







IO流03
A.引入字节缓冲流
1)计算机识别汉字
计算机是何如识别中文这样的字符的,一个中文对应两个字节
第一个字节:肯定是否负数
第二个字节:可是负数,也可以是正数,对实际是没有影响的
import java.util.Arrays; public class Demo01 { public static void main(String[] args) { String s = "我爱你中国"; byte[] bys = s.getBytes(); System.out.println(Arrays.toString(bys)); // [-50, -46, -80, -82, -60, -29, -42, -48, -71, -6] } }
2)需求
在当前项目有一个a.txt文件,然后我要将a.txt文件的内容复制到当前文件下的b.txt文件
复制文件:
源文件:当前项目下的a.txt文件---->读数据------>FlieInputStream
目的地文件:当前项目下的b.txt文件------>写数据------>FileOutputStream
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class Demo01 { public static void main(String[] args) throws IOException { // 封装源文件 FileInputStream fis = new FileInputStream("a.txt"); // 为了方便演示,在main方法直接抛出异常 // 封装目的文件 FileOutputStream fos = new FileOutputStream("b.txt"); // 一次读取一个字节 int by = 0; while ((by = fis.read()) != -1) { // 读一个写一个 fos.write(by); } // 释放资源:后开先关 fos.close(); fis.close(); } }
上一章使用FileInputStream一次读取一个字节,控制台出现中文乱码
而现在这种情况,没有出现中文乱码
上一章的写法:存在强制类型转换:把字节转换成了字符
而一个字符对应2个字节,出现中文乱码;
程序中:每次读一个字节,就写一个字节
并没有出现类型转换的问题,所以不会出现中文乱码;
3)需求
将上面的需求,使用字节数组复制
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class Demo02 { public static void main(String[] args) throws IOException { // 封装源文件 FileInputStream fis = new FileInputStream("a.txt"); // 目的 FileOutputStream fos = new FileOutputStream("b.txt"); byte[] bys = new byte[1024]; int len = 0; while ((len = fis.read(bys)) != -1) { fos.write(bys, 0, len); } // 释放资源 fos.close(); fis.close(); } }
4)扩展
上面的复制过程非常快!几乎就是一瞬间的事情
如果将上面的目标换成内存大的mov\mp4\exe\jpg文件
自行尝试计算下程序运行时间(用System.currentTimeMillis()方法)
定义一个字节数组的时候,读取的速度比一次读取一个字节快
为了提高读取的速度,java就给我们提供了字节缓冲输入流和字节缓冲输出流
高效流
B.字节缓冲输出流BufferedOutputStream
1)构造方法
public BufferedOutputStream(OutputStream out):推荐使用第一种
public BufferedOutputStream(OutputStream out, int size):指定一个缓冲区大小
第二种不用,因为第一种构造方法默认的缓冲区大小足够存储数据
import java.io.BufferedOutputStream; import java.io.FileOutputStream; import java.io.IOException; public class Demo03 { public static void main(String[] args) throws IOException { BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("box.txt")); // 写数据 bos.write("hello".getBytes()); // 释放资源 bos.close(); } }
2)其余用法跟OutputStream用法一样字节缓冲输出流中为什么不直接将文件的路径或者文件夹的路径作为参数,为什么是OutputSteram?
缓冲流只是为了高效而设计的,只是构造了一个缓冲区,要进行读写操作还需要使用基本的流对象!
OutputStream:本身是抽象类,不能直接实例化
BufferedOutputStream(new FileOutputStream("路径抽象表现形式"))
又属于java一种设计模式:装饰者设计模式
C.字节缓冲输入流BufferedInputStream
1)概述
在同一个对象中:读数据只能是一种方式
要么一次读取一个字节,要么就是一次读取一个字节数组
import java.io.BufferedInputStream; import java.io.FileInputStream; import java.io.IOException; public class Demo04 { public static void main(String[] args) throws IOException { BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt")); // 读取数据:一次读取一个字节 // int by = 0 ; // while((by=bis.read()) !=-1){ // System.out.println((char)by); // } // 一次读一个字节数组 byte[] bys = new byte[1024]; int len = 0; while ((len = bis.read(bys)) != -1) { System.out.println(new String(bys, 0, len)); } bis.close(); } }
2)其余用法和InputStream一样
D.字节流中读取MP4视频这样的效率问题!
