







 本文介绍了在广告SDK项目中,如何利用Mock+Proxy进行自动化测试。面临缺少服务端测试环境、协议字段多、测试用例设计挑战等问题,团队采取了预配置线上广告物料进行mock测试、制定高效测试用例策略、自动化生成测试用例,并选择了AnyProxy作为Mock框架。通过正交表法和配对测试法设计测试用例,实现了测试用例的自动化生成和Mock数据的构建,提高了测试效率和覆盖率。
本文介绍了在广告SDK项目中,如何利用Mock+Proxy进行自动化测试。面临缺少服务端测试环境、协议字段多、测试用例设计挑战等问题,团队采取了预配置线上广告物料进行mock测试、制定高效测试用例策略、自动化生成测试用例,并选择了AnyProxy作为Mock框架。通过正交表法和配对测试法设计测试用例,实现了测试用例的自动化生成和Mock数据的构建,提高了测试效率和覆盖率。
项目背景
广告SDK项目是为应用程序APP开发人员提供移动广告平台接入的API程序集合,其形态就是一个植入宿主APP的jar包。提供的功能主要有以下几点:
- 为APP请求广告内容
- 用户行为打点
- 错误日志打点
- 反作弊
团队现状
在项目推进的过程中,逐渐暴露了一些问题:
1. 项目团队分为上海团队(服务端)和北京团队(客户端),由于信息同步,人力资源等其他原因,服务端与客户端的开发进度很难保持同步,经常出现客户端等着和服务端联调的情况
2. 接口文档不稳定,理解有偏差
3. 协议变化频繁,消息不同步
4. 缺少服务端测试环境,可模拟的真实广告内容太少
5. 协议字段太多,传统的测试用例设计方法容易出现遗漏,尤其是异常情况处理,测试完成以后测试人员对字段覆盖率没有信心
协议字段示例图
{
"ads": [{
"action": { "path": "" },
"adw":920,
"adh":900,
"template": "",
"action_type": 2,
"adid": "67346778",
"adm": "",
"adm_type": 0,
"deep_link": "",
"impid": "nXcM_kqBGqL=",
"tk_act": [""],
"tk_imp":[ ""],
"tk_ad_close": [""],
"tk_clk": [""],
"tk_dl_begin": ["" ],
"tk_dl_btn": [ ""],
"tk_dl_done": [""],
"tk_dp_suc": [],
"tk_ins": [ ""],
"tk_open": [""]
}],
"errno": "0"
}- 测试用例设计极容易受需求影响,更新起来非常麻烦,成本很高
- 手工测试方法执行效率低,且容易漏测
手动测试过程示意图
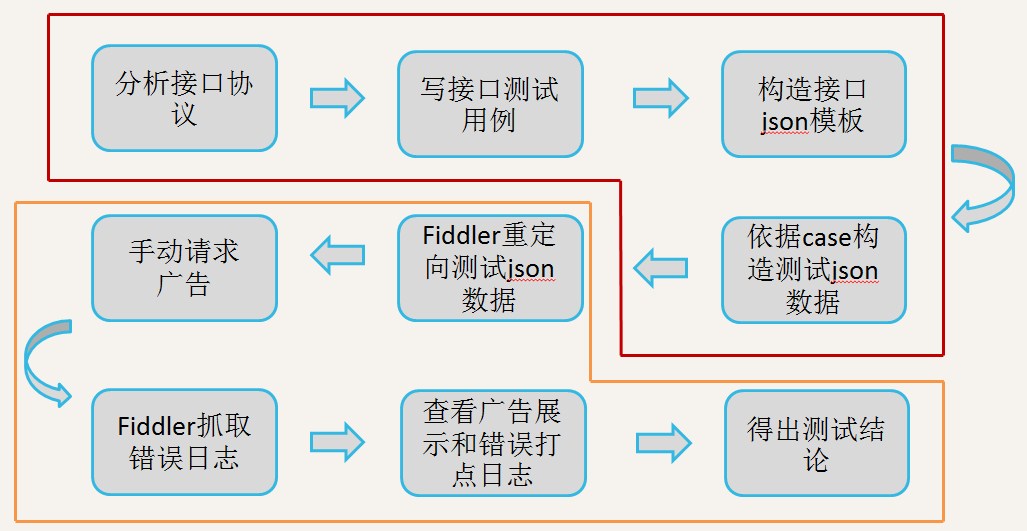
分析&思路
上述几个问题,其中1、2、3都会对我们的测试工作产生影响,但是属于项目管理范畴,不在本文讨论范围内。那么针对4、5、6、7几个问题,应该如何解决呢?
首
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









