自注意力机制(Self-Attention)捕捉长距离依赖关系。
- 应用:机器翻译、文本生成等。
- 代表模型:原始的Transformer模型(2017年提出)。
2. T5(Text-to-Text Transfer Transformer)
- 特点:将所有NLP任务都统一为“文本到文本”的格式,比如输入一个问题,输出一个答案。
- 应用:翻译、摘要、分类、问答等。
- 优点:通用性强,适合多种任务。
3. XLNet
- 特点:结合了GPT的自回归和BERT的双向注意力机制,通过排列语言模型(Permutation Language Modeling)捕捉更全面的上下文信息。
- 应用:文本分类、问答、生成等。
- 优点:比BERT在某些任务上表现更好。
4. RoBERTa(Robustly Optimized BERT Pretraining Approach)
- 特点:BERT的改进版,通过更长的训练时间、更大的批次和更多的数据优化预训练过程。
- 应用:与BERT类似,但在很多任务上表现更优。
- 优点:训练更充分,效果更好。
5. ALBERT(A Lite BERT)
- 特点:BERT的轻量版,通过参数共享和分解技术减少模型参数量,同时保持性能。
- 应用:适合资源有限的场景,如移动设备。
- 优点:更小、更快、更省资源。
6. BART(Bidirectional and Auto-Regressive Transformer)
- 特点:结合了BERT的双向编码和GPT的自回归解码,适合生成和理解任务。
- 应用:文本生成、摘要、翻译等。
- 优点:在生成任务上表现优异。
7. ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
- 特点:用“替换检测”任务代替BERT的“掩码语言模型”,训练效率更高。
- 应用:与BERT类似,但训练更快。
- 优点:训练成本低,效果接近BERT。
8. DistilBERT
- 特点:BERT的压缩版,通过知识蒸馏技术减少模型大小,同时保留大部分性能。
- 应用:适合需要快速推理的场景。
- 优点:更轻量、更快。
9. GPT系列(如GPT-2、GPT-3、GPT-4)
- 特点:基于Transformer解码器的生成模型,参数规模不断增大,生成能力越来越强。
- 应用:文本生成、对话系统、代码生成等。
- 优点:生成文本质量高,适合开放任务。
10. ULMFiT(Universal Language Model Fine-Tuning)
- 特点:专注于迁移学习,通过预训练和微调技术在小数据集上取得好效果。
- 应用:文本分类、情感分析等。
- 优点:适合小数据场景。
11. Word2Vec
- 特点:经典的词向量模型,将词语映射到低维空间,捕捉语义关系。
- 应用:词向量表示、文本分类等。
- 优点:简单高效,适合基础任务。
12. FastText
- 特点:Word2Vec的扩展,支持子词(subword)信息,适合处理未登录词。
- 应用:词向量表示、文本分类等。
