




 本文深入探讨了状态机、定时器、消息通讯机制等关键技术,包括有限状态机、TCP状态机、即时通信协议等,同时介绍了网络IO的不同模式,如BIO、NIO和AIO。
本文深入探讨了状态机、定时器、消息通讯机制等关键技术,包括有限状态机、TCP状态机、即时通信协议等,同时介绍了网络IO的不同模式,如BIO、NIO和AIO。
通讯消息状态机
修订历史:
日期 | 版本 | 修改描述 | 修改人 |
2018/5/12 | V0.0 | 创建 | 汪坤 |
目 录
1. 简介
1. 目的
本文档描述了服务器相关的状态机,定时器,消息通讯机制,目前是为提高大家服务器相关知识的了解,为后续通讯产品的设计开发提供支持。
2. 状态机
状态机,表示若干个状态,以及在这些状态之间的转义和动作的模型。状态机是一个离散数学模型。给定一个输入集合,根据对输入的接受次序来决定一个输出集合。状态机分为有限状态机和无限状态机。有限状态理论和模型在实践中更容易检验。 有限状态机的计算能力等价于正则语言,无限状态机用于描述非确定性问题,计算能力等价于自然语言
软件设计中的状态机概念,一般是指有限状态机。有限状态机(finite-state machine)FSM, 输入集合和输出集合都是有限的,并只有有限数目的状态。 一般说到状态机即是对有限状态机的简称。
2.1 有限状态机
有限状态机可分为为摩尔(Moore)型状态机和米莉(Mealy)型状态机,摩尔(Moore)型状态机,输出只依赖于状态。Moore模型的好处是行为的简单性。图1的例子展示了一个电梯门的Moore FSM。这个状态机识别两个命令:“command_open”和“command_close”触发状态变更。在状态“Opening”中的进入动作 (E:)开启电机开门,在状态“Closing”中的进入动作以反方向开启电机关门。状态“Opened”和“Closed”不进行任何动作。它们信号通知外部世界(比如其他状态机)情况:“门开着”或“门关着”。
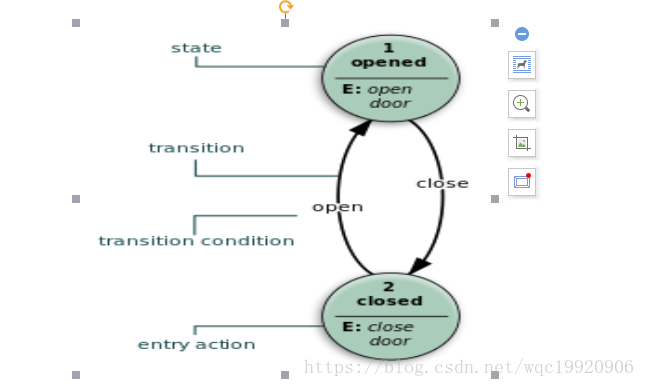
图1
米莉(Mealy)型状态机,就是说输出依赖于输入和状态。Mealy FSM的使用经常导致状态数目的简约。在图2中的例子展示了实现同上面Moore机同样行为的Mealy FSM(行为依赖于实现的FSM执行模型,比如对虚拟FSM可工作但对事件驱动FSM不行)。有两个输入动作(I:):“开启电机关门如果command_close下达”和“反向开启电机开门如果command_open下达”。
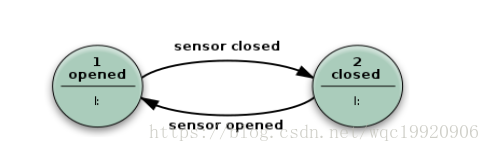
图 2
在实践中经常使用混合模型。进一步可区分为确定型(DFA)和非确定型(NDFA、GNFA)自动机。在确定型自动机中,每个状态对每个可能输入只有精确的一个转移。在非确定型自动机中,给定状态对给定可能输入可以没有或有多于一个转移。这个区分在实践而非理论中更有用,因为存在算法把任何NDFA转换成等价的DFA,尽管这种转换一般会增加自动机的复杂性。
2.2 确定有限状态机
对于一个给定的属于该自动机的状态和一个属于该自动机字母表的字符,他能根据事先给定的转移函数转移到下一个状态。
能被确定有限状态机识别的语言是正则语言。
确定有限状态机是非确定有限状态机的一种极限形式。
确定有限状态机在计算能力上等价于非确定有限状态机。
2.3 非确定有限状态机
对每个状态和输入符号对可以有多个可能的下一个状态的有限状态机。这区别于确定有限状态机(DFA),他的下一个可能状态是唯一确定的。
非确定有限状态机可以转化为确定有限状态机。
非确定有限状态机接受正则语言。
2.4 状态机详述
2.4.1 状态机特征
l 状态(State)总数是有限的。
l 在任一时刻,只处于一种状态。
l 在某种条件(Event)下,会从某种状态转移(Transition)到另一种状态,同时执行某个动作(Action)。
2.4.2 状态机的要素
状态机可归纳为4个要素,即现态、条件、动作、次态。“现态”和“条件”是因,“动作”和“次态”是果。详解如下:
①现态:是指当前所处的状态。
②条件:又称为“事件”。当一个条件被满足,将会触发一个动作,或者执行一次状态的迁移。
③动作:条件满足后执行的动作。动作执行完毕后,可以迁移到新的状态,也可以仍旧保持原状态。动作不是必需的,当条件满足后,也可以不执行任何动作,直接迁移到新状态。
④次态:条件满足后要迁往的新状态。“次态”是相对于“现态”而言的,“次态”一旦被激活,就转变成新的“现态”了。
2.4.3 状态机的表述
状态机有好多种展现方式,下面以状态表进行表述,讲一下状态变化。
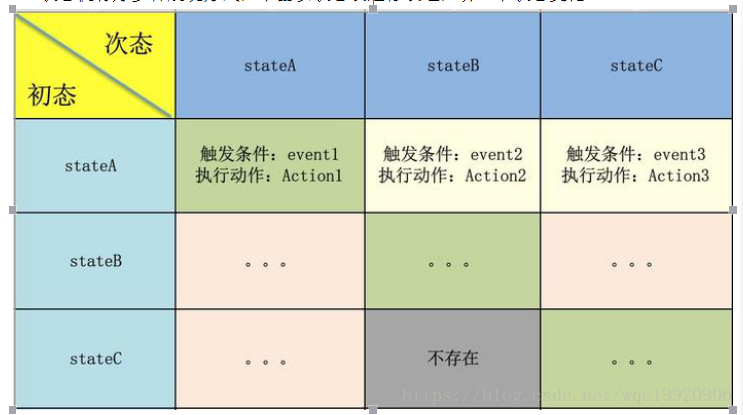
这里需要注意的两个问题:
1、避免把某个“程序动作”当作是一种“状态”来处理。那么如何区分“动作”和“状态”?“动作”是不稳定的,即使没有条件的触发,“动作”一旦执行完毕就结束了;而“状态”是相对稳定的,如果没有外部条件的触发,一个状态会一直持续下去。
2、状态划分时漏掉一些状态,导致跳转逻辑不完整。
所以维护上述一张状态表就非常必要,而且有意义了。从表中可以直观看出那些状态直接存在跳转路径,那些状态直接不存在。如果不存在,就把对应的单元格置灰。 每次写代码之前先把表格填写好,并且对置灰的部分重点review,看看是否有“漏态”,然后才是写代码。QA拿到这张表格之后,写测试用例也是手到擒来。
2.4.4 状态机的样例
以下是一个CD机的简单例子:
CD机状态转移表: | |||
状态 → | 播放 | 暂停 | 停止 |
按播放键 | … | 播放 | 播放 |
按停止键 | 停止 | 停止 | … |
按暂停键 | 暂停 | … | … |
通过这个表,我们可以很直观的来理解状态机,如下:
1、简单的CD机一般有三种状态: 播放、暂停、停止
2、我们对CD机的操作,就是事件,简单来说有三种事件:按播放、停止、暂停按键。
3、在CD机不同的状态下,发生不同的事件(按不同的按钮),触发的事情以及CD机下一步的状态(即状态转移)是不一样的。
4、 按照以上表格,假如CD机当前状态是“播放”,这时候,我们按播放键,它会保持“播放”状态,不会发生状态转移,如果按暂停键,则会触发状态转移,CD机状态转移为“暂停”状态。同理,按停止键会转移为停止状态
2.4.5 代码展示
include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef enum
{
STOP = 0,
RUNNING,
PAUSE,
MAX_STATE,
} CD_STATE;
typedef enum
{
PRESS_RUNNING = 0,
PRESS_PAUSE,
PRESS_STOP,
MAX_EVENT,
} CD_EVENT;
char state_to_str[3][100] = {"STOP", "RUNNING", "PAUSE"};
struct CD_STATE_MECHINE
{
int state;
int event;
void (*func)(unsigned char *);
};
void do_change_running(unsigned char * user_data);
void do_change_stop(unsigned char * user_data);
void do_change_pause(unsigned char * user_data);
