







目录
选择【手动输入】粘贴DOI地址(也可选择其他导入方式),点击【保存设置】
以上设置完成后即可点击【采集】,开始数据采集,待完成后导出即可。
tips4:任务意外中断后,找到已爬取数据,(减少重复爬的时间)
1.新建任务:
依次点击:
-
【首页】(左侧边栏)【新建】——【自定义任务】
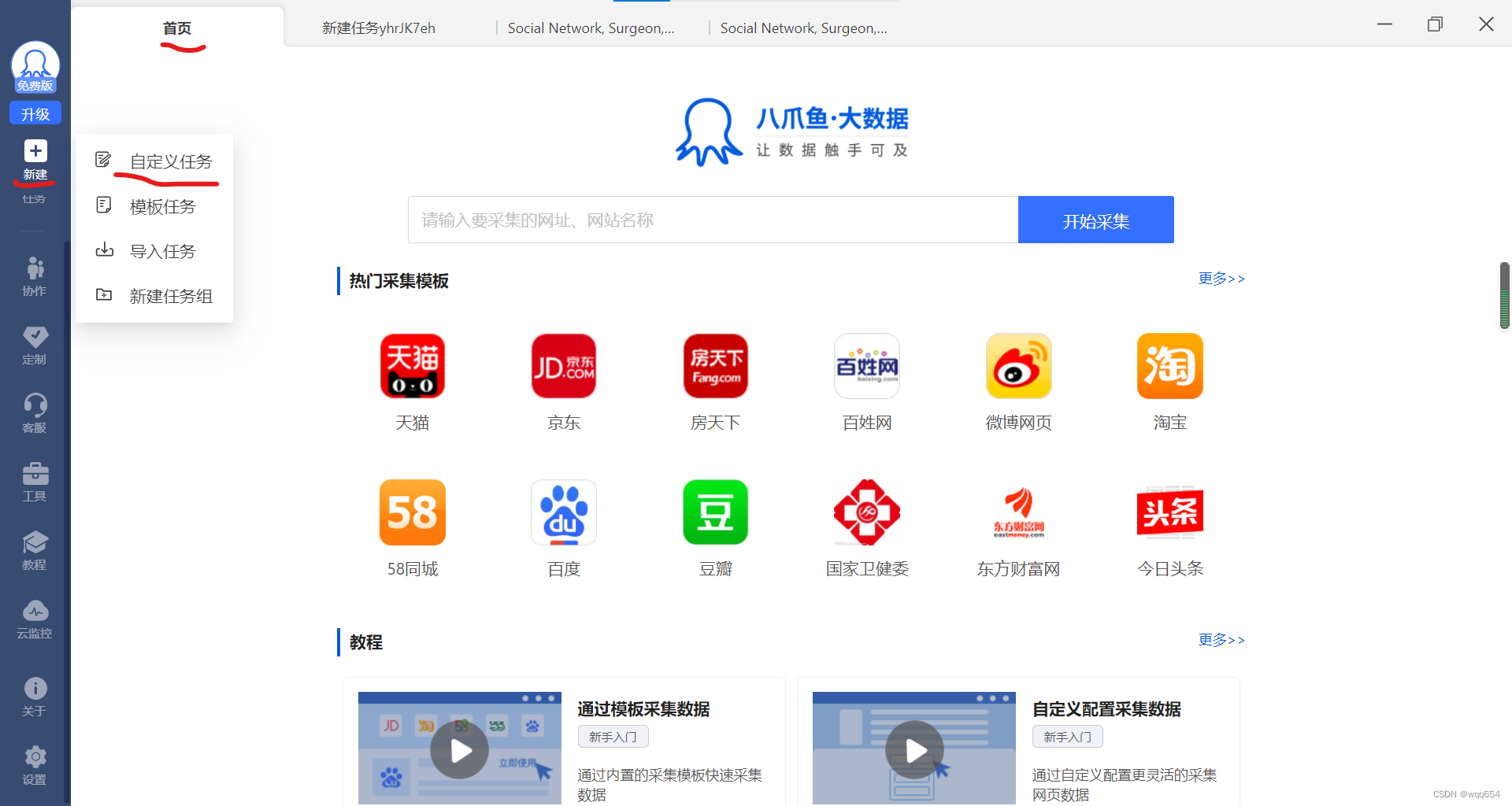
-
新建任务组,随意输入任务名,点击确定