需求:复制一个视频(在此我复制eclipse安装目录,大小将近44.7M)
从E盘复制到项目目录下
import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; /* * 字节流:按照字符数组赋值:共耗时855ms * 字节缓冲流:按照字符数组赋值:共耗时167ms */ public class Demo05 { public static void main(String[] args) throws IOException { // 开始工作的毫秒值 long start = System.currentTimeMillis(); // 封装方法method1为字节流,按照字节数组复制 // method1("E:\\eclipse-inst-win64.exe", "eclipse-inst-win64.exe"); // 封装方法method2为字节缓冲流,按照字节数组复制 method2("E:\\eclipse-inst-win64.exe", "eclipse-inst-win64.exe"); // 复制完毕的毫秒值 long end = System.currentTimeMillis(); System.out.println("复制完毕!共耗时" + (end - start) + "ms"); } // 字节流 public static void method1(String src, String dest) throws IOException { // 封装源路径 FileInputStream fis = new FileInputStream(src); // 封装目的 FileOutputStream fos = new FileOutputStream(dest); byte[] bys = new byte[1024]; int len = 0; while ((len = fis.read(bys)) != -1) { fos.write(bys, 0, len); } fos.close(); fis.close(); } // 字节缓冲流 public static void method2(String src, String dest) throws IOException { // 封装源路径 BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src)); // 封装目的 BufferedOutputStream bos= new BufferedOutputStream(new FileOutputStream(dest)); byte[] bys = new byte[1024]; int len = 0; while ((len = bis.read(bys)) != -1) { bos.write(bys, 0, len); } bos.close(); bis.close(); } }
可以看出,字节缓冲流效率远大于字节流当然按字节数组复制速度也远大于一个字节一个字节复制
由于一个字节复制速度太慢,在此就不测试了

E.递归
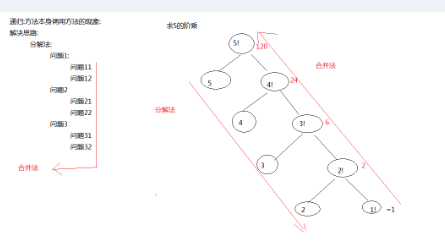
1)方法本身调用方法的一种现象!
方法嵌套:不属于递归
2)注意事项
递归必须是出口条件,还要定义方法
递归的次数不宜过多,否则则会出现内存溢出
构造方法中不能中出现递归
3)举例
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚给小\小和尚讲故事,故事是:
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚给小\小和尚讲故事,故事是:
从前有座山,山里有座庙,庙里有个老和尚和小和尚,老和尚给小\小和尚讲故事,故事是:
4)练习
求5的阶乘:
5! = 5 *4!
如果实现这个需求:
定义一个方法
出口条件
规律
public class Demo01 { public static void main(String[] args) { /** * 两个明确: * 明确返回值类型:int类型 * 参数类型:int ,int i * * 出口条件是什么: * if(i==1){return 1} * *规律 * if(i!=1){return i *jieCheng(i-1) } * */ System.out.println("5的阶乘是:" + jieCheng(5)); } public static int jieCheng(int i) { // 出口条件 if (i == 1) { return 1; } else { return i * jieCheng(i - 1); } } }
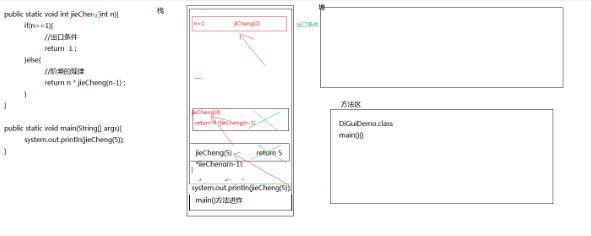
5)练习
有一对兔子,从出生后第3个月起每个月都生一对兔子
小兔子长到第三个月后每个月又生一对兔子
假如兔子都不死,问第二十个月的兔子对数为多少?不死神兔
分析:
兔子的对数的规律:
第一个月:1
第二个月:1
第三个月:2
第四个月:3
第五个月:5
第六个月:8第一个月和和第二个月都是1
从第三个月开始,每个月的数据:是前两个月之后,前两个月的数据是已知的都是:1
我们把相邻俩个月的数据看是:a,b
那么第一个相邻的数据:a=1,b=1
第二个相邻的数据:a=1,b=2
第三个相邻的数据:a=2,b=3;
第四个相邻的数据:a=3,b=5
...