struct CD_STATE_MECHINE state_mechine[] = {
{RUNNING, PRESS_RUNNING, NULL},
{RUNNING, PRESS_STOP, do_change_stop},
{RUNNING, PRESS_PAUSE, do_change_pause},
{PAUSE, PRESS_RUNNING, do_change_running},
{PAUSE, PRESS_STOP, do_change_stop},
{PAUSE, PRESS_PAUSE, NULL},
{STOP, PRESS_RUNNING, do_change_running},
{STOP, PRESS_STOP, NULL},
{STOP, PRESS_PAUSE, do_change_pause},
{-1, -1, NULL},
};
//全局变量,用来存储CD当前状态
int current_state = STOP;
void do_change_running(unsigned char * user_data)
{
printf("CD Status from %s to RUNING\n", state_to_str[current_state]);
current_state = RUNNING;
}
void do_change_stop(unsigned char * user_data)
{
printf("CD Status from '%s' to STOP\n", state_to_str[current_state]);
current_state = STOP;
}
void do_change_pause(unsigned char * user_data)
{
printf("CD Status from '%s' to pause\n", state_to_str[current_state]);
current_state = PAUSE;
}
int dispather(current_state, event)
{
int i = 0;
for(i = 0; state_mechine[i].state != -1; i++)
{
if (current_state == state_mechine[i].state && event == state_mechine[i].event)
{
void (*func)(unsigned char *);
func = state_mechine[i].func;
if (func != NULL)
{
func(NULL);
}
else
{
printf("state not change!\n");
}
break;
}
}
}
int main ()
{
char ch = '0';
printf ("请输入数字操作CD机(0:RUNNING, 1:PAUSE, 2:STOP):\n");
while (1)
{
ch = getchar();
if (ch == '\n')
{
}
else if ((ch < '0') || (ch > '3'))
{
printf ("非法输入,请重新输入!\n");
continue;
}
else
{
int event = ch - '0';
dispather(current_state, event);
printf ("请输入数字操作CD机(0:RUNNING, 1:PAUSE, 2:STOP):\n");
}
}
return 0;
}
2.5 TCP 有限状态机
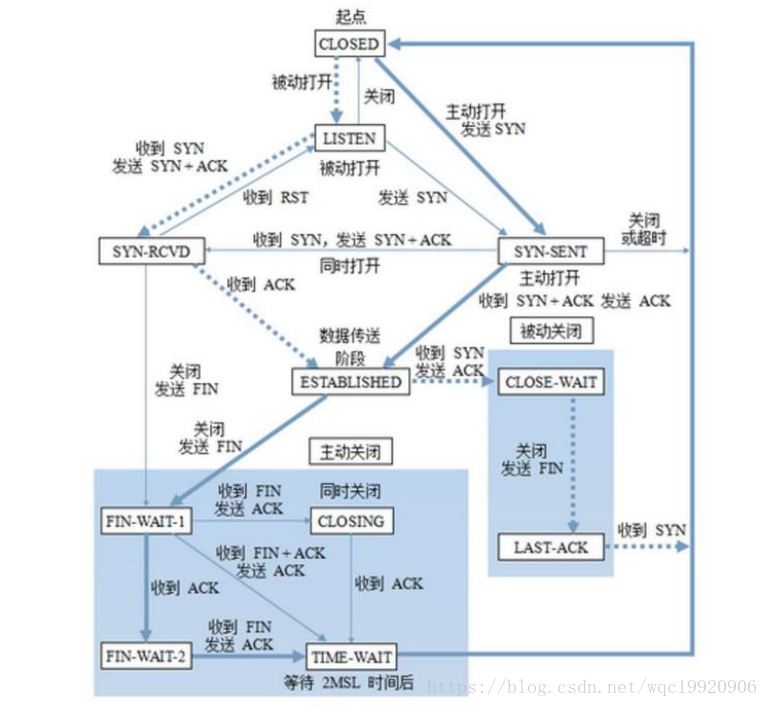
3. 定时器
定时器,又称Timer,顾名思义,它是用来在指定的时刻完成特定任务的一种工具的抽象。计算机为什么需要定时器,1、计算机系统本身需要一个时间基准,以保证计算机在确定时刻完成规定动作。2、用计算机构成的测控系统常被要求能提供一些定时和计数的功能
3.1 作用
在程序中,定时器常被用来完成两类任务,一种是周期性的任务,就是每隔指定的时间执行一次的任务,另一种是在特定时刻要执行的任务,就是只在某一个特定的时刻执行,而且只执行一次的任务。举个生活中的例子,闹钟,相信大家都不陌生,比如我们定了每天早上八点起床的闹钟,然后它就会在每天八点这个特定的时刻执行响铃这个任务,来叫我们起床,这就是上面讲到的第一种类型的定时器任务。再一个例子,就是日历(用过谷歌日历的读者朋友应该知道),我们在谷歌日历中制定一段时间的行程安排,它在每天那个特定的时刻就会提醒我们做这一时刻该做的事,这就是上面讲的第二种类型的定时器任务。
3.2 实现作用
通常,在程序中,一个定时器都是一个独立的线程,这个线程专门来处理定时器事件。需要注意两点,一是在定时器中,最好不要执行可阻塞的事件,如果定时器被阻塞了,后面的事件就不能被按时处理了。二是在定时器中,最好不要执行太抢占CPU的事件,如果定时器很抢CPU,就会导致应用程序性能下降。总结一下,定时器有以下几个要素:
1)、独立的线程,与应用程序互不影响
2)、任务不阻塞,否则会导致后续定时器任务不能按时处理
3)、任务不能太抢CPU,否则会降低应用程序性能
适用场景:
1)、定时任务(5分钟后执行xx任务/每隔1天执行一次)
2)、超时控制(xx分钟没有动作就断开连接)
3)、频率限制(最快只能每5s调用一次API/ 对同一个站点下页面的抓取最低要间隔5s)
3.3 定时器原理
3.3.1 Timer是什么
一个Timer本质上是这样的一个数据结构:deadline越近的任务拥有越高优先级,提供以下3种基本操作:
1)、schedule 新增
2)、cancel 删除
3)、expire 执行到期的任务
4)、updateDeadline 更新到期时间 (可选)
expire通常有两种工作方式:
1)、轮询
每隔一个时间片就去查找哪些任务已经到期;
2)、睡眠/唤醒
不停地查找deadline最近的任务,如到期则执行;否则sleep直到其到期。
在sleep期间,如果有任务被cancel或schedule,则deadline最近的任务有可能改变,线程会被唤醒并重新进行1的逻辑。
3.3.2 数据结构的选择
具体实现的数据结构可以有很多选择:
Ø 有序链表
schedule: O(n)
cancel: O(1) // 双向链表的节点删除
expire: O(1) // 不停地查看第一个就可以了
Ø 堆
Timer由于按deadline排列任务的性质,用堆来实现最直观不过了。
schedule: O(log2N) // 调整heap
cancel : O(log2N) // 调整heap
expire: O(1)
JDK中的DelayQueue用的就是这种实现方式,它在内部用一个PriorityQueue保存所有的Delayed对象,Delayed接口中只有一个方法long getDelay(TimeUnit unit);,返回该任务的deadline距离当前时间还有多久,堆顶保存了最快到期的任务。
DelayQueue#take()方法如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
// 找最快到期的
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
// 到期了,返回该任务