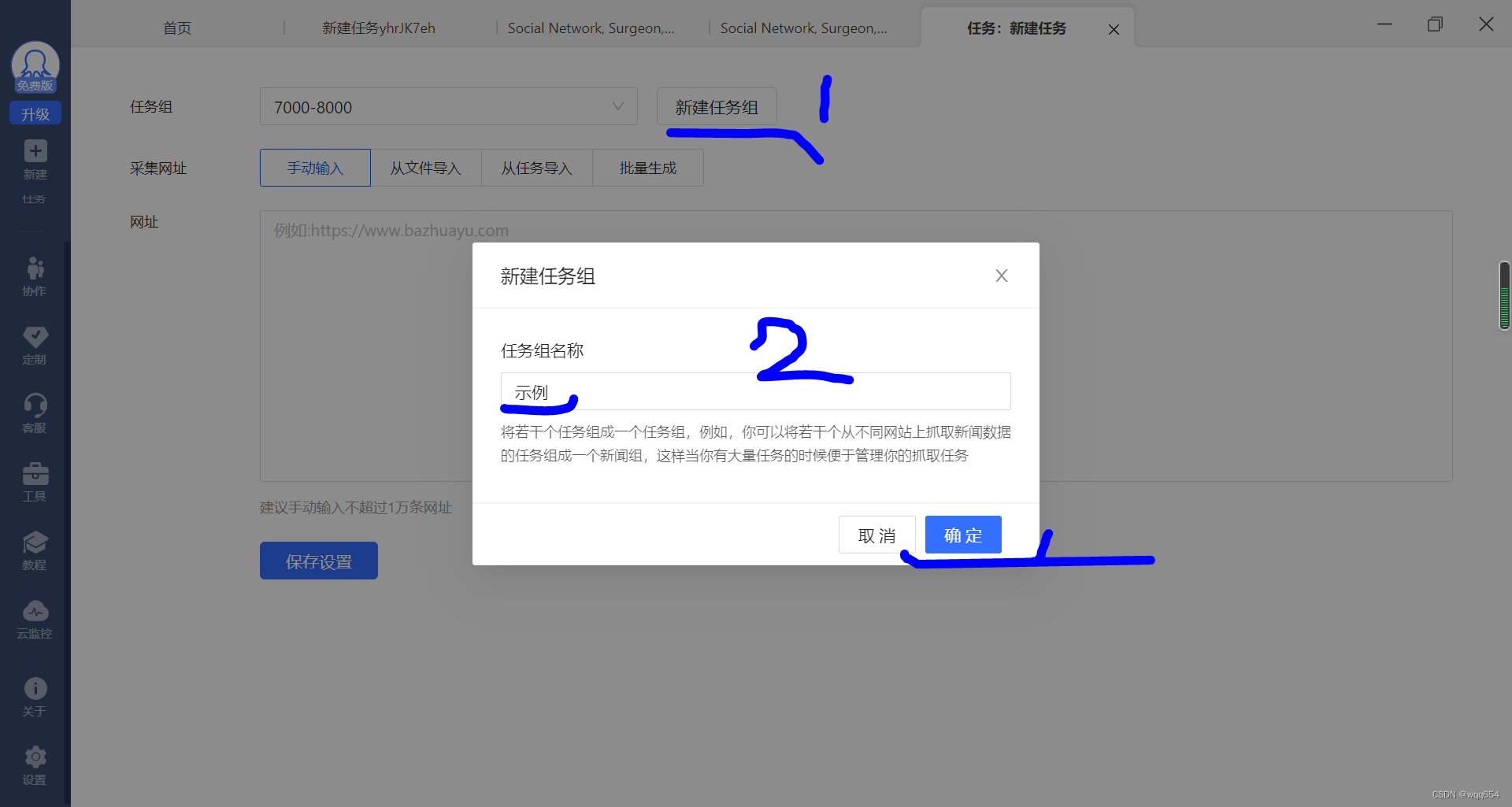
-
选择【手动输入】粘贴DOI地址(也可选择其他导入方式),点击【保存设置】
(注意:手动输入最多1万条,文件导入最多1百万条。)
