









HTTP入门
WWW的发明(包括一些基本概念以及专有名词)
起步:万维网(World Wide Web)—-WWW。Tim Berners-Lee(后边称为李爵士)在1989年至1992年间,发明了WWW,一种适用于全世界的网络。
主要包含三个概念:
1. URI—-Uniform Resource Identifier,统一资源标识符,俗称网址。
你会不会认为我写错了,网址不应该是URL吗,怎么成URI了?事实上,URI包括URL(Uniform Resource Locator 统一资源定位符)和URN(Uniform Resource Name 统一资源名称)。
URN确定的是一个内容,它明确指出,这个字符串对应的就是这个东西,但是它并不告诉你这个东西在哪里。好比你要找文初阳,我告诉你文初阳住在她家,但是并不告诉你她家在哪里。而URL不是。URL确定的是资源的位置,但是不能确定资源里边对应的是什么东西。比如说你要找文初阳,我告诉你去xx小区xx号楼xx单元xx门牌号找,但是我不知道她现在还在不在那里。但即便如此,我们依旧使用URL。因为我们需要找到这个资源,不论这个资源下载在不在那里。
所以URL的作用呢,就是让你能访问这个页面,但是这个页面会给你一些什么东西不确定。下图是一个URL示例。

其中第二部分www.baidu.com是域名,其中.com(包括有像.cn、.tt)称为顶级域名,也叫一级域名。中间部分的baidu是二级域名,最前边的www则是三级域名。不过很多人都直接忽略掉.com直接将baidu作为一级域名。
第三部分的/s是一个路径,如果上边什么都不写的话默认是根路径/。路径不对应任何文件,即你有/s这个路径,但是不一定有s这个文件。
问号后边的是查询参数,百度搜索引擎自动搜索字符串hello,后边的锚点#5表示搜索结果指向第五条,用于文章内的跳转,像我们在html文档里边写的<a href="#5"></a>。有的URL还会包括端口号比如:80。
2. HTTP—-HyperText Transfer Protocol 超文本传输协议,即两个电脑之间传输内容的协议。http以及后来发展的https(安全的http)都是用来提供一种发布和接收HTML页面的方法。
HTTP/1.1协议中共定义了八种方法来以不同方式操作制定的资源:GET(获取内容)、POST(上传内容)、PUT(整体更新比如5行话替换成一行话)、[PATCH(局部更新)–由RFC 5789指定的方法]、DELETE(删除URI所标识的资源)、HEAD、 TRACE、OPTIONS、CONNECT。
状态码:
1xx 不常用,表示请求已被服务器接收,继续处理。
2xx 表示成功(200—普通的成功,204—post请求创建成功)
3xx 重定向(301—-永久的搬走了,一般在第二部分给一个location:新的地址。302—-临时出去了,过几天还会回来。也会给一个新的location,表示不在这里。304—-这一次的内容跟上一次一样,直接用你上一次访问的内容)
4xx 请求错误(404—未找到资源)
5xx 服务器错误
- HTML—-HyperText Markup Language 超文本标记语言,做一些页面跳转之类的,提高用户体验。
除了这些概念,他还做了一些事,比如————发明了第一个服务器,发明了第一个浏览器以及写出了第一个网站。这个网站到现在依然可以进入。
专有名词:
DNS—–Domain Name System,域名系统。DNS根据我们输入的域名解析出该域名对应的IP。当然,你可以绕过DNS自己指定IP,只需要修改你的hosts文件。
nslookup baidu.com //查看服务器和IP
ping baidu.com //检查网络连接状况电脑端口—-
1. ftp 21
2. https 443
3. 代理服务器端口 1080
4. MySQL服务器 3306
5. http协议 80—–做服务器的话必须把80端口留出来给别人用
浏览器负责发起请求,服务器在80端口接受请求,服务器进行响应返回内容,浏览器下载相应内容然后呈现给用户。http协议是用来指导浏览器和服务器进行沟通的。比如返回404告诉浏览器,你要找的页面不在了请到别处找找吧!
ftp—-File Transfer Protocol,数据传输协议。
请求与响应
首先我们向浏览器发送一个请求:curl -s -v -H "W: xxx" -- "http://www.baidu.com"(可以上这里查询命令含义。-s是不要显示进度条。-v显示请求和响应,否则只显示响应。-H添加请求头。后边的--是把你要请求的网址写在后边)。
可以得到这样的结果。

