







论文:https://arxiv.org/abs/2410.07718
代码:https://github.com/fudan-generative-vision/hallo2
模型:https://huggingface.co/fudan-generative-ai/hallo2
前言:在2024年6月,复旦大学的研究团队推出了Hallo项目,这是一个用于纵向图像动画的分层音频驱动视觉合成技术,引起了广泛关注。紧接着,京东健康基于Hallo模型使用中文数据训练了新的模型JoyHallo。到了10月16日,Hallo2作为Hallo的升级版本惊艳亮相。本文将主要介绍Hallo2的相关论文内容。
摘要
本论文介绍了Hallo模型的更新,提出了一系列设计增强以扩展其功能。首先,本论文将该方法扩展至制作更长时间的视频,并针对外观漂移和时间伪影等挑战,研究了在条件运动框架的图像空间内的增强策略。具体来说,本论文引入了一种结合高斯噪声增强的贴片滴技术,以增强视觉一致性和长期的比例相干性。
其次,本论文实现了4K分辨率的肖像视频生成。为此,本论文实现了潜在码的向量量化,并应用时间对齐技术以保持跨时间维度的一致性。通过集成高质量的解码器,本论文实现了4K分辨率的可靠合成。
第三,本论文将可调整的文本标签作为条件输入,扩展了超越传统音频线索的应用范围,以提高内容的丰富性和可控性。据本论文所知,Hallo2是首个实现4K分辨率和长小时音频驱动肖像图像动画的方法。本论文已经在公开的数据集上进行了广泛的实验评估,包括HDTF、CelebV以及本论文引入的“野生”数据集。实验结果表明,本论文提出的方法在长时间肖像视频动画中取得了最先进的性能,成功地生成了持续时间长达几十分钟的4K分辨率的丰富和可控内容。
参考视频:https://fudan-generative-vision.github.io/hallo2
一、引言
1.扩展功能的选择
本论文将Hallo模型的应用范围从生成简短的肖像动画扩展至支持长达十几分钟的视频生成。如图所示,长期视频生成通常采用两种主要方法。第一种方法是在控制信号的引导下并行生成音频驱动的视频片段,并在这些剪辑的相邻帧之间应用外观和运动约束(陈等人,2024)。这种方法的一个主要限制是必须保持外观和运动的最小差异,这限制了嘴唇运动、面部表情和姿势的实质性变化,由于强制的连续性限制,常常导致模糊和扭曲的表现和姿势。第二种方法通过利用预测帧作为条件信息,逐步生成新的视频内容(Xu等人,2024a;田等人,2024;王等人,2021)。虽然这种方法允许连续运动,但也容易出现错误积累,失真、相对于参考图像的变形、噪声伪影或前一帧中的运动不一致可能会传播到后续帧中,从而降低整体视频质量。
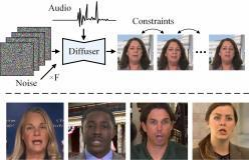
并行生成,由于帧间连续性约束,并行生成可能导致模糊和扭曲的表达式。
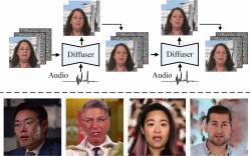
增量生成,增量生成方法在面部特征和背景中都存在误差积累。
为了实现高表现力、现实主义和丰富的运动动力学,本论文采用了第二种方法。本论文的方法主要从参考图像中获得外观,仅利用先前的生成框架来传达运动动力学——包括嘴唇运动、面部表情和姿势。为了防止前一帧对外观信息的污染,本论文实现了匹配-下降数据增强技术,该技术在预测运动特征的同时,对条件帧中的外观信息进行受控破坏。这种方法表明,外观主要来自参考肖像图像,在整个动画中保持强大的身份一致性,并支持持续运动的长视频。此外,为了增强对外观污染的弹性,本论文将高斯噪声作为一种附加的数据增强技术,在有效利用运动信息的同时进一步增强对参考图像的保真度。