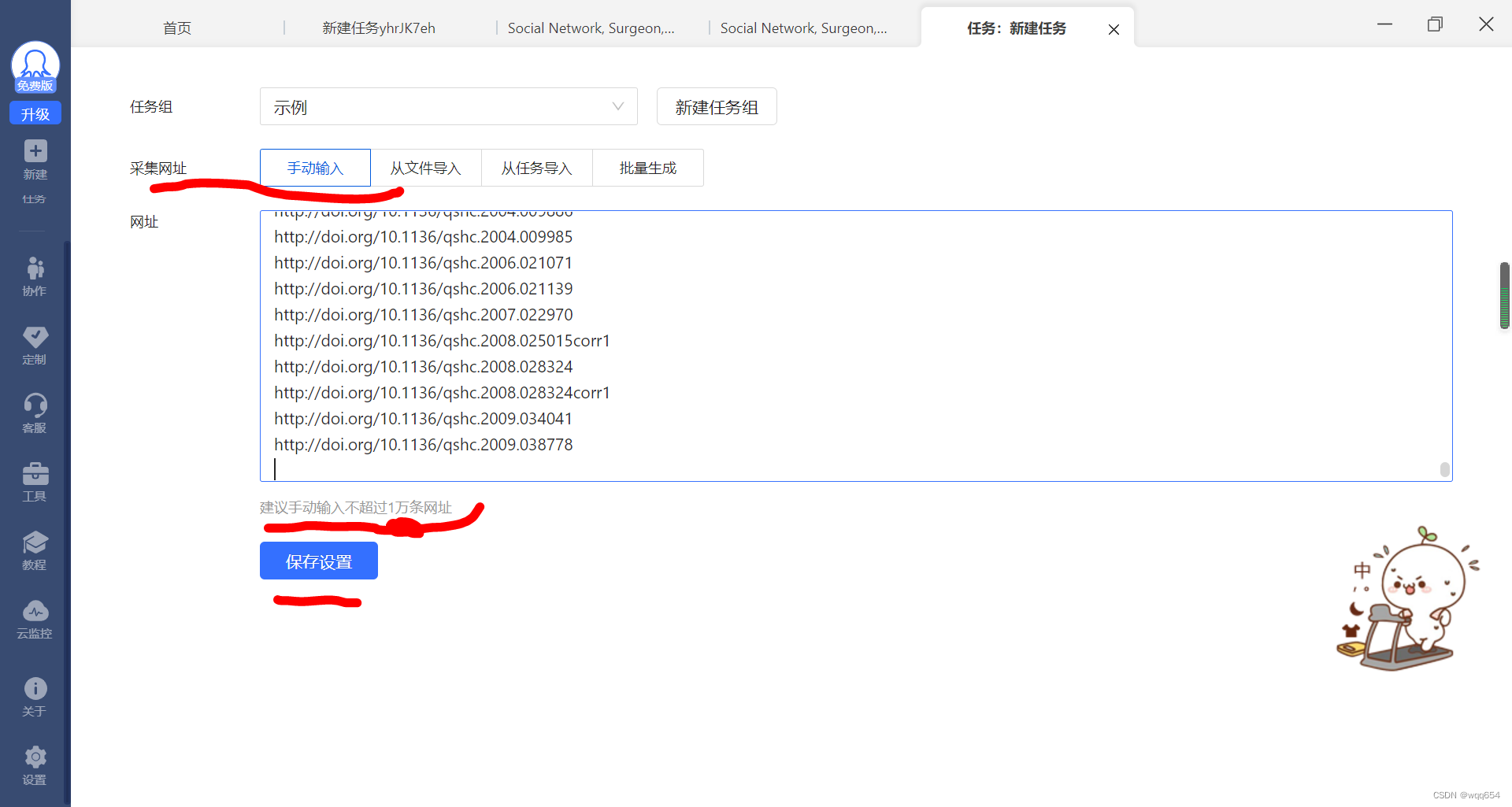
2.采集设置
待页面加载出来:
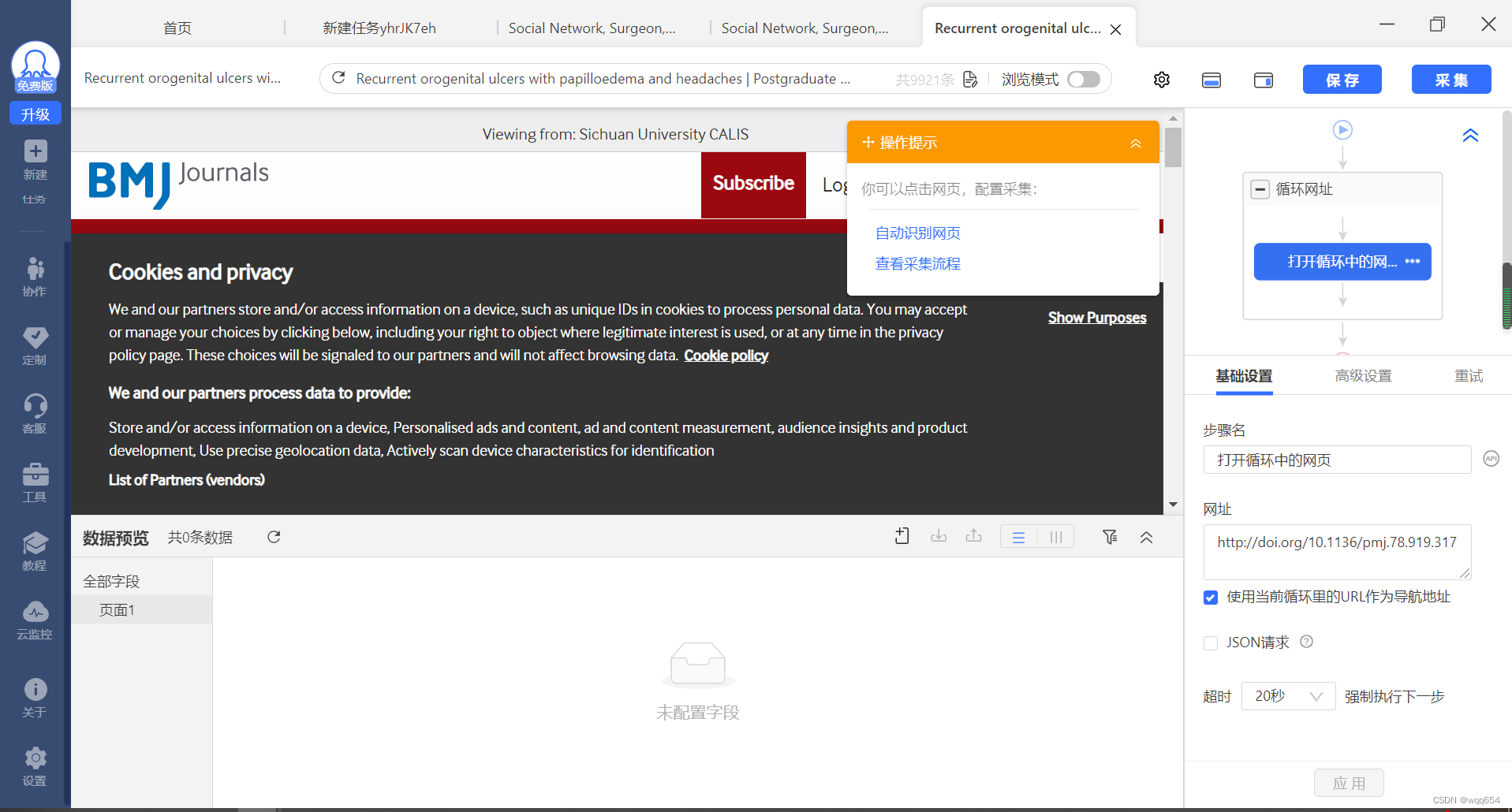
-
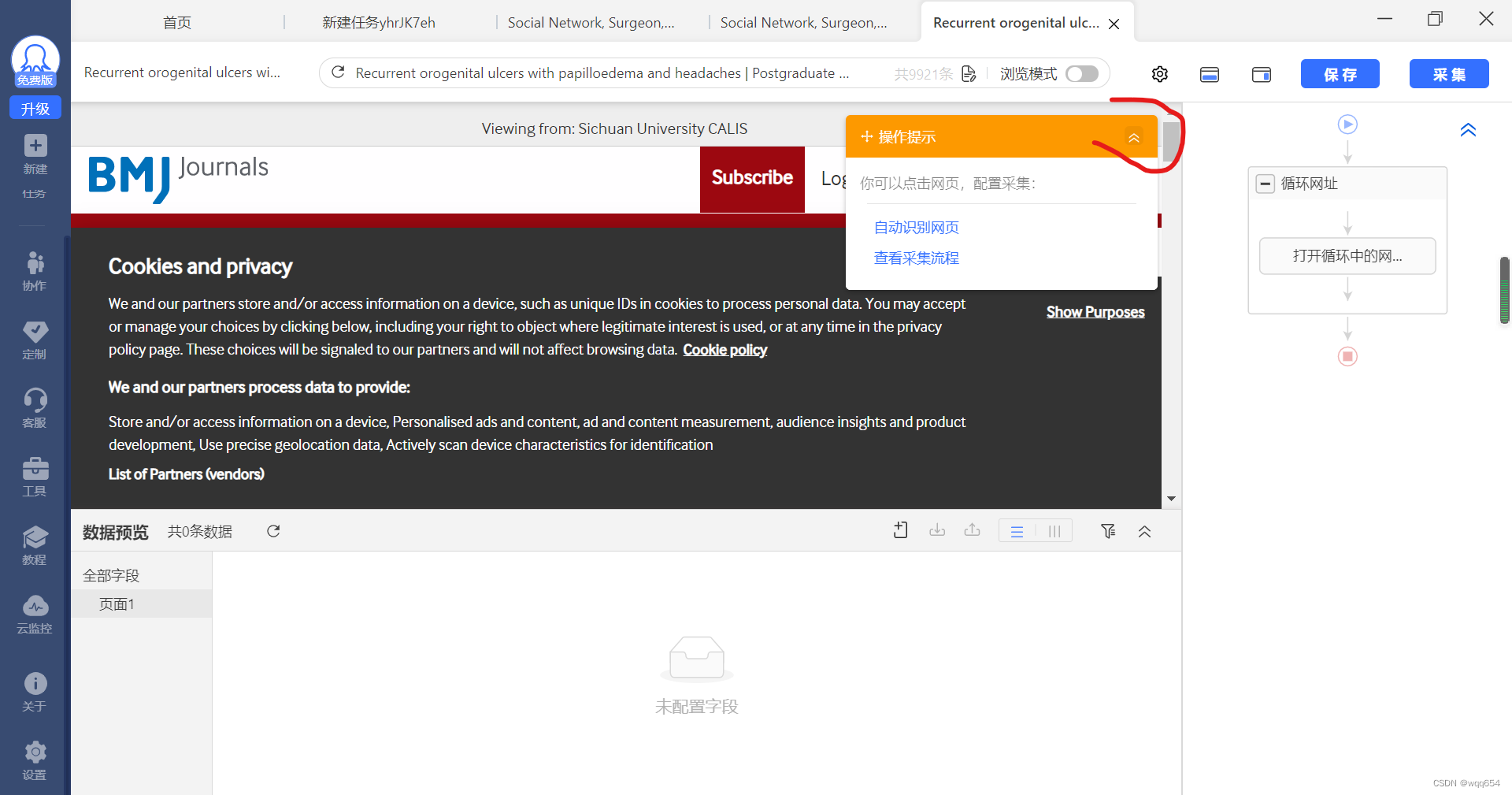