if (delay <= 0)
return q.poll();
else if (leader != null)
available.await();
else {
// 让当前线程sleep,时间为first的延迟时间
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
// 其他线程插入新任务/取消任务会引起堆的调整,并中断take()线程,
// 醒来后进入下一次判断。这就是整个逻辑为什么要在一个循环内的原因。
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
Ø Hash Wheel Timer
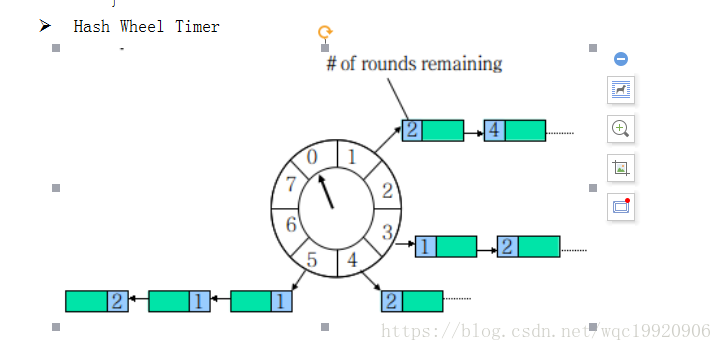
一个Hash Wheel Timer是一个环形结构,可以想象成时钟,分为很多格子,一个格子代表一段时间(越短Timer精度越高),并用一个List保存在该格子上到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应List中所有到期的任务。任务通过取模决定应该放入哪个格子。
以上图为例,假设一个格子是1秒,则整个wheel能表示的时间段为8s,假如当前指针指向2,此时需要调度一个3s后执行的任务,显然应该加入到(2+3=5)的方格中,指针再走3次就可以执行了;如果任务要在10s后执行,应该等指针走完一个round零2格再执行,因此应放入4,同时将round(1)保存到任务中。检查到期任务时应当只执行round为0的,格子上其他任务的round应减1。
schedule: O(1)
cancel : O(1)
expire : 最坏情况O(n),平均O(1) // 显然格子越多每个格子对应的List就越短,越接近O(1);最坏情况下所有的任务都在一个格子中,O(n)。Netty3中的HashedWheelTimer类是对该算法的一个实现,用于IO事件的超时管理。里面提到了两个概念:
1、Tick Duration:即一个格子代表的时间,默认为100ms,因为IO事件不需要那么精确;
2、Ticks per Wheel (Wheel Size):一个Wheel含有多少个格子,默认为512个,如果任务较多可以增大这个参数。
3.4 Java定时器的使用
3.4.1 定时器简介
Timer是一种工具,线程用其安排以后在后台线程中执行的任务。可安排任务执行一次,或者定期重复执行。实际上是个线程,定时调度所拥有的TimerTasks。
TimerTask是一个抽象类,它的子类由 Timer 安排为一次执行或重复执行的任务。实际上就是一个拥有run方法的类,需要定时执行的代码放到run方法体内。
3.4.2 定时器调用
Timer timer = Timer(true);
// 注意,javax.swing包中也有一个Timer类,如果import中用到swing包,要注意名字的冲突。
TimerTask task = new TimerTask() {
public void run() {
... //每次需要执行的代码放到这里面。
}
};
//以下是几种常用调度task的方法:
timer.schedule(task, time);
// time为Date类型:在指定时间执行一次。
timer.schedule(task, firstTime, period);
// firstTime为Date类型,period为long
// 从firstTime时刻开始,每隔period毫秒执行一次。
timer.schedule(task, delay)
// delay 为long类型:从现在起过delay毫秒执行一次
timer.schedule(task, delay, period)
// delay为long,period为long:从现在起过delay毫秒以后,每隔period
// 毫秒执行一次。


schedule()与scheduleAtFixedRate()的区别?
首先schedule(TimerTask task,Date time)与schedule(TimerTask task,long delay)都只是单次执行操作,并不存在多次调用任务的情况,所以没有提供scheduleAtFixedRate方法的调用方式。它们实现的功能都一样,那区别在哪里呢?
1)、schedule()方法更注重保持间隔时间的稳定:保障每隔period时间可调用一次。
2)、scheduleAtFixedRate()方法更注重保持执行频率的稳定:保障多次调用的频率趋近于period时间,如果某一次调用时间大于period,下一次就会尽量小于period,以保障频率接近于period。
3.4.3 定时器例子
定制任务:
import java.util.Timer;
import java.util.TimerTask;
public class TimerTaskTest extends TimerTask{
@Override
public void run() {
// TODO Auto-generated method stub
System.out.println("执行任务……");
}
}
//调用java.util.Timer:
import java.util.Timer;
/**
* 安排指定的任务task在指定的时间firstTime开始进行重复的固定速率period执行
* 每天中午12点都执行一次
*/
public class Test {
public static void main(String[] args){
Timer timer = new Timer();
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.HOUR_OF_DAY, 12);//控制小时
calendar.set(Calendar.MINUTE, 0);//控制分钟
calendar.set(Calendar.SECOND, 0);//控制秒
Date time = calendar.getTime();//执行任务时间为12:00:00
Timer timer = new Timer();
//每天定时12:00执行操作,延迟一天后再执行
timer.schedule(new TimerTaskTest(), time, 1000 * 60 * 60 * 24);
}
}
3.5 TCP的四种定时器
CP使用四种定时器(Timer,也称为“计时器”):
重传计时器:Retransmission Timer
坚持计时器:Persistent Timer
保活计时器:Keeplive Timer
时间等待计时器:Time_Wait Timer
1)、重传计时器:
重传定时器:为了控制丢失的报文段或丢弃的报文段,也就是对报文段确认的等待时间。当TCP发送报文段时,就创建这个特定报文段的重传计时器,可能发生两种情况:若在计时器超时之前收到对报文段的确认,则撤销计时器;若在收到对特定报文段的确认之前计时器超时,则重传该报文,并把计时器复位;
重传时间=2*RTT;
RTT的值应该动态计算。常用的公式是:RTT=previous RTT*i + (1-i)*current RTT。i的值通常取90%,即新的RTT是以前的RTT值的90%加上当前RTT值的10%.