其次,为了实现4K视频分辨率,本论文扩展了矢量量化基因对抗网络(VQGAN)Esser等人(2021)编码序列预测的离散码本空间方法,将任务引入时间维度。通过将时间对齐纳入代码序列预测网络,本论文在预测的代码序列视频中实现了平滑过渡。在应用高质量的解码器后,外观和运动的强一致性允许本论文的方法增强高分辨率细节的时间相干性。
第三,为了增强对长期肖像视频生成的语义控制,本论文引入了统一的文本提示作为条件输入。通过在不同的时间间隔内注入文本片段,本论文的方法可以帮助调整面部表情和头部姿势,从而使动画更加逼真和富有表现力。
为了评估本论文提出的方法的有效性,本论文在公开的数据集上进行了全面的实验,包括HDTF、CelebV和本论文引入的“野生”数据集。据本论文所知,本论文的方法是第一个在肖像图像动画中达到4K分辨率,持续时间可达10分钟甚至几个小时的方法。此外,通过结合可调节的文本提示,使在生成过程中精确控制面部特征,本论文的方法确保了在生成的动画中具有高水平的真实性和高水平的多样性。
二、相关工作
视频扩散模型: 基于扩散的模型在提供来自文本和图像输入的高质量和真实视频方面展现出了显著的能力(朱等,2024;张等,2024)。稳定的视频扩散,缓冲器等(2023)强调了潜在码视频扩散方法,利用预训练、微调和策划的数据集来提高视频质量。制作一个视频的歌手等(2022)利用文本到图像的合成技术优化文本到视频的生成,而不需要进行数据生成。周等(2022a)引入了一种具有新颖的3D U-Net设计的高效框架,减少了计算成本。动画DiffGuo等(2023)启用个性化的文本到图像模型,通过插件的动画和游戏运动模块。进一步的贡献,如视频作曲家王等(2024b)和视频管理员陈等(2023a),强调视频生成的可控性和质量。视频作曲家集成了运动矢量的动态引导,而视频工匠提供开源模型。CogVideoX Yang等(2024)通过专家变形金刚增强文本-视频对齐,而MagicTime Pun等(2024)用元模型解决物理知识的编码-物理延迟模型。在这些进步的基础上,本论文的方法采用了优越的预先训练的扩散模型,专注于长时间和高分辨率的合成。
音频扩散模型: 在音频驱动的语音耳机提醒和肖像图像动画方面取得了重大进展,强调了现实主义和与音频输入的同步。LipSync专家Prajwal等(2023)和VividTalk太阳等(2023)结合了3D运动建模和头部姿势生成,以增强表达力和时间同步。基于扩散的技术进一步推进了该领域。沈等(2023)和梦之谈马等(2023)改善了视频质量,同时保持不变-识别跨不同身份的同步。Xu等(2024b)和AniTalker刘等(2024)整合了细致的面部表情和普遍的运动表征,导致生活类似的和同步的动画。魏安文肖像等(2024)、EchoMimic陈等(2024)、V-王氏快递等(2024a)、Loopy江等(2024)、CyberHost林等(2024)和EMO田等(2024)有助于增强能力,专注于表现力、情感和身份保持。尽管有这些进步,但推广具有一致的视觉质量和时间一致性的长时间、高分辨率的视频仍然是一个挑战。本论文的方法建立在Hallo Xu等(2024a)的基础上,通过实现现实的高分辨率动态来解决这一差距,长期肖像图像中的动态变化。
长视频和高分辨率视频生成: 最近的视频扩散模型显著提高了长时间、高分辨率视频的生成。框架,如柔性扩散建模,Harvey等(2022)和l世代视频Harvey等(2022)改进时间一致性并使文本驱动的视频生成无需额外训练。方法如SEINE Chen等(2023b)和Storm Diffusion周等(2024)引入生成性转基因-动画和语义运动预测器,为平滑的场景变化和视觉讲故事。像SimplifyT2V Hensel等(2024)和Movie Dreamer赵等(2024)使用自回归策略和扩散渲染的扩展叙事视频的裁缝师。Video-Infinite Tan等(2024)通过分区推理优化长视频合成,而Free-D龙陆等(2024)集成了全球和局部的视频功能,无需一致性训练。在本文中,本论文采用斑块下降和高斯噪声增强来实现长时间的描述动画。