去除弹出的cookie窗口,以免影响视线:(此步视情况,非必要)
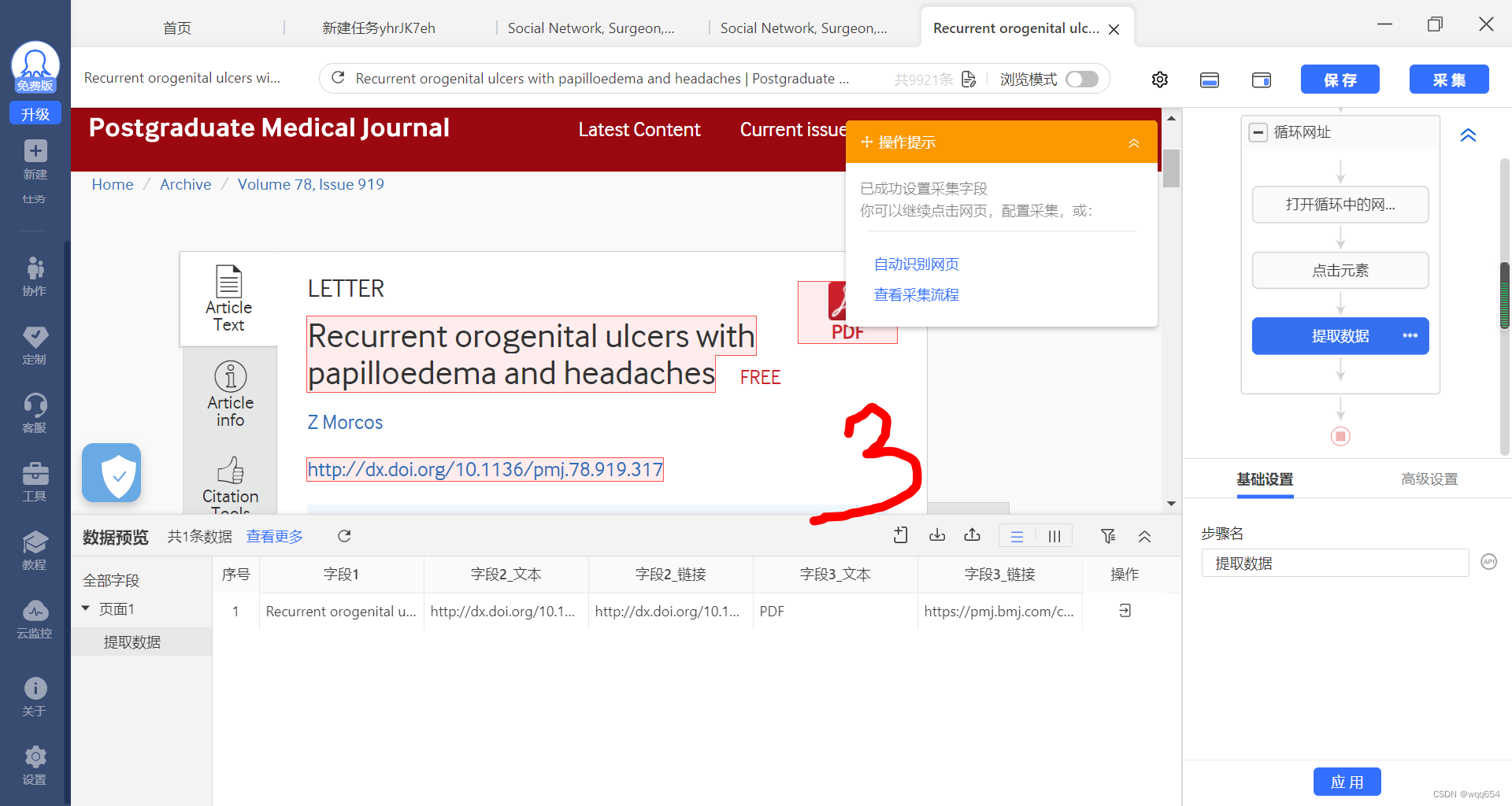
点击下图中的箭头,收起提示框,
