






 本文介绍了深度学习中的求导方法,如链式法则和反向传播,以及线性回归的损失函数和优化策略,包括梯度下降和PyTorch示例。此外,还详细讲解了Softmax回归及其在分类问题中的应用,以及常用的损失函数和初始化方法。
本文介绍了深度学习中的求导方法,如链式法则和反向传播,以及线性回归的损失函数和优化策略,包括梯度下降和PyTorch示例。此外,还详细讲解了Softmax回归及其在分类问题中的应用,以及常用的损失函数和初始化方法。
前言
学习资源在
预备知识整理-1
一、求导方法
链式法则:
∂
y
∂
x
=
∂
y
∂
u
n
∂
u
n
∂
u
n
−
1
.
.
.
∂
u
2
∂
u
1
∂
u
1
∂
x
\frac{\partial y}{\partial x}=\frac{\partial y}{\partial u_n}\frac{\partial u_n}{\partial u_{n-1}}...\frac{\partial u_2}{\partial u_1}\frac{\partial u_1}{\partial x}
∂x∂y=∂un∂y∂un−1∂un...∂u1∂u2∂x∂u1
正向累积
∂
y
∂
x
=
∂
y
∂
u
n
(
∂
u
n
∂
u
n
−
1
(
.
.
.
(
∂
u
2
∂
u
1
∂
u
1
∂
x
)
)
)
\frac{\partial y}{\partial x}=\frac{\partial y}{\partial u_n}(\frac{\partial u_n}{\partial u_{n-1}}(...(\frac{\partial u_2}{\partial u_1}\frac{\partial u_1}{\partial x})))
∂x∂y=∂un∂y(∂un−1∂un(...(∂u1∂u2∂x∂u1)))
反向累积(反向传递)
∂
y
∂
x
=
(
(
(
∂
y
∂
u
n
∂
u
n
∂
u
n
−
1
)
.
.
.
)
∂
u
2
∂
u
1
)
∂
u
1
∂
x
)
\frac{\partial y}{\partial x}=(((\frac{\partial y}{\partial u_n}\frac{\partial u_n}{\partial u_{n-1}})...)\frac{\partial u_2}{\partial u_1})\frac{\partial u_1}{\partial x})
∂x∂y=(((∂un∂y∂un−1∂un)...)∂u1∂u2)∂x∂u1)
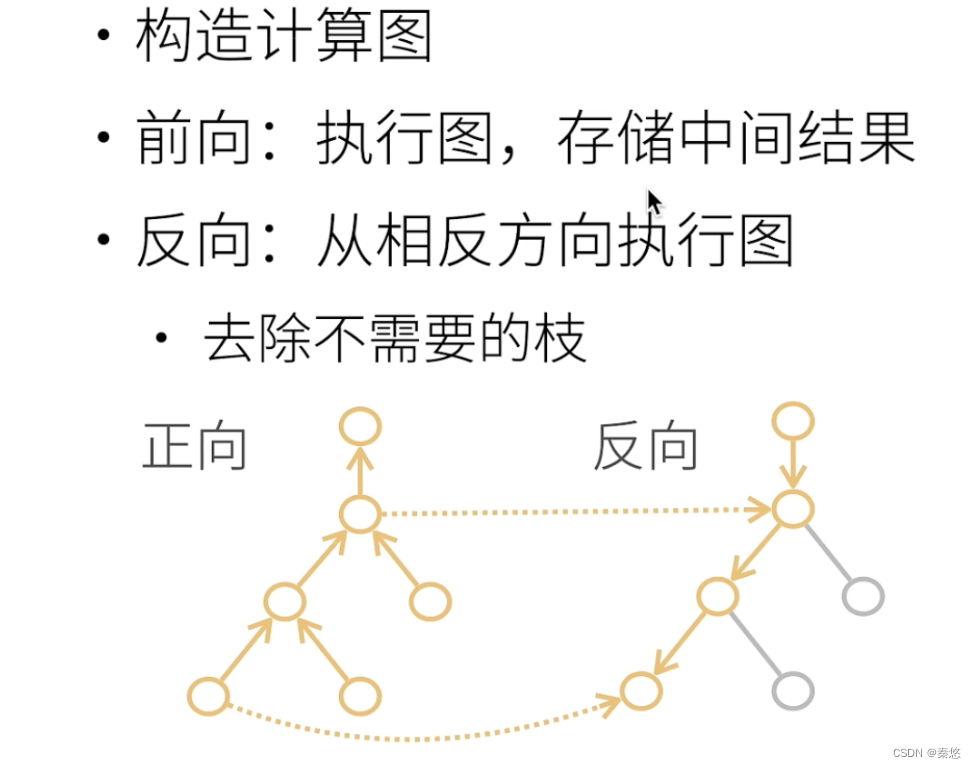
深度学习一般对标量求导而不是矩阵或向量(detach或sum)
pytorch默认累加梯度,注意清零。
获取grad前需要backward。
以
y
=
2
x
2
x
y=2x^2x
y=2x2x自动求导实现为例
improt torch
x=torch.arange(4.0)
x.requires_grad_(True) #等价于 x=torch.arange(4.0,requeires_grad=True)
x.grad #默认为None
y=2*torch.dot(x,x)
y.backward()#通过调用反向传播函数计算y关于x每个分量的梯度
x.grad==4*x # tensor([True,True,True,True])
#在默认情况下,pytorch会累积梯度
x.grad.zero_()
y=x.sum()
y.backward()
x.grad
二、线性回归
假设自变量和因变量是线性关系,因变量可以表示为自变量中元素的加权和,假设任何噪声都比较正常,遵循正态分布等。(在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。)
房价预估问题:
3.1.1是输入特征的一个Affine transformation,并通过偏置项进行平移。
p
r
i
c
e
=
w
a
r
e
a
∗
a
r
e
a
+
w
a
g
e
∗
a
g
e
+
b
(3.1.1)
price=w_area*area+w_{age*age+b}\tag{3.1.1}
price=warea∗area+wage∗age+b(3.1.1)
损失函数
通常选择非负数作为损失,回归问题常用平方误差函数。
l
(
i
)
(
w
,
b
)
=
1
2
(
y
^
(
i
)
−
y
(
i
)
)
2
l^{(i)}(w,b)=\frac{1}{2}(\hat{y}^{(i)}-y^{(i)})^2
l(i)(w,b)=21(y^(i)−y(i))2
为了度量模型在整个数据集上的质量,我们需计算在所有训练样本上的总损失。
L
(
w
,
b
)
=
1
n
∑
i
=
1
n
l
(
i
)
(
w
,
b
)
=
1
n
∑
i
=
1
n
1
2
(
w
T
x
(
i
)
+
b
−
y
(
i
)
)
2
(3.1.6)
L(w,b)=\frac{1}{n}\sum^{n}_{i=1}l^{(i)}(w,b)=\frac{1}{n}\sum^{n}_{i=1}\frac{1}{2}(w^Tx^{(i)}+b-y^{(i)})^{2}\tag{3.1.6}
L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(wTx(i)+b−y(i))2(3.1.6)
解析解不能广泛用于深度学习
优化方法
梯度下降
挑选一个初始值
w
0
w_0
w0,重复迭代参数t=1,2,3,更新法则:通过不断沿着反梯度方向更新参数,小批量随机梯度下降是深度学习默认的求解算法。
w
t
=
w
t
−
1
−
η
δ
l
δ
w
t
−
1
w_t=w_{t-1}-\eta\frac{\delta l}{\delta w_{t-1}}
wt=wt−1−ηδwt−1δl
超参数( 学习率、批量大小) 不能太小,也不能太大
矢量化加速:以不在for循环里多次依赖“+”运算为例,数学表达上更简洁,同时运行的更快。
线性回归模型是一个简单的神经网络。图3.1.2中,每个输入都与每个输出相连,成为全连接层或稠密层。