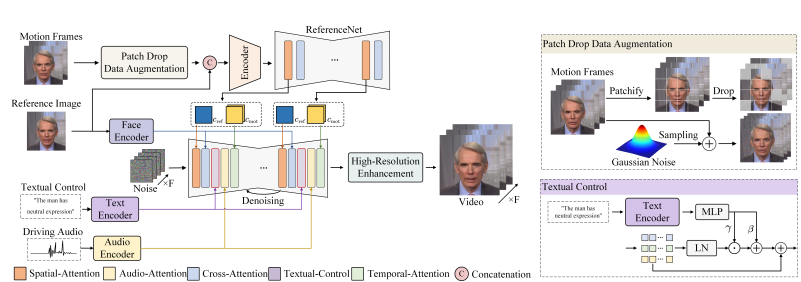
图为所提出方法的框架。右侧显示了所提出的补丁下落数据增强和文本提示控制的细节。cref和cmot指的是参考图像和运动帧的特征。
利用学习字典进行的离散先验表示已被证明对图像恢复是有效的。VQ-VAE Razavi等(2019)通过向量量化引入离散潜在空间来增强VAEs,解决后路崩溃,并实现高质量的图像、视频和语音生成功能。在此基础上,VQ-GAN Lee等(2022)结合CNN和Transformer来创建一个上下文丰富的图像组件词汇表,在条件图像生成中实现干扰的状态。编码执行者周等(2022b)使用一个学习过的离散码本进行盲脸修复系统,采用基于Transformer的网络来增强不退化的鲁棒性。本论文提出了一种基于时间对齐技术的潜在码向量量化方法,以实现4K合成的高分辨率时间相干性。
三、准备工作
Latent Diffusion Models(LDMs)标志着生成模型领域的重大突破,它通过在压缩的潜在空间而非直接在高维图像空间中执行扩散和去噪过程,降低了计算复杂度,同时保持了生成图像的高质量。具体来说,论文中的方法利用预训练的变分自编码器(VAE)将输入图像编码为低维潜在表示,然后通过在这些潜在表示上添加高斯噪声来生成一系列噪声变量。逆向扩散过程的目标是重建原始潜在向量,这一过程通过顺序去噪实现,其中噪声预测网络估计每一步中的噪声分量,并利用条件信息进行优化。
论文中的关键创新之一是整合了交叉注意力机制,这一机制有效地将运动条件融入模型中,处理噪声潜在变量和嵌入的运动条件,从而指导去噪过程。这种集成的交叉注意力层使得模型能够根据当前的潜在状态和提供的条件动态调整焦点,生成与条件输入一致的图像,增强了动画肖像的表现力和真实感。
在论文的研究中,运动条件包括参考图像嵌入、音频特征和通过对比语言-图像预训练(CLIP)获得的文本嵌入,这些多模态条件的结合允许对生成动画中的面部表情、唇动和头部姿势进行精细控制。论文中提出的方法不仅在图像修复和类条件图像合成方面取得了新的最先进成绩,而且在无条件图像生成、文本到图像合成和超分辨率等各项任务上展现出高度竞争力,同时降低了计算需求。
四、方法
在本节中,论文将详细介绍一种创新的肖像图像动画技术,该技术有效地应对了在长时间、高分辨率视频生成以及复杂动态运动中保持视觉质量和时间一致性的挑战。此外,该技术还支持通过音频驱动和文本提示进行控制。论文中提出的方法主要依赖于从单一参考图像中提取目标对象的外观特征,同时巧妙地利用先前生成的帧作为条件输入,以捕获和传递运动信息。
为了确保生成的视频在视觉上与参考图像保持一致,并防止前一帧的信息对当前帧造成不利影响,论文中引入了一种创新的斑点数据增强技术,该技术结合了高斯噪声注入,以增强模型对外观特征的保持能力。此外,论文中还将VQGAN的离散码本预测技术扩展到时间维度,这一策略不仅提升了视频的分辨率,还进一步增强了视频在时间维度上的连贯性。
论文中还提出了一种将文本条件与音频信号相结合的方法,这允许在长期视频生成过程中,对面部表情和头部运动进行精细的双向控制,从而提升动画的表现力和真实感。最后,论文将详细阐述网络结构的设计,以及训练和推理策略,这些策略是实现高效和高质量视频生成的关键。通过这些方法,论文中提出的技术为肖像图像动画领域带来了显著的进步。