Karn算法:对重传报文,在计算新的RTT时,不考虑重传报文的RTT。因为无法推理出:发送端所收到的确认是对上一次报文段的确认还是对重传报文段的确认。干脆不计入。
2)、坚持计时器:persistent timer
专门为对付零窗口通知而设立的。
当发送端收到零窗口的确认时,就启动坚持计时器,当坚持计时器截止期到时,发送端TCP就发送一个特殊的报文段,叫探测报文段,这个报文段只有一个字节的数据。探测报文段有序号,但序号永远不需要确认,甚至在计算对其他部分数据的确认时这个序号也被忽略。探测报文段提醒接收端TCP,确认已丢失,必须重传。
坚持计时器的截止期设置为重传时间的值,但若没有收到从接收端来的响应,则发送另一个探测报文段,并将坚持计时器的值加倍和并复位,发送端继续发送探测报文段,将坚持计时器的值加倍和复位,知道这个值增大到阈值为止(通常为60秒)。之后,发送端每隔60s就发送一个报文段,直到窗口重新打开为止;
3)、保活计时器:keeplive timer
每当服务器收到客户的信息,就将keeplive timer复位,超时通常设置2小时,若服务器超过2小时还没有收到来自客户的信息,就发送探测报文段,若发送了10个探测报文段(没75秒发送一个)还没收到响应,则终止连接。
4)、时间等待计时器:Time_Wait Timer
在连接终止期使用,当TCP关闭连接时,并不认为这个连接就真正关闭了,在时间等待期间,连接还处于一种中间过度状态。这样就可以时重复的fin报文段在到达终点后被丢弃,这个计时器的值通常设置为一格报文段寿命期望值的两倍。
3.6 Linux内核定时器使用及原理
3.6.1 内核定时器使用
内核定时器是内核用来控制在未来某个时间点(基于jiffies)调度执行某个函数的一种机制,其实现位于 <linux/timer.h> 和 kernel/timer.c 文件中。
被调度的函数肯定是异步执行的,它类似于一种“软件中断”,而且是处于非进程的上下文中,所以调度函数必须遵守以下规则:
1)、没有 current 指针、不允许访问用户空间。因为没有进程上下文,相关代码和被中断的进程没有任何联系。
2)、不能执行休眠(或可能引起休眠的函数)和调度。
3)、任何被访问的数据结构都应该针对并发访问进行保护,以防止竞争条件。
内核定时器的调度函数运行过一次后就不会再被运行了(相当于自动注销),但可以通过在被调度的函数中重新调度自己来周期运行。
在SMP系统中,调度函数总是在注册它的同一CPU上运行,以尽可能获得缓存的局域性。
内核定时器的数据结构
struct timer_list {
struct list_head entry;
unsigned long expires;
void (*function)(unsigned long);
unsigned long data;
struct tvec_base *base;
/* ... */
};
其中 expires 字段表示期望定时器执行的 jiffies 值,到达该 jiffies 值时,将调用 function 函数,并传递 data 作为参数。当一个定时器被注册到内核之后,entry 字段用来连接该定时器到一个内核链表中。base 字段是内核内部实现所用的。
需要注意的是 expires 的值是32位的,因为内核定时器并不适用于长的未来时间点。
Ø 初始化
在使用 struct timer_list 之前,需要初始化该数据结构,确保所有的字段都被正确地设置。初始化有两种方法。
方法一:
DEFINE_TIMER(timer_name, function_name, expires_value, data);
该宏会定义一个名叫 timer_name 内核定时器,并初始化其 function, expires, name 和 base 字段。
方法二:
struct timer_list mytimer;
setup_timer(&mytimer, (*function)(unsigned long), unsigned long data);
mytimer.expires = jiffies + 5*HZ;
注意,无论用哪种方法初始化,其本质都只是给字段赋值,所以只要在运行 add_timer() 之前,expires, function 和 data 字段都可以直接再修改。
关于上面这些宏和函数的定义,参见 include/linux/timer.h。
Ø 注册
定时器要生效,还必须被连接到内核专门的链表中,这可以通过 add_timer(struct timer_list *timer) 来实现。
Ø 重新注册
要修改一个定时器的调度时间,可以通过调用 mod_timer(struct timer_list *timer, unsigned long expires)。mod_timer() 会重新注册定时器到内核,而不管定时器函数是否被运行过。
Ø 注销
注销一个定时器:del_timer(struct timer_list *timer) 或 del_timer_sync(struct timer_list *timer)。其中 del_timer_sync 是用在 SMP 系统上的(在非SMP系统上,它等于del_timer),当要被注销的定时器函数正在另一个 cpu 上运行时,del_timer_sync() 会等待其运行完, 所以这个函数会休眠。另外还应避免它和被调度的函数争用同一个锁。对于一个已经被运行过且没有重新注册自己的定时器而言,注销函数其实也没什么事可做。
int timer_pending(const struct timer_list *timer)
这个函数用来判断一个定时器是否被添加到了内核链表中以等待被调度运行。注意,当一个定时器函数即将要被运行前,内核会把相应的定时器从内核链表中删除(相当于注销)
3.6.2 内核动态定时器机制的实现
在内核动态定时器机制的实现中,有三个操作是非常重要的:
1)、将一个定时器插入到它应该所处的定时器向量中。
2)、定时器的迁移,也即将一个定时器从它原来所处的定时器向量迁移到另一个定时器向量中。
3)、扫描并执行当前已经到期的定时器。
代码位置:kernel/kernel/timer.c
4. 消息通讯机制
4.1 通讯原理
通信一般分为并行通信和串行通信,并行通信传输中有多个数据位,同时在两个设备之间传输。发送设备将这些数据位通过 对应的数据线传送给接收设备,还可附加一位数据校验位。接收设备可同时接收到这些数据,不需要做任何变换就可直接使用。并行方式主要用于近距离通信。计算 机内的总线结构就是并行通信的例子。这种方法的优点是传输速度快,处理简单。
串行数据传输时,数据是一位一位地在通信线上传输的,先由具有几位总线的计算机内的发送设备,将几位并行数据经并--串转换硬件转换成串行方式,再逐位经 传输线到达接收站的设备中,并在接收端将数据从串行方式重新转换成并行方式,以供接收方使用。串行数据传输的速度要比并行传输慢得多,但对于覆盖面极其广 阔的公用电话系统来说具有更大的现实意义。
4.2 串行通讯
串行通信是指计算机主机与外设之间以及主机系统与主机系统之间数据的串行传送。使用串口通信时,发送和接收到的每一个字符实际上都是一次一位的传送的,每一位为1或者为0。
串行通信可以分为同步通信和异步通信两类。同步通信是按照软件识别同步字符来实现数据的发送和接收,异步通信是一种利用字符的再同步技术的通信方式。串行通讯的特点是:数据位传送,传按位顺序进行,最少只需一根传输线即可完成;成本低但传送速度慢。串行通讯的距离可以从几米到几千米;根据信息的传送方向,串行通讯可以进一步分为单工、半双工和全双工三种。