下一次的a是上一次是b,下一次的b是上一次的a+b
public class Demo02 { public static void main(String[] args) { // 1)数组实现 int[] arr = new int[20]; arr[0] = 1; arr[1] = 1; for (int i = 2; i < arr.length; i++) { arr[i] = arr[i - 2] + arr[i - 1]; } System.out.println("兔子数:" + arr[19] + "对"); // 2)中间变量 int a = 1; int b = 1; for (int i = 0; i < 18; i++) { // 使用中间变量进行 int temp = a; a = b; b = temp + b; } System.out.println("兔子数:" + b + "对"); // 3)递归 System.out.println("兔子数:" + fib(20) + "对"); } public static int fib(int i) { if (i == 1 || i == 2) { return 1; } else { return fib(i - 1) + fib(i - 2); } } }
6)需求
需求:使用递归实现删除带内容的目录
当前项目下有一个demo文件夹
分析:
a.封装当前目录:封装成File对象
b.获取当前目录下的所有的文件以及文件夹的File数组
c.对File数组进行非空判断,遍历,获取每一个file对象
判断:是否是文件夹
是:回到(b)
不是:删除
import java.io.File; public class Demo03 { public static void main(String[] args) { // 封装目录 File srcFloder = new File("demo"); // 删除文件夹的方法 deleteFloder(srcFloder); } public static void deleteFloder(File srcFloder) { // 获取当前目录下的所有文件以及文件夹的File数组 File[] fileArr = srcFloder.listFiles(); // 非空判断:当对象不为空的时候,才能进行遍历 if (fileArr != null) { // 使用增强for遍历,获取每一个file对象 for (File file : fileArr) { // 再次判断file对象是否是文件夹 if (file.isDirectory()) { // 是文件夹:回到这里进行删除 deleteFloder(file); } else { // 删除文件 System.out.println(file.getName() + "---" + file.delete()); } } System.out.println(srcFloder.getName() + "---" + srcFloder.delete()); } } }
7)需求
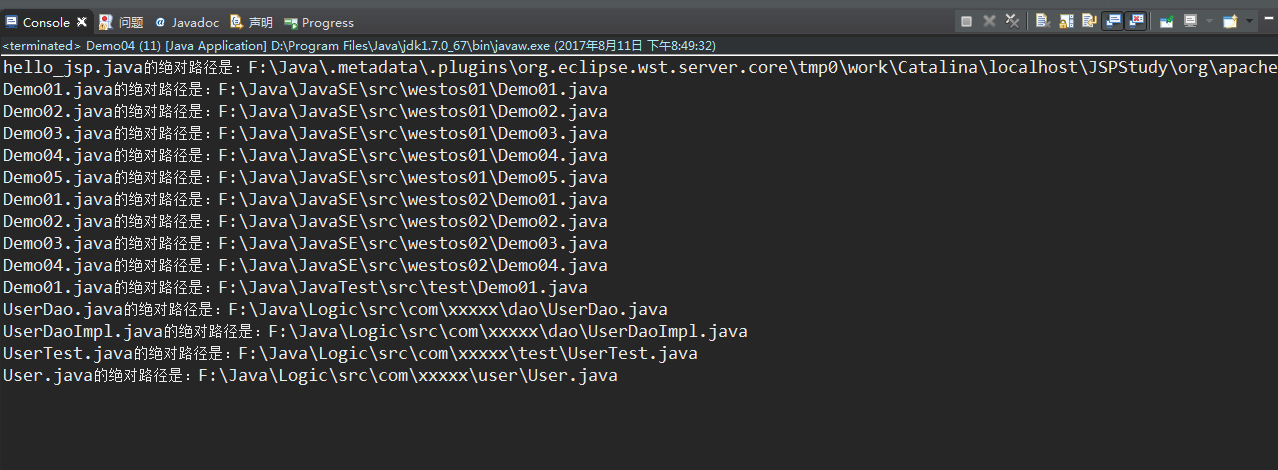
请大家把F:\Java目录下所有的java结尾的文件的绝对路径给输出在控制台
分析:
A:封装目录
B:获取该目录下的所有的文件以及文件夹的File数组
C:给改数组的对象进行非空判断,遍历
D:判断该file是否是文件夹
是:回B
不是:
再次判断否是以.java结尾的文件
是:输出绝对路径
import java.io.File; public class Demo04 { public static void main(String[] args) { // 封装目录 File srcFolder = new File("F:\\Java"); // 写一个获取文件绝对路径的方法 getAllJavaFilePaths(srcFolder); } public static void getAllJavaFilePaths(File srcFolder) { // 获取所有的文件以及文件夹的File数组 File[] fileArray = srcFolder.listFiles(); // 非空判断 if (fileArray != null) { // 遍历 for (File file : fileArray) { // 判断是否是文件夹 if (file.isDirectory()) { getAllJavaFilePaths(file); } else { // 再次判断是否以.java结尾的文件 if (file.getName().endsWith(".java")) { System.out.println(file.getName() + "的绝对路径是:" + file.getAbsolutePath()); } } } } } }















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