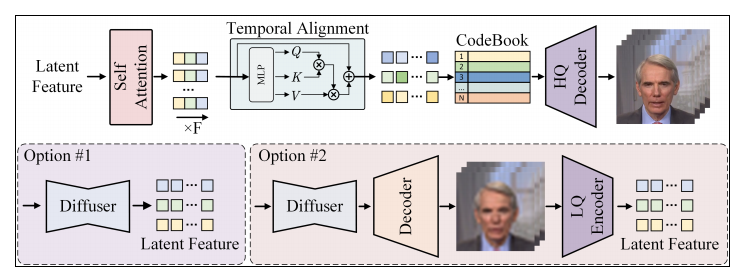
图片展示了一个用于高分辨率增强模块的示意图,该模块是用于图像或视频生成过程中提高输出质量的关键技术。图片中描述了两种不同的设计选项,用于提取输入的潜在特征,这些特征随后用于生成高分辨率的输出。其核心是展示如何通过不同的处理路径来提取和处理潜在特征,以生成高分辨率的图像或视频。两种选项提供了不同的方法来平衡计算效率和输出质量。
4.1长时间动画
论文提出了一种用于长期肖像视频动画的技术,旨在解决在保持一致外观的同时展现丰富运动动态的挑战。为了实现这一目标,论文中引入了一种称为“patch-drop augmentation”的斑点数据增强技术,该技术应用于条件帧,以破坏前一帧的外观信息,同时保留其运动线索。这种方法确保了模型主要依赖参考图像来获取外观特征,并利用前一帧来捕捉时间动态。
具体来说,参考图像Iref和前N帧生成的帧{It−1, It−2, …, It−N}被用来生成动画。为了减少前一帧外观信息的影响,对每一帧It−i应用了patch-drop增强,将每帧分割成K个不重叠的p×p大小的块,并为每个块生成一个二进制掩码Mt(k)−i,该掩码基于均匀分布的随机变量ξ(k)和patch drop率r来决定是否保留每个块。通过这种方式,随机省略的块有效地破坏了详细外观信息,同时保留了对建模运动动态必要的粗略空间结构。
此外,为了减轻在增量生成过程中先前生成的视频帧可能引入的外观和动态污染,如面部区域和背景的噪声,或唇动和面部表情的微妙失真,论文中在运动帧中加入了高斯噪声,增强了潜在空间中去噪器从污染中恢复的能力。具体做法是在增强的潜在表示上引入高斯噪声,从而得到噪声级别的控制,并通过扩散模型使用这些噪声增强的运动帧作为运动条件输入。
这些噪声增强的运动帧通过去噪U-Net中的交叉注意力机制整合到扩散过程中。在每个去噪步骤t,模型预测噪声分量ϵθ(zt, t, c),其中zt是当前的噪声潜在变量,c代表一组条件输入,包括参考图像的潜在表示zref、音频特征caudio和文本嵌入ctext。通过利用噪声增强的运动帧,模型在捕捉时间动态的同时减轻了累积伪影的影响,这种方法鼓励了主体的外观在整个生成的视频序列中保持稳定。
4.2高分辨率增强
为了提高高分辨率视频生成中的时间连贯性,论文采用了一种码本预测方法,并引入了时间对齐机制。首先,使用固定编码器E对生成的视频帧进行编码,得到潜在表示z,其中N代表帧数,H、W和C分别代表高度、宽度和通道数。每个Transformer块包括一个空间自注意力层和一个时间对齐层。
空间自注意力层的操作如下:给定输入z,通过可学习的投影矩阵WQ、WK和WV计算查询(Qself)、键(Kself)和值(Vself)。然后,使用softmax函数计算空间自注意力层的输出Xself,该输出加上原始输入z以保留原始信息。接着,将隐藏状态Xself重塑为Xtemp,以便在帧间进行时间注意力计算。时间对齐层使用额外的可学习投影矩阵WQ’、WK’和WV’计算查询、键和值,并通过类似的方式计算时间注意力机制的输出Xetemp。最后,将Xetemp重塑回原始维度z。
论文提出了两种提取输入潜在特征的实现方式。第一种方法直接使用扩散模型的潜在特征用于超分辨率模块,这种方法简单,但需要对整个模块进行端到端训练。第二种方法通过扩散模型的解码器和低质量解码器处理潜在特征,只需训练一个轻量级的时间对齐模块。鉴于超分辨率视频数据的稀缺性,第二种方法在有限的训练条件下表现出更优的性能。
通过在Transformer模块中整合空间和时间注意力机制,网络有效捕捉帧内和帧间的依赖关系,从而在高分辨率视频输出中增强时间一致性和视觉保真度。这种方法不仅提升了视频的清晰度,还确保了视频内容在时间上的流畅性和连贯性。