同步通信是一种连续串行传送数据的通信方式,一次通信只传送一帧信息。这里的信息帧与异步通信中的字符帧不同,通常含有若干个数据字符。它们均由同步字符、数据字符和校验字符(CRC)组成。其中同步字符位于帧开头,用于确认数据字符的开始。数据字符在同步字符之后,个数没有限制,由所需传输的数据块长度来决定;校验字符有1到2个,用于接收端对接收到的字符序列进行正确性的校验。同步通信的缺点是要求发送时钟和接收时钟保持严格的同步。
异步通信中,在异步通行中有两个比较重要的指标:字符帧格式和波特率。数据通常以字符或者字节为单位组成字符帧传送。字符帧由发送端逐帧发送,通过传输线被接收设备逐帧接收。发送端和接收端可以由各自的时钟来控制数据的发送和接收,这两个时钟源彼此独立,互不同步。接收端检测到传输线上发送过来的低电平逻辑指示。由于发送和接收的双方采用同一时钟,所以在传送数据的同时还要传送时钟信号,以便接收方可以用时钟信号来确定每个信息位。
同步通信要求在传输线路上始终保持连续的字符位流,若计算机没有数据传输,则线路上要用专用的“空闲”字符或同步字符填充。同步通信传送信息的位数几乎不受限制,通常一次通信传的数据有几十到几千个字节,通信效率较高。但它要求在通信中保持精确的同步时钟,所以其发送器和接收器比较复杂,成本也较高,一般用于传送速率要求较高的场合。
用于同步通信的数据格式有许多种,
a)、单同步格式,会送一帧数据仅使用一个同步字符。当接收端收到并识别出一个完整同步字符后,就连续接收数据。一帧数据结束,进行CRC校验。同步字符 数据 CRC1 CRC2
b)、双同步字格式,这时利用两个同步字符进行同步。同步字符1 同步字符2 数据 CRC1 CRC2
c)、同步数据链路控制(SDC)规程所规定的数据格式。标志符01111110 地址符8位 数据 CRC1 CRC2 标志符01111110
d)、是一种外同步方式所采用的数据格式。对这种方式,在发送的一帧数据中不包含同步字符。同步信号SYNC通过专门的控制线加到串行的接口上。当SYNC一到达,表明数据部分开始,接口就连续接收数据和CRC校验码。数据场 CRC1 CRC2
e)、高级数据链路控制(HDLC)规程所规定的数据格式。它们均用于同步通信。这两种规程的细节本书不做详细说明。标志符01111110 地址符8位 控制符8位 数据 CRC1 CRC2 标志符01111110
CRC(cyclic redundancy checks)的意思是循环冗余校验码。它用于检验在传输过程中是否出现错误,是保证传输可靠性的重要手段之一。
异步通信是指通信中两个字符之间的时间间隔是不固定的,而在一个字符内各位的时间间隔是固定的。异步通信规定字符由起始位(start bit)、数据位(data bit)、奇偶校验位(parity)和停止位(stop bit)组成。起始位表示一个字符的开始,接收方可用起始位使自己的接收时钟与数据同步。停止位则表示一个字符的结束。这种用起始位开始,停止位结束所构成的一串信息称为帧(frame)(注意:异步通信中的“帧”与同步通信中“帧”是不同的,异步通信中的“帧”只包含一个字符,而同步通信中“帧”可包含几十个到上千个字符)。在传送一个字符时,由一位低电平的起始位开始,接着传送数据位,数据位的位数为5~8。在传输时,按低位在前,高位在后的顺序传送。奇偶校验位用于检验数据传送的正确性,也可以没有,可由程序来指定。最后传送的是高电平的停止位,停止位可以是1位、1.5位或2位。停止位结束到下一个字符的起始位之间的空闲位要由高电平2来填充(只要不发送下一个字符,线路上就始终为空闲位)。 通信中典型的帧格式是:1位起始位,7位(或8位)数据位,1位奇偶校验位,2位停止位。 起始位 数据位(低位…高位) 奇偶校验位 停止位 空闲位 起始位
从以上叙述可以看出,在异步通信中,每接收一个字符,接收方都要重新与发送主同步一次,所以接收端的同步时钟信号并不需要严格地与发送方同步,只要它们在一个字符的传输时间范围内能保持同步即可,这意味着南时钟信号漂移的要求要比同步信号低得多,硬件成本也要低的多,但是异步传送一个字符,要增加大约20%的附加信息位,所以传送效率比较低。异步通信方式简单可靠,也容易实现,故广泛地应用于各种微型机系统中 。
4.3 通信协议
4.3.1 Tcp
我们需要知道TCP在网络OSI的七层模型中的第四层——Transport层,IP在第三层——Network层,ARP在第二层——Data Link层,在第二层上的数据,我们叫Frame,在第三层上的数据叫Packet,第四层的数据叫Segment。
首先,我们需要知道,我们程序的数据首先会打到TCP的Segment中,然后TCP的Segment会打到IP的Packet中,然后再打到以太网Ethernet的Frame中,传到对端后,各个层解析自己的协议,然后把数据交给更高层的协议处理。
TCP协议头的格式:
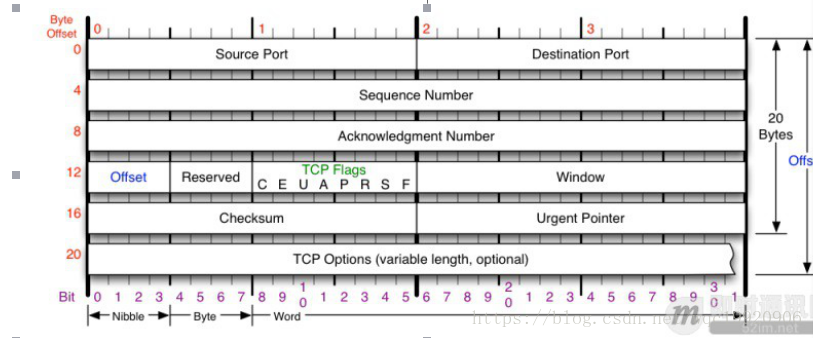
TCP的包是没有IP地址的,那是IP层上的事,但是有源端口和目标端口。
一个TCP连接需要四个元组来表示是同一个连接(src_ip, src_port, dst_ip, dst_port)准确说是五元组,还有一个是协议。但因为这里只是说TCP协议,所以,这里只说四元组。
Sequence Number:是包的序号,用来解决网络包乱序(reordering)问题。
Acknowledgement Number:就是ACK——用于确认收到,用来解决不丢包的问题。
Window:又叫Advertised-Window,也就是著名的滑动窗口(Sliding Window),用于解决流控的。
TCP Flag :也就是包的类型,主要是用于操控TCP的状态机的。
l TCP的状态机
其实,网络上的传输是没有连接的,包括TCP也是一样的。而TCP所谓的“连接”,其实只不过是在通讯的双方维护一个“连接状态”,让它看上去好像有连接一样。所以,TCP的状态变换是非常重要的。
下面是:“TCP协议的状态机”(图片来源) 和 “TCP建链接”、“TCP断链接”、“传数据” 的对照图,我把两个图并排放在一起,这样方便对照着看。另外,下面这两个图非常非常的重要,一定要记牢。
下图是双方同时断连接的示意图:
l TCP注意问题
1、关于建连接时SYN超时:
试想一下,如果server端接到了clien发的SYN后回了SYN-ACK后client掉线了,server端没有收到client回来的ACK,那么,这个连接处于一个中间状态,即没成功,也没失败。于是,server端如果在一定时间内没有收到的TCP会重发SYN-ACK。在Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,第5次发出后还要等32s都知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 2^6 -1 = 63s,TCP才会把断开这个连接。
2、关于SYN Flood攻击:
一些恶意的人就为此制造了SYN Flood攻击——给服务器发了一个SYN后,就下线了,于是服务器需要默认等63s才会断开连接,这样,攻击者就可以把服务器的syn连接的队列耗尽,让正常的连接请求不能处理。于是,Linux下给了一个叫tcp_syncookies的参数来应对这个事——当SYN队列满了后,TCP会通过源地址端口、目标地址端口和时间戳打造出一个特别的Sequence Number发回去(又叫cookie),如果是攻击者则不会有响应,如果是正常连接,则会把这个 SYN Cookie发回来,然后服务端可以通过cookie建连接(即使你不在SYN队列中)。请注意,请先千万别用tcp_syncookies来处理正常的大负载的连接的情况。因为,synccookies是妥协版的TCP协议,并不严谨。对于正常的请求,你应该调整三个TCP参数可供你选择,第一个是:tcp_synack_retries 可以用他来减少重试次数;第二个是:tcp_max_syn_backlog,可以增大SYN连接数;第三个是:tcp_abort_on_overflow 处理不过来干脆就直接拒绝连接了。