线性回归的简洁实现
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()#每一次epoch清空梯度
l.backward()#将损失反向传播
trainer.step()#更新模型参数
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
三、Softmax回归
应用于分类问题
独热编码 one-hot-encoder
全连接层:对于具有d个输入和q个输出的全连接层,参数开销为 O ( d q ) O(dq) O(dq) 可减小为 O ( d q / n ) O(dq/n) O(dq/n)
softmax函数可以将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。虽然是一个非线性回归变换,但是输出仍然是输入特征的仿射变换,因此其是一个线性模型。
softmax函数:
y
k
=
exp
(
a
k
)
∑
n
i
=
1
exp
(
a
i
)
(3.10)
y_k=\frac{\exp(a_k)}{\sum^{i=1}_{n}\exp(a_i)} \tag{3.10}
yk=∑ni=1exp(ai)exp(ak)(3.10)
计算机在处理数时,数值必须在4字节或8字节的有限数据宽度内,这意味着数存在有效位数,可以表示的数值范围是有限的。
考虑溢出对softmax函数改进:
y
k
=
exp
(
a
k
)
∑
n
i
=
1
exp
(
a
i
)
=
C
exp
(
a
k
)
C
∑
n
i
=
1
exp
(
a
i
)
=
exp
(
a
k
+
log
C
)
∑
n
i
=
1
exp
(
a
i
)
+
log
C
=
exp
(
a
k
+
C
′
)
∑
n
i
=
1
exp
(
a
i
+
C
′
)
(3.11)
y_k=\frac{\exp(a_k)}{\sum^{i=1}_{n}\exp(a_i)} \\ =\frac{C\exp(a_k)}{C\sum^{i=1}_{n}\exp(a_i)} \\ =\frac{\exp(a_k+\log C)}{\sum^{i=1}_{n}\exp(a_i)+\log C} \\ =\frac{\exp(a_k+C^{'})}{\sum^{i=1}_{n}\exp(a_i+C^{'})} \tag{3.11}
yk=∑ni=1exp(ai)exp(ak)=C∑ni=1exp(ai)Cexp(ak)=∑ni=1exp(ai)+logCexp(ak+logC)=∑ni=1exp(ai+C′)exp(ak+C′)(3.11)
C
′
C^{'}
C′可以取任何值,一般使用输入信号中的最大值
def softmax(a):
c=np.max(a)
exp_a=np.exp(a-c)
sum_exp_a=np.sum(exp_a)
y=exp_a/sum_exp_a
return y
softmax函数的特征:输出总和为1,因此可以将其输出解释为概率
一般而言,神经网络只把输出值最大的神经元对应的类别作为识别结果。
输出层的神经元数量:分类时,一般设为类别的数量。
神经网络的“推理处理”,称为神经网络的前向传播(forward propagation)
常用损失函数和初始化方法
https://pytorch.org/docs/2.0/nn.html#loss-functions
https://pytorch.org/docs/2.0/nn.init.html
总结
回归与分类















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