4.3文本提示
为了实现基于文本指令对面部表情和动作的精确调节,论文中在去噪U-Net架构中引入了一种自适应层归一化机制。首先,利用CLIP文本编码器从文本提示中提取文本嵌入etext。然后,这个嵌入通过一个初始化为零的多层感知机(MLP)处理,以产生缩放(γ)和偏移(β)参数:γ, β = MLP(etext)。
自适应层归一化被应用于去噪U-Net中交叉注意力层和音频注意力层之间的中间特征Xcross。具体来说,交叉注意力层的输出Xcross经过层归一化处理:Xnorm = LayerNorm(Xcross),然后与原始特征Xcross结合,通过自适应调整得到Xadapted = γ ⊙ Xnorm + β,其中⊙表示逐元素乘法。这种调整使得去噪过程能够根据文本输入进行条件化,从而在生成的视频帧中实现对合成表情和动作的精细控制。
通过将自适应层归一化整合到去噪U-Net中,模型能够在生成过程中精确地调节面部表情和动作,以响应文本指令。这种方法不仅提高了生成视频的自然度和真实感,而且增强了模型对文本提示的理解和执行能力,使得生成的视频内容更加符合用户的文本描述。此外,这种技术的应用还有助于提升视频生成的个性化和定制化水平,为用户带来更加丰富和满意的视觉体验。
4.4网络结构
论文提出了一种创新的网络架构,用于生成高分辨率且时间连贯的视频。该架构包括ReferenceNet,用于捕捉参考图像的视觉特征,以及一个经过patch drop和高斯噪声增强处理的运动帧模块,以模拟时间动态并减少前帧对外观的污染。去噪U-Net架构负责处理噪声潜在向量,整合音频和文本条件输入,通过交叉注意力层生成与参考图像视觉一致且动态展现细腻表情和唇动的帧。
训练过程分为两个阶段:第一阶段专注于优化空间交叉注意力模块,以提升人像视频生成能力;第二阶段则通过应用数据增强技术,训练模型生成长时视频,同时利用文本提示实现基于文本指令的面部表情和动作的精确调节。此外,超分辨率模型的VAE编码器参数在第二阶段得到优化,以提高码本预测的准确性。
在推理阶段,网络接收参考图像、音频、文本提示以及经过增强处理的运动帧,生成与音频同步的动画帧。随后,高分辨率增强模块进一步提升视频的视觉质量和细节,确保最终输出的4K分辨率视频在清晰度和时间连贯性上达到高标准。这一综合方法不仅提升了视频的自然度和真实感,而且增强了模型对文本提示的理解和执行能力,为用户带来丰富和满意的视觉体验。
五、实验
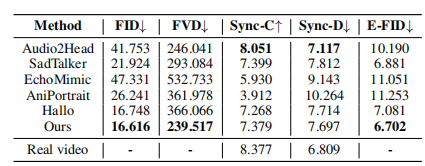
与HDTF数据集上现有的肖像图像动画方法的定量比较
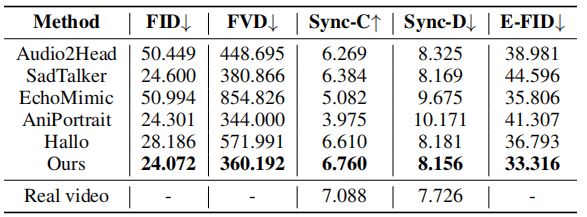
在CelebV数据集上与现有的肖像图像动画方法进行了定量比较
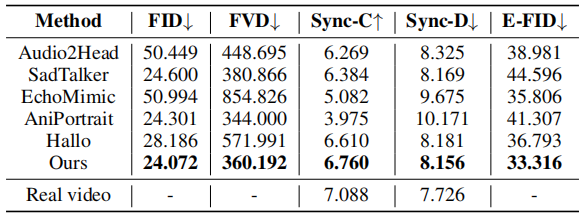
在所提出的“野生”数据集上与现有的方法进行了定量比较
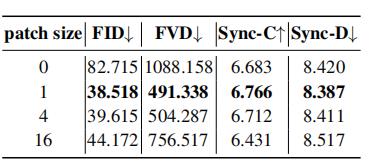
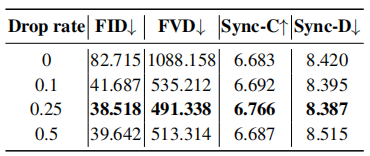
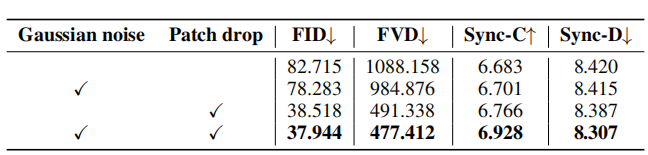
CelebV数据集上patch drop和高斯噪声增强的消蚀研究
 Hallo2在HDTF数据集和现有方法的比较
Hallo2在HDTF数据集和现有方法的比较

不同肖像风格肖像图像动画效果

定性比较了高分辨率增强前后的人像动画效果

参考图像和运动帧的注意地图可视化



















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