3、关于TIME_WAIT数量太多:
从上面的描述我们可以知道,TIME_WAIT是个很重要的状态,但是如果在大并发的短链接下,TIME_WAIT 就会太多,这也会消耗很多系统资源。只要搜一下,你就会发现,十有八九的处理方式都是教你设置两个参数,一个叫tcp_tw_reuse,另一个叫tcp_tw_recycle的参数,这两个参数默认值都是被关闭的,后者recyle比前者resue更为激进,resue要温柔一些。另外,如果使用tcp_tw_reuse,必需设置tcp_timestamps=1,否则无效。这里,你一定要注意,打开这两个参数会有比较大的坑——可能会让TCP连接出一些诡异的问题(因为如上述一样,如果不等待超时重用连接的话,新的连接可能会建不上。正如官方文档上说的一样“It should not be changed without advice/request of technical experts”)。
4、关于tcp_tw_reuse:
官方文档上说tcp_tw_reuse 加上tcp_timestamps(又叫PAWS, for Protection Against Wrapped Sequence Numbers)可以保证协议的角度上的安全,但是你需要tcp_timestamps在两边都被打开(你可以读一下tcp_twsk_unique的源码 )。我个人估计还是有一些场景会有问题。
5、关于tcp_tw_recycle:
如果是tcp_tw_recycle被打开了话,会假设对端开启了tcp_timestamps,然后会去比较时间戳,如果时间戳变大了,就可以重用。但是,如果对端是一个NAT网络的话(如:一个公司只用一个IP出公网)或是对端的IP被另一台重用了,这个事就复杂了。建链接的SYN可能就被直接丢掉了(你可能会看到connection time out的错误)(如果你想观摩一下Linux的内核代码,请参看源码 tcp_timewait_state_process)。
6、关于tcp_max_tw_buckets:
这个是控制并发的TIME_WAIT的数量,默认值是180000,如果超限,那么,系统会把多的给destory掉,然后在日志里打一个警告(如:time wait bucket table overflow),官网文档说这个参数是用来对抗DDoS攻击的。也说的默认值180000并不小。这个还是需要根据实际情况考虑。
l 数据传输中的Sequence Number
下图是我从Wireshark中截了个我在访问coolshell.cn时的有数据传输的图给你看一下,SeqNum是怎么变的。(使用Wireshark菜单中的Statistics ->Flow Graph… )
SeqNum的增加是和传输的字节数相关的。上图中,三次握手后,来了两个Len:1440的包,而第二个包的SeqNum就成了1441。然后第一个ACK回的是1441,表示第一个1440收到了。
l TCP重传机制
TCP要保证所有的数据包都可以到达,所以,必需要有重传机制。
1、超时重传机制
一种是不回ack,死等3,当发送方发现收不到3的ack超时后,会重传3。一旦接收方收到3后,会ack 回 4——意味着3和4都收到了。
但是,这种方式会有比较严重的问题,那就是因为要死等3,所以会导致4和5即便已经收到了,而发送方也完全不知道发生了什么事,因为没有收到Ack,所以,发送方可能会悲观地认为也丢了,所以有可能也会导致4和5的重传。
2、快速重传机制
TCP引入了一种叫Fast Retransmit 的算法,不以时间驱动,而以数据驱动重传。也就是说,如果,包没有连续到达,就ack最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。Fast Retransmit的好处是不用等timeout了再重传。比如:如果发送方发出了1,2,3,4,5份数据,第一份先到送了,于是就ack回2,结果2因为某些原因没收到,3到达了,于是还是ack回2,后面的4和5都到了,但是还是ack回2,因为2还是没有收到,于是发送端收到了三个ack=2的确认,知道了2还没有到,于是就马上重转2。然后,接收端收到了2,此时因为3,4,5都收到了,于是ack回6。示意图如下:
Fast Retransmit只解决了一个问题,就是timeout的问题,它依然面临一个艰难的选择,就是,是重传之前的一个还是重传所有的问题。对于上面的示例来说,是重传#2呢还是重传#2,#3,#4,#5呢?因为发送端并不清楚这连续的3个ack(2)是谁传回来的?也许发送端发了20份数据,是#6,#10,#20传来的呢。这样,发送端很有可能要重传从2到20的这堆数据(这就是某些TCP的实际的实现)。可见,这是一把双刃剑。
3、SACK 方法
另外一种更好的方式叫:Selective Acknowledgment (SACK)(参看RFC 2018),这种方式需要在TCP头里加一个SACK的东西,ACK还是Fast Retransmit的ACK,SACK则是汇报收到的数据碎版。参看下图:
这样,在发送端就可以根据回传的SACK来知道哪些数据到了,哪些没有到。于是就优化了Fast Retransmit的算法。当然,这个协议需要两边都支持。在 Linux下,可以通过tcp_sack参数打开这个功能(Linux 2.4后默认打开)。
这里还需要注意一个问题——接收方Reneging,所谓Reneging的意思就是接收方有权把已经报给发送端SACK里的数据给丢了。这样干是不被鼓励的,因为这个事会把问题复杂化了,但是,接收方这么做可能会有些极端情况,比如要把内存给别的更重要的东西。所以,发送方也不能完全依赖SACK,还是要依赖ACK,并维护Time-Out,如果后续的ACK没有增长,那么还是要把SACK的东西重传,另外,接收端这边永远不能把SACK的包标记为Ack。
4.3.2 http
l 使用http协议访问web
当我们用网页浏览器(web browser)的地址栏中输入URL时,Web页面的呈现过程:
输入URL时,可以看到web页面,即使不了解运作原理,也能看到页面。
输入URL后,信息会被送往某处。
然后从某处获得的回复,内容就会显示在web页面上。
web页面不可能凭空显示出来,根据web浏览器地址栏中指定的URL,web浏览器会从服务器端获取文件资源等信息,从而显示web页面。
像这一套流程就可以称作是客户端(client)向服务端(server)获取服务器资源
web使用一种名为HTTP(HyperText Transfer Protocol),超文本传输协议作为规范,完成从客户端到服务端等一系列运作过程。而协议是指规则的约定。可以理解成,web是建立在HTTP协议上通信的。
l 网络基础TCP/IP
为了了解HTTP,必须的了解TCP/IP协议族。
通常使用的网络实在TCP/IP协议族的基础上运作的。而HTTP就属于他的一个子集。
1)、TCP/IP 协议族