- 优点:对生僻词处理更好。
13. ELMo(Embeddings from Language Models)
- 特点:动态词向量模型,根据上下文生成不同的词向量。
- 应用:文本分类、问答等。
- 优点:能捕捉多义词的不同含义。
14. ERNIE(Enhanced Representation through kNowledge Integration)
- 特点:结合知识图谱信息,增强语义理解能力。
- 应用:问答、文本分类等。
- 优点:在中文任务上表现优异。
总结
这些模型各有特点,适合不同的任务和场景:
- 理解类任务:BERT、RoBERTa、ALBERT、ELECTRA。
- 生成类任务:GPT系列、T5、BART。
- 轻量级应用:DistilBERT、ALBERT。
- 经典任务:Word2Vec、FastText、ELMo。
随着NLP技术的快速发展,这些模型也在不断演进,推动人工智能在语言理解与生成方面的进步。

4、发展路线
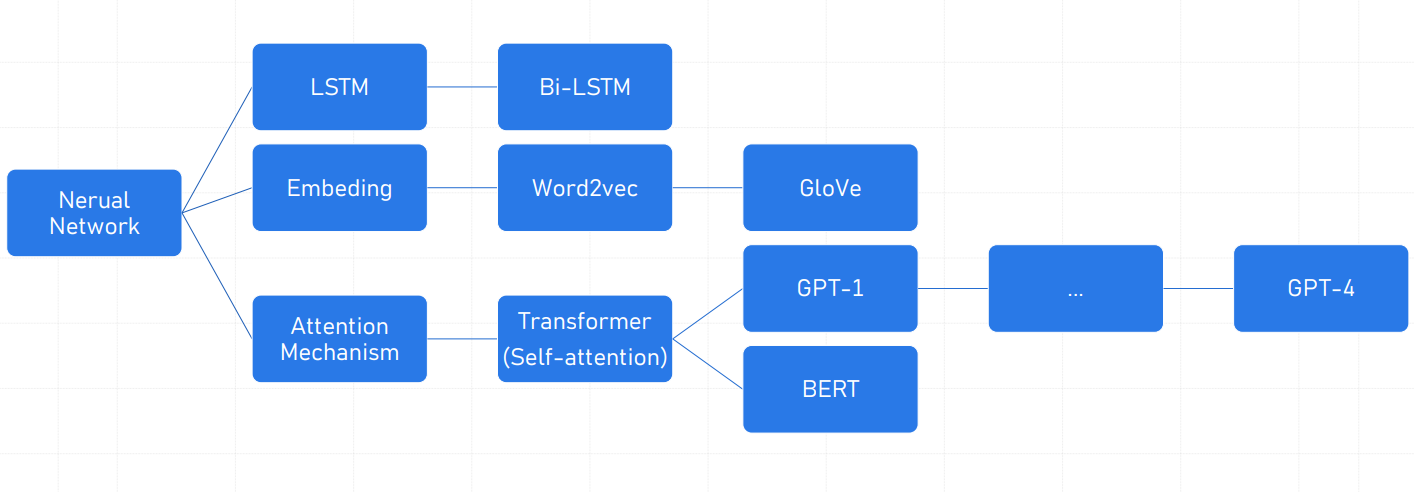
这张图就像一份「神经网络技术家谱」,展示了从基础技术到现代热门AI模型的发展路线。主要分三大支线:
第一支:记忆高手(LSTM系列)
- 起点:最早的 LSTM(长短期记忆网络),专门解决「记不住久远信息」的问题(比如读小说时记得前几章的情节)。
- 升级版:Bi-LSTM(双向LSTM),同时分析「过去+未来」的上下文(比如读一句话时,同时看前文和后文)。
第二支:文字翻译官(词向量技术)
- 起点:Embedding(词嵌入),把词语变成数字向量(比如“猫”=[0.2, 0.5, -0.3]),方便计算机理解。
- 两大经典方法:
-
- Word2vec:通过词语的邻居关系学习向量(比如“国王-男+女=女王”)。
- GloVe:用全局统计信息+上下文一起训练向量(类似“大数据分析”版词向量)。
第三支:注意力革命(Transformer与GPT/BERT)
- 起点:注意力机制(Attention),让模型学会“抓重点”(比如翻译时,自动关注关键词语)。
- 核心突破:Transformer(自注意力模型),彻底抛弃循环结构,实现高效并行计算(处理长文本更快)。
- 两大顶流模型:
-
- GPT系列(如GPT-4):专注“写作文”,从左到右生成文本(像ChatGPT聊天)。
- BERT:专注“阅读理解”,同时分析全文(像考试时快速找答案)。
这张图想说啥?
技术发展就像一棵树:
- 早期技术(LSTM、词向量)解决基础问题(记忆、语义表示)。
- 注意力机制带来革命,催生出Transformer架构。
- Transformer分支演化出两大方向:生成(GPT)与理解(BERT),最终诞生了如今强大的AI模型(如GPT-4)。
简单来说:AI的进化,就是从“模仿记忆”到“学会抓重点”,再到“能写能读”的全能选手!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











