







Linux的bash:
1. 检查命令是否为bash的内置命令:
type [-tpa] command
- t :当加入-t时type会将command以下列的字眼显示出它的意义:
- file:外部命令
- alias:该命令是某一命令设置的别名
- builtn:该命令是bash的内置命令
- p:如果后边接的是外部命令,就显示完整文件名
- a:会从PATH变量定义的路径中,将所有含有command的命令都列出来
2. bash中变量的显示和设置:
(显示变量)eccho $变量名
(设置变量)变量名=变量值变量的设置规则:
- 变量和变量值以一个=连接
- 等号两边不能直接接空格符
- 变量名称只能是英文字母和数字,而且不能以数字开头
- 变量内容若有空格符可以使用双引号” “或者单引号’ ‘将变量内容结合起来:
- 双引号里边有特殊字符的可以保留原来的本意
- 单引号里边的特殊字符仅仅是一般字符(纯文本)
- 可以使用转义字符” \ “将特殊字符转换成为一般字符
- 在一串命令中还需要通过其他命令提供的信息,可以使用反单引号“ `命令` ”或者是“$(命令)”这样的方式来引用
- 若该变量为了增加变量内容时,则可以使用” 变量名称"或者是 {变量}的方式来累加内容
- 若要使变量在其子进程也能使用,则需要使用export命令来将其转换乘为环境变量
- 通常大写字符为系统默认变量,自定义变量为小写字符
- 取消变量可以使用unset命令:
- unset 变量名称
3. 列出当前shell环境下的所有环境变量和内容:
evn
或者是
export
4. 变量内容的删除:
变量的删除主要是通过#和##以及通配符*来解决的
- #:符合替换文字的最短的一个
- ##:符合替换文字的最长的一个
- %:从后边开始匹配要删除的字符的最短的一个
- %:从后边开始匹配要删除的字符的最长的一个
- *:代替0到无穷多个任意字符
例如:

命令解释:
删除了从最开始一直到usr/sbin:这个内容的变量值。path是要操作的变量名,后边加一个#比哦啊是替换符合文字的最短的一个,后边就跟上要删除的变量值,其中用*代替任意多个字符,一直到user/sbin:这个内容为止。
5. 变量内容的替换:
变量内容额替换主要是通过/和//来完成
- /:若变量内容符合旧字符串,则第一个旧字符串会被替换
- //:若变量内容符合旧字符串,则全部的旧字符串会被替换掉
例如:

6. 别名设置:
(设置别名)alias 命令别名 命令
(取消别名)unalias 别名alias lm=’ls -l | more’
这样之后执行lm命令时就相当于执行ls -l 和more命令
7. 历史命令:
history [n]
history [-c]
history [-raw] histfilesn:数字,要列出的最近的n条命令
- c:将目前shell中的所有history都删除
- a:将目前新增的history增加到histfiles中
- r: 将histfiles中的命令读到当前shell的缓冲中
- w:将目前的history中的内容写到histfiles中
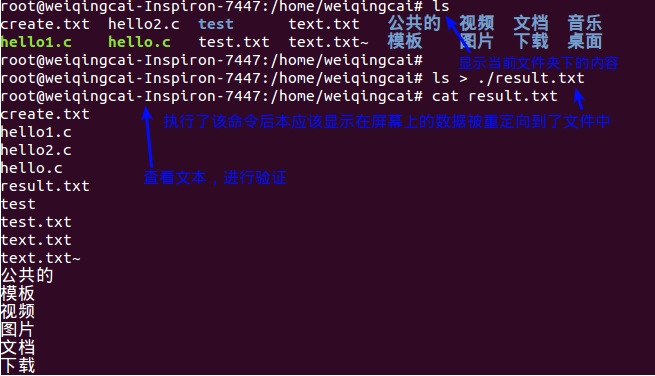
8. 数据流重定向:
- 标准的输入:代码为0,使用<或者<<
- 标准的输出:代码为1,使用>或者>>
- 标准的错误输出:代码为2,使用2>或者2>>
>和>>的区别在于在写入数据时>会自动覆盖文件中的已有数据,而>>则是以追加的方式写入
例如:
9. 命令执行判断依据:
cmd ; cmd
;:依次执行两个不相关的命令
或者
cmd && cmd
cmd || cmd
命令执行情况 说明 cmd1 && cmd2 若cmd1执行完毕并且正确执行,则开始执行cmd2 若cmd1执行完毕且错误,则不执行cmd2 cmd1 || cmd2 若cmd1执行完毕并且正确执行,则不执行cmd2 若cmd1执行完毕且错误,则开始执行cmd2
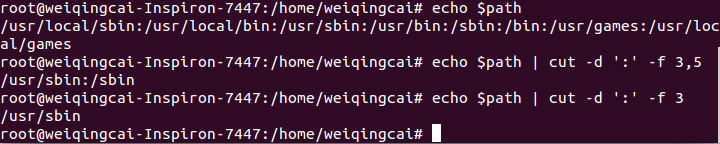
10 . 管道命令:
(用于分割字符)cut -d ‘分割字符’ -f fields
(用于排列整齐的信息) cut -c 字符范围
- d:后边接分割字符,与-f一起使用
- f:依据-d后边的分割字符将一段信息切割成数段,并用-f取出第几段
- c:以字符的单位取出固定字符区间
或者:
grep [-acunv] [–color=auto] ‘查找字符串’ filename
- a:将二进制文件以txt的方式查找数据
- c:计算找到字符串的次数
- i:忽略大小写不同
- n:顺便输出行号
- v:反向输出,即输出不包含要查讯字符串的那一行
- color=auto:将找到的关键字部分加上颜色区分
Linux的正则表达式与格式化处理:
1. 基础正则表达式:
| RE字符 | 意义 |
|---|---|
| ^word | 待查找的字符串(word)在行首 |
| word$ | 待查找的字符串(word)在行尾 |
| 空格 | 代表一个有一定意义字符的字符 |
| \ | 转义字符,将特殊字符的意义去掉 |
| * | 重复0到无穷多个的前一个字符 |
| [list] | 从字符集合的RE字符中找出想要选取的字符 |
| [n1-n2] | 从字符集合的RE字符中找出想要选取的字符范围 |
| [^list] | 从字符集合的RE字符中找出不要的字符或者范围 |
| \{n,m\} | 连续n到m个的前一个RE字符,若为\{n\}则是连续n个的前一个RE字符,若为\{n,\}则是连续n个以上的前一个RE字符 |
2. sed工具:
sed [-nefr] [动作]
- n:使用安静模式,只有进过sed处理的那一行才会被列出
- e:直接在命令行的模式上进行sed编辑
- f:直接将sed的命令写在一个文件内,-f filename可以直接执行filename内的sed动作
- r:sed的动作支持的是拓展型的正则表达式的语法
- i:直接修改文件读取的内容而不是屏幕输出
- 动作:[n1[,n2]]function
- function参数:
- a:新增,a的后边可以接字符串,而这些字符串会出现在新的一行
- c:替换,c的后边可以接字符串,这些字符串可以替换n1,n2之间的行
- d:删除
- i:插入,i的后比那也可以接字符串,而且字符串会出现在新的一行
- p:打印,将某个选择的数据打印出来
- s:替换,可以直接进行替换的工作
3. 拓展的正则表达式:
| RE字符 | 意义 |
|---|---|
| + | 重复一个或者一个以上的前一个RE字符 |
| ? | 零个或者一个的前一个RE字符 |
| | | 用或的方式找出数个字符串 |
| () | 找出组字符串 |
| ()+ | 多个重复组的判别 |
4. 文件格式化打印:
printf ‘打印格式’ 实际内容
\a:警告声音输出
\b:退格键
\f:清除屏幕
\n:输出新的一行
\r:Enter键
\t:水平的Tab键
\v:竖直方向的Tab键
\xNN:NN为两位数的数字,可以将其转换成为字符
5. awk:
awk ‘条件类型1 {动作1} 条件类型2 {动作2} 条件类型3 {动作3}….’ filename















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