计算机与网络设备要相互通信,双方就必须基于相同的方法。比如:如何探测到通信目标、由哪一方先发起通信、使用哪种语言等等好多规则。然而这种规则就是所谓的协议(protocol),你要用我就按照我协议的规则来。常用协议有:tcp,http,ftp,dhcp,dns,ip,pppoe,udp,snmp,icmp等等。
像这样把与互联网关联的协议集合起来总称TCP/IP,TCP/IP实在IP协议通信过程中,使用到的协议族的统称
2)、TCP/ip的分层管理
TCP/IP协议族重要的一点就是分层。TCP/IP协议族按层次划分分别是:应用层、传输层、网络层和数据链路层。把塔层次化是有好处的。比如:当某个地方需求变更时,就必须把所有的整体替换掉。而分层之后只需要把变动的层替换掉即可。下面介绍一下每个层次的作用
应用层
应用层决定了向用户提供应用服务时通信的活动。比如:ftp,dns服务就是其中的两类。HTTP协议也处于该层。
传输层
传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。在传输层有两个性质不同的协议:TCP和UDP。
网络层
网络层用来处理网络上流动的数据包。数据包是网络传输的最小单位。该层规定了通过怎样的路径到达对方计算机,并把数据包发送给对方。
链路层
用来处理链接网络的硬件部分。包括操作系统、硬件的设备驱动、网卡及光纤等物理可见部分。
3)、TCP/IP 传输流
如说我想看百度网页:流程如下:
i. 客户端在应用层发出一个想看某个WEB页面的HTTP请求的时候;
ii. 接着为了传输方便,在传输层把应用层收到的数据进行分割,并在各个报文上打上标记序号及端口号后转发给网络层;
iii. 在网络层增加作为通信目的的MAC地址后转发给链路层,这样一来发送网络的通信请求就准备齐全了;
iv. 接收端的服务器在链路层接收到数据,按序往上层发送,一直到应用层;
v. 当传输到应用层,才能算真正接收到由客户端发送过来的HTTP请求了。
发送端在层与层之间传输数据时,每经过一层时必定会打上一个该层的首部信息。接收端经过一层,会把消去。这种数据信心包装叫做封装。
TCP/IP传输是三次握手,四次断开。
l URI和URL
用字符串标示某一互联网资源,而URL表示资源的地点。可见URL是URI的子集。
URI要使用涵盖全部必要信息的URI、绝对URL以及相对URL。相对URL是指从浏览器中基本URI处理的URL,来先看下URI的格式
l 简单的HTTP协议
1、通信过程
HTTP协议规定,请求从客户端发出,最后服务器端相应该请求并返回。换个意思就是客户端建立通信的,服务器端在没有接收到请求之前不会发送响应。来一个示例:
下面的内容是客户端想服务端发的求求内容
GET / HTTP/1.1
HOST: HACKR.JP
起始行的get表示请求访问服务器的类型,成为方法。随后的字符串指明了请求访问的资源对象,也叫请求URL,后面是版本号,用来提示客户端使用的HTTP协议功能
总结:请求报文是由请求方法、请求URL、协议版本、可选的气你去头和内容实体构成的。
接下来服务器端接收到请求,会将请求内容的处理结果以相应的形式返回。
HTTP /1.1 200 OK
Date:Tue,10 JUL 2016 10:50:20 GMT
Content-length:398
Content-Type:text/html
用图片详细讲解一下:
2、HTTP是不保存状态的协议
HTTP是一种不报错状态,即无状态协议。http协议自身不对请求和相应之间的通信状态进行保存,也就是说在HTTP这个级别,协议对于发送过得请求和响应不做持久化处理。
使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产生。协议本事并不保留之前的请求或响应报文的信息。这是为了处理大量事务,确保协议的课伸缩性,而特意吧HTTP协议设计成如此简单的。但是也存在弊端,当业务处理变得棘手的情况多了,比如用户登录一家网站,即使他跳转到别的页面后,也需要保持登录状态,然而cookie就诞生了。有了cookie再用http协议通信,就可以管理状态了。
3、HTTP方法
1)、GET获取资源
get方法是用来请求访问已被URL识别的资源。指定的资源经服务端解析后返回响应内容。也就是说,请求的资源是文本,那就保持原样返回;如果像cgi那样的程序,则返回经过执行后的输出结果
使用get方法的请求响应的例子:
2)、POST传输实体主体
post方法用来传输实体的主体。虽然用get方法也可以传输实体的主体,但是一般不用get方法进行传输,而是用post方法。虽说post的功能与get很相似,但是post的主要目的并不是获取相应的主体内容。
使用post方法请求的例子:
3)、PUT传输文件
put方法用来传输文件,就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求url指定的位置。由于put的方法不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的web网站不适用该方法。
使用put方法请求的例子:
4)、head获取报文首部
head和get方法一样,只是不返回报文主体部分,用于确认url的有效性及资源更新的日期时间等。
使用head方法请求的例子:
5)、DELETE删除文件
delete方法用来删除文件,是与put相反的方法,delete方法按照请求url删除指定的资源。其本质和put方法一样不带验证机制,所以不适用delete方法。
使用delete方法请求的例子:
下面列举一些方法:其中link和unlink已被HTTP/1.1废弃 ,不在支持
4、持久化
当频繁访问web网页的时候,每次都要进行TCP/IP通信,tcp/ip通信三次握手四次断开,代价是很昂贵的,增加了通信量的开销,为解决上述TCP连接的问题,HTTP就诞生了持久连接的方法。特点是只要任意一端没有明确提出断开连接,则保持TCP连接状态。
持久化连接减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务端的负载。另外,减少开销的那部分时间,使HTTP请求和响应能够更早的结束,这样web页面的显示速度也就相应的提高了。
5、使用cookie的状态管理
cookie技术通过在请求和相应报文中写入cookie信息来控制客户端的状态。cookie会根据从服务端发送的相应报文内的一个叫做set-cookie的首部字段信息,通知客户端保存cookie。当下次客户端再往服务器发送请求的时候,客户端会自动在请求头加入cookie值后发送出去。下面带图分析下过程
没有cookie状态下的请求
第二次以后(存有cookie信息状态)的请求
4.3.3 即时通信协议
四种协议英文全称与简称
1、MPP(Instant Messaging And PresenceProtocol):即时信息和空间协议
2、PRIM(Presence and Instant Messaging Protocol):空间和即时信息协议
3、SIP(Session Initialion Protocol):回话发起协议,SIMPLE(SIP for Instant Messaging and Presence Leveraging Extensiong):,SIP即时消息和表示扩展协议,即SIP的扩展协议
4、XMPP(Extensible Messaging and Presence Protocol):可扩展消息与存在协议
Ø 即时信息和空间协议IMPP