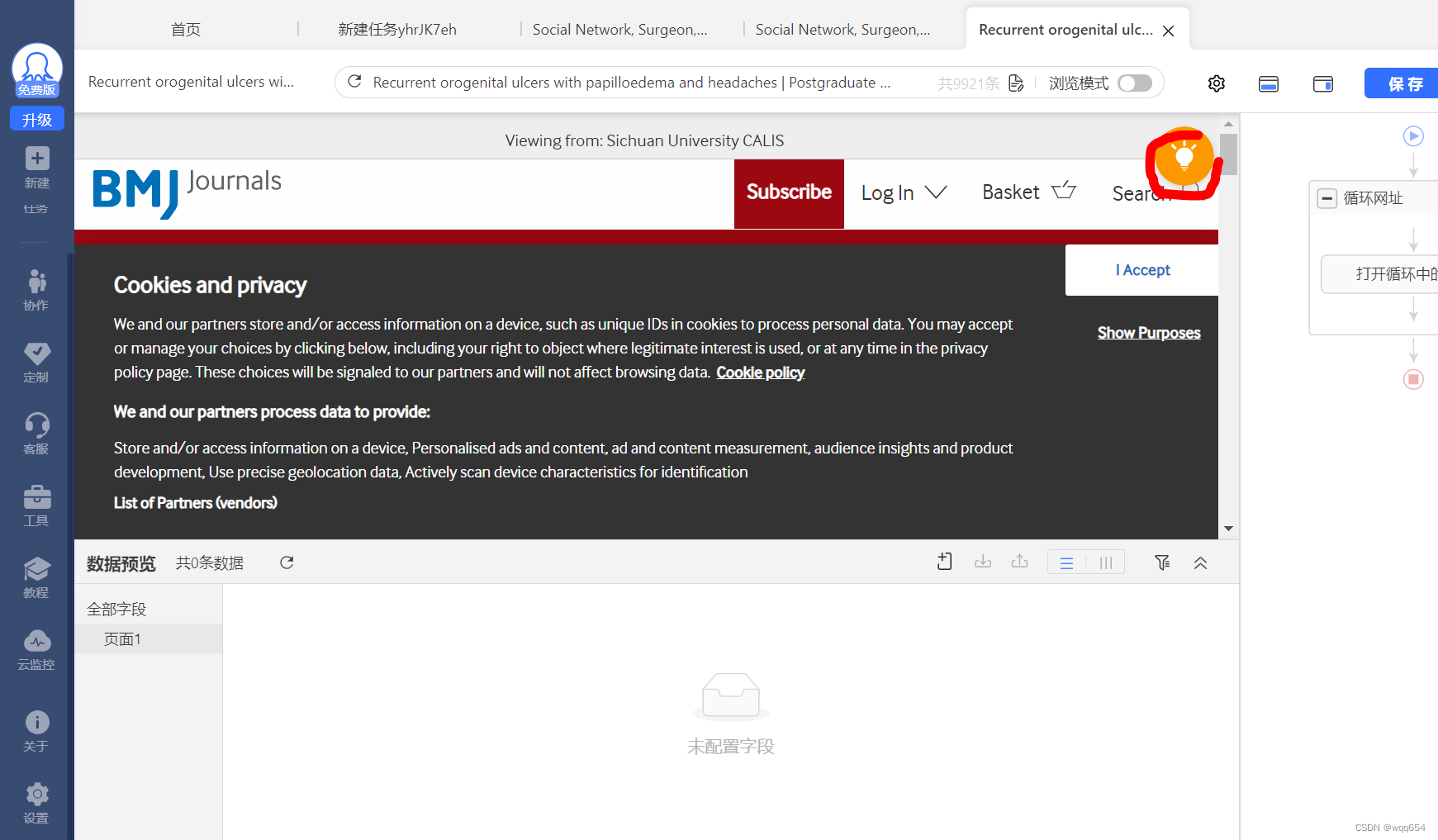
依次点击下图标记
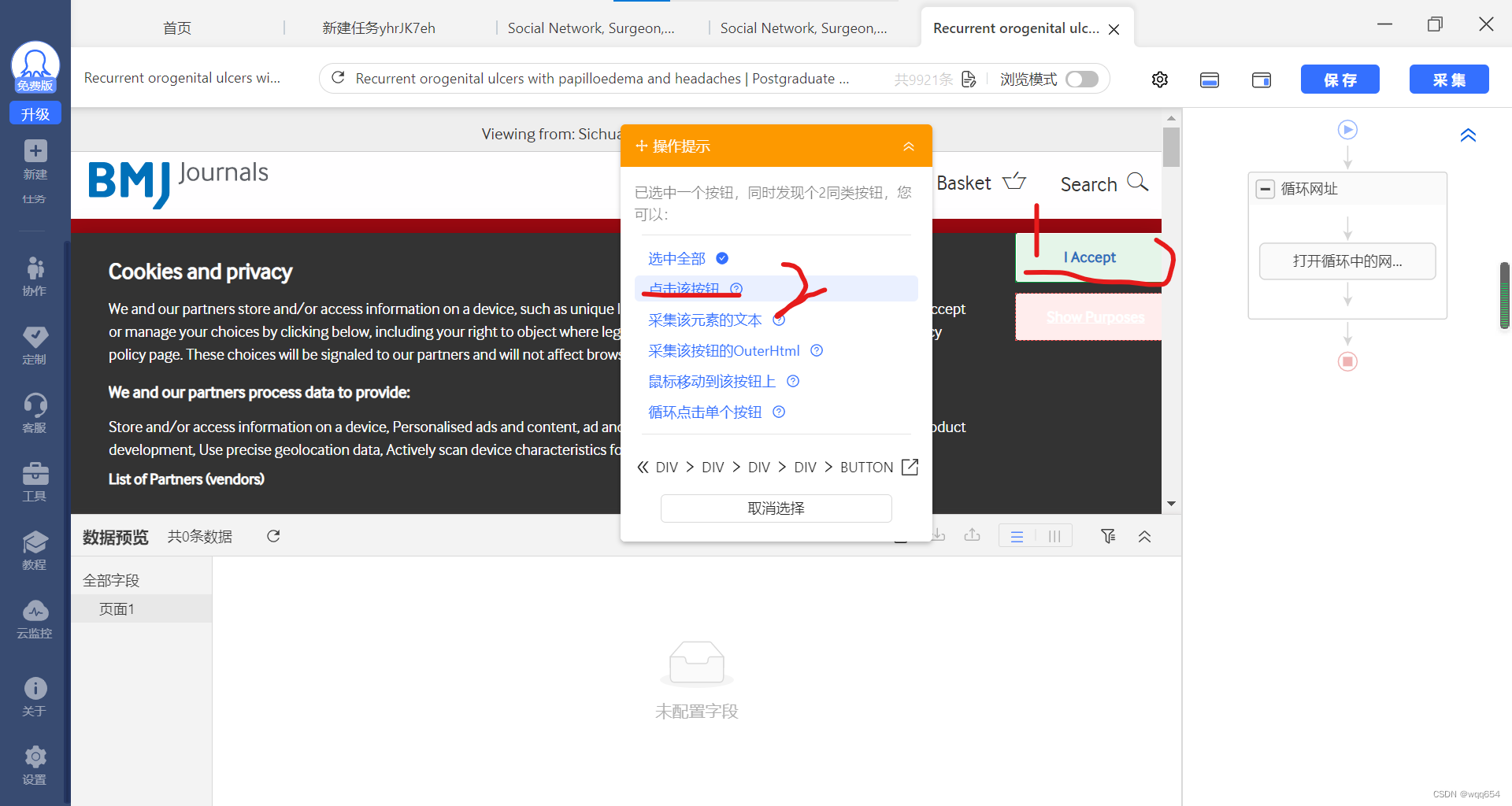
上步之后,右侧流程框里多了一个“点击元素”步骤,可如下删除,(不删也没有影响)