IMPP主要定义必要的协议和数据格式,用来构建一个具有空间接收、发布能力的即时信息系统。到目前为止,这个组织已经出版了三个草案 RFC,但主要的有两个:一个是针对站点空间和即时通讯模型的(RFC 2778);另一个是针对即时通讯/空间协议需求条件的(RFC2779)。RFC2778是一个资料性质的草案,定义了所有presence和IM服务 的原理。RFC2779定义了IMPP的最小需求条件。另外,这个草案还就presence服务定义了一些条款,如运行的命令、信息的格式,以及 presence服务器如何把presence的状态变化通知给客户。
Ø 空间和即时信息协议PRIM
PRIM与XMPP、 SIMPLE类似,已经不再使用了。与之相关的资料也非常有限~
Ø 回话发起协议SIP
SIMPLE是SIP的扩展协议, SIMPLE是目前为止制定的较为完善的一个。SIMPLE和XMPP两个协议,都符合RFC2778和RFC2779 。SIMPLE计划利用SIP来发送presence信息。SIP是IETF中为终端制定的协议。SIP一般考虑用在建立语音通话中,一旦连接以后,依靠如实时协议(RTP)来进行实际上的语音发送。但SIP不仅仅能被用在语音中,也可以用于视频。SIMPLE被定义为建立一个IM进程的方法。SIMPLE在2002年夏季得到额外的信任,目前,微软和IBM都致力于在它们的即时通讯系统中实现这个协议。
Ø 可扩展消息与存在协议XMPP
都知道在这四种协议中,XMPP是最灵活的。XMPP是一种基于XML的协议,它继承了在XML环境中灵活的发展性。因此,基于XMPP的应用具有超强的可扩展性。经过扩展以后的XMPP可以通过发送扩展的信息来处理用户的需求,以及在XMPP的顶端建立如内容发布系统和基于地址的服务等应用程序。而且,XMPP包含了针对服务器端的软件协议,使之能与另一个进行通话,这使得开发者更容易建立客户应用程序或给一个配好系统添加功能。
XMPP由Jabber软件基金会开发,最早在Jabber上实现。Jabber项目由Jeremie Miller在1998年开始的一个免费、开源的项目,用于提供给MSN、Yahoo!的IM服务。由于XMPP是一种基于XML架构的开放式协议,在 IM通讯中被广泛采用,已经得到了互联网工程任务组(IETF )的批准。2002年,这个产品有超过5万的下载量。XMPP拥有成千的Jabber开发者,以及大约数万台配置的服务器和超过百万的终端用户。
XMPP的前身是Jabber,一个开源形式组织产生的网络即时通信协议。XMPP目前被IETF国际标准组织完成了标准化工作。标准化的核心结果分为两部分:
1、核心的XML流传输协议
2、基于XML流传输的即时通讯扩展应用
XMPP的核心XML流传输协议的定义使得XMPP能够在一个比以往网络通信协议更规范的平台上。借助于XML易于解析和阅读的特性,使得XMPP的协议能够非常漂亮。
XMPP中定义了三个角色,客户端,服务器,网关。通信能够在这三者的任意两个之间双向发生。服务器同时承担了客户端信息记录,连接管理和信息的路由功能。网关承担着与异构即时通信系统的互联互通,异构系统可以包括SMS(短信),MSN,ICQ等。基本的网络形式是单客户端通过TCP/IP连接到单服务器,然后在之上传输XML。
XMPP通过TCP传输的是与即时通讯相关的指令。在以前这些命令要么用2进制的形式发送(比如QQ),要么用纯文本指令加空格加参数加换行苻的方式发送(比如MSN)。而XMPP传输的即时通讯指令的逻辑与以往相仿,只是协议的形式变成了XML格式的纯文本。这不但使得解析容易了,人也容易阅读了,方便了开发和查错。而XMPP的核心部分就是一个在网络上分片断发送XML的流协议。这个流协议是XMPP的即时通讯指令的传递基础,也是一个非常重要的可以被进一步利用的网络基础协议。所以可以说,XMPP用TCP传的是XML流。
4.4 消息状态机
Message对象状态转换的规则:
1、消息的读、写和拷贝操作只能作用于状态为Created的消息上;
2、消息的读、写和拷贝将消息状态从Created转换成Read、Written和Copied。
3、所有状态的消息都可以直接关闭,关闭后消息的状态转换为Closed
4.5 网络IO
网络IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO。
4.5.1 BIO
在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信,默认情况下服务端需要对每个请求建立一堆线程等待请求,而客户端发送请求后,先咨询服务端是否有线程相应,如果没有则会一直等待或者遭到拒绝请求,如果有的话,客户端会线程会等待请求结束后才继续执行。
4.5.2 NIO
NIO本身是基于事件驱动思想来完成的,其主要想解决的是BIO的大并发问题: 在使用同步I/O的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。也就是说,将每一个客户端请求分配给一个线程来单独处理。这样做虽然可以达到我们的要求,但同时又会带来另外一个问题。由于每创建一个线程,就要为这个线程分配一定的内存空间(也叫工作存储器),而且操作系统本身也对线程的总数有一定的限制。如果客户端的请求过多,服务端程序可能会因为不堪重负而拒绝客户端的请求,甚至服务器可能会因此而瘫痪。
NIO基于Reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。 也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
BIO与NIO一个比较重要的不同,是我们使用BIO的时候往往会引入多线程,每个连接一个单独的线程;而NIO则是使用单线程或者只使用少量的多线程,每个连接共用一个线程。
NIO的最重要的地方是当一个连接创建后,不需要对应一个线程,这个连接会被注册到多路复用器上面,所以所有的连接只需要一个线程就可以搞定,当这个线程中的多路复用器进行轮询的时候,发现连接上有请求的话,才开启一个线程进行处理,也就是一个请求一个线程模式。在NIO的处理方式中,当一个请求来的话,开启线程进行处理,可能会等待后端应用的资源(JDBC连接等),其实这个线程就被阻塞了,当并发上来的话,还是会有BIO一样的问题。
HTTP/1.1出现后,有了Http长连接,这样除了超时和指明特定关闭的http header外,这个链接是一直打开的状态的,这样在NIO处理中可以进一步的进化,在后端资源中可以实现资源池或者队列,当请求来的话,开启的线程把请求和请求数据传送给后端资源池或者队列里面就返回,并且在全局的地方保持住这个现场(哪个连接的哪个请求等),这样前面的线程还是可以去接受其他的请求,而后端的应用的处理只需要执行队列里面的就可以了,这样请求处理和后端应用是异步的.当后端处理完,到全局地方得到现场,产生响应,这个就实现了异步处理。
目录
4.5.3 AIO
与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序。 即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。 在JDK1.7中,这部分内容被称作NIO.2,主要在java.nio.channels包下增加了下
下面四个异步通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
其中的read/write方法,会返回一个带回调函数的对象,当执行完读取/写入操作后,直接调用回调函数。

















 2906
2906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}