-
添加采集流程:
在网页中选择需要提取的元素,页面底下会出现已选字段,选择完毕后点击【采集数据】
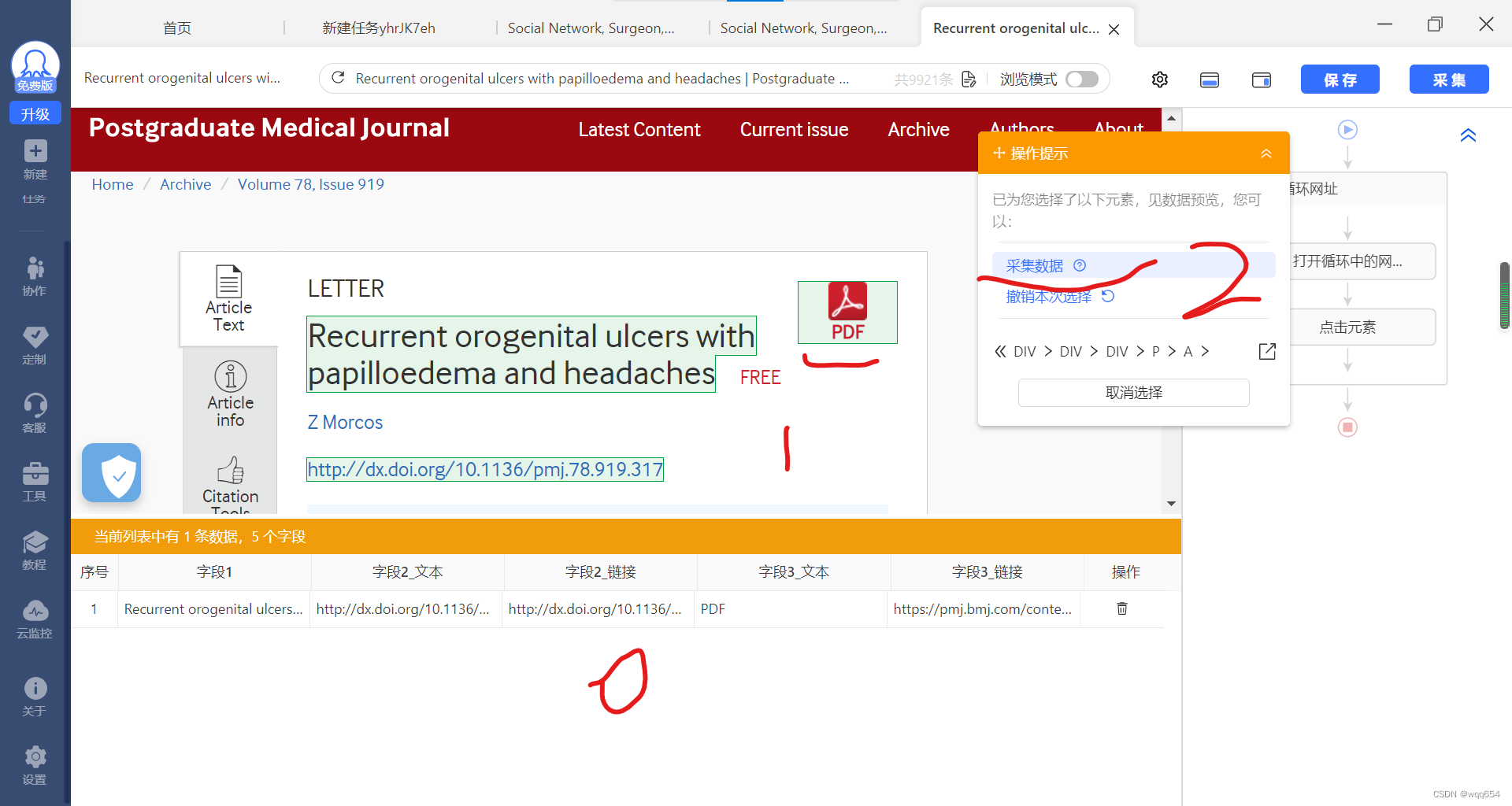
-
设置采集字段
点击字段名称旁的三个小点,选择对字段的操作,(本例此处删除多余字段),双击字段名可更改字段名称。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