其中*开头的是注释,>是请求的内容,<是响应的内容。
请求
请求的内容
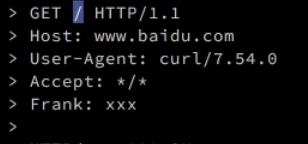
GET–获取, / 根目录内容, HTTP/1.1 协议及其版本号
访问的域名。
用的是什么软件发起的请求。
接受你返回给我的任何内容。
请求头,没有意义。
我们来换成POST请求方式:curl -X POST -s -v -H "W: xxx" -- "https://www.baidu.com"
换成post请求之后得到的请求内容第一行的get变成了post。但是换成post请求之后并不能正确的访问网站。
再换一种curl -X POST -d "1234567890" -s -v -H "W: xxx" -- "https://www.baidu.com" -d表示data,向浏览器传输一个字符串”1234567890”。此时请求会多出两行
Content-Length: 10 //上传10个字节
Content-Type: application/x-www-form-urlencoded //上传的格式注意点:
1. get只用来获取信息,post只用来上传信息。登录的时候必须要提供用户名和密码所以用post。get可以上传数据但是服务器不接收。
2. 请求我们是可以修改的,比如如果你要改第二条host,只需要把上述-H "W: xxx"改成-H "Host: www.qq.com"但是如果你这样的话就是到百度的服务器去找qq的页面,不会给你一个正常的网页的。
3. Content-Type: application/x-www-form-urlencoded前边的application表示这是一个应用数据,x-没有被写入规范的格式,www-万维网,form-表单,urlencoded表示用此形式进行压缩。
请求的格式:
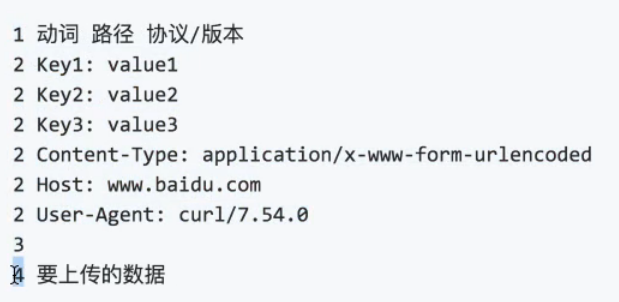
1. 请求包括四部分,其中第四部分可以为空。
2. 第三部分永远是一个回车,用来区分第二部分与第四部分。
3. 第一部分动词 路径 协议/版本,其中动词有GET,POST,PUT,PATCH,DELETE等。这里的路径必须以/开头,包括查询参数但是不包括锚点,锚点是用来给浏览器看然后做页内跳转的,我们传信息给服务器之后会下载整个网页然后用户进行浏览,锚点传给服务器毫无用处。
4. 第二部分key: value,第二部分存放所有你想要告诉服务器的信息,除了要上传的数据(比如用户名和密码)。
5. 第四部分存放要上传的数据,比如用户名和密码,还可以放文件。
用Chrome发请求
1. 打开Chrome浏览器
2. 进入开发者模式,点击network。
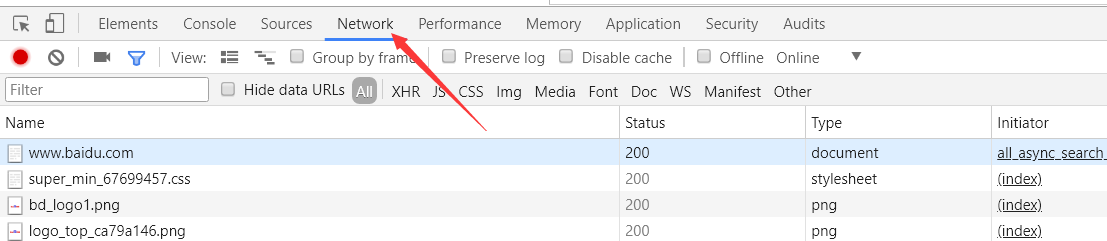
3. 单击第一个请求,进入下图界面。
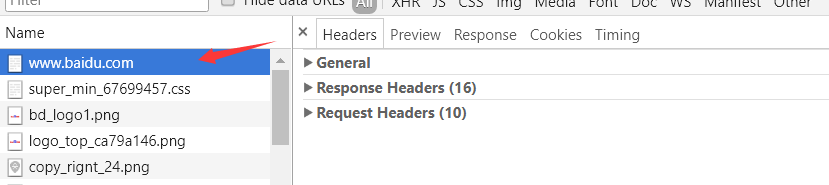
4. 打开Request Headers,点击view source。
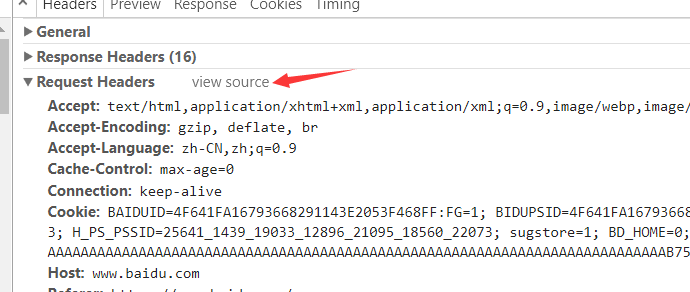
5. 现在你可以看到请求的前三部分了,如果有第四部分,你可以在Form Data里边看见。
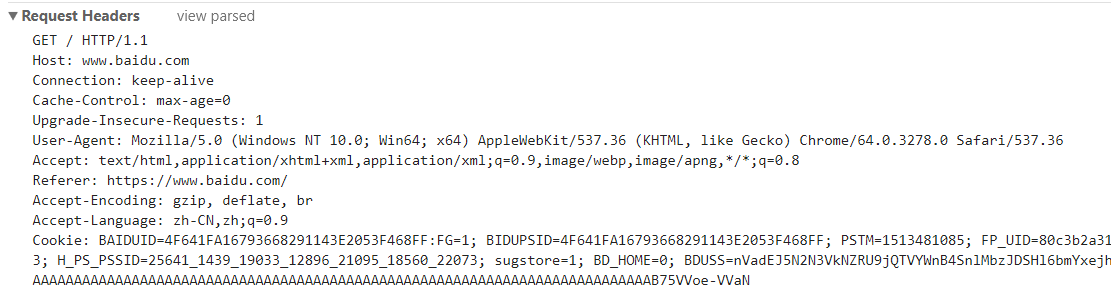
注:如果你想要看到post请求的话请进入一个页面并勾选上Preserve log,因为在登陆的那一瞬间会刷新页面。刷新之后你就看不见post请求了。

响应
请求了之后应该都能得到一个响应。和请求相似,响应也分为四个部分。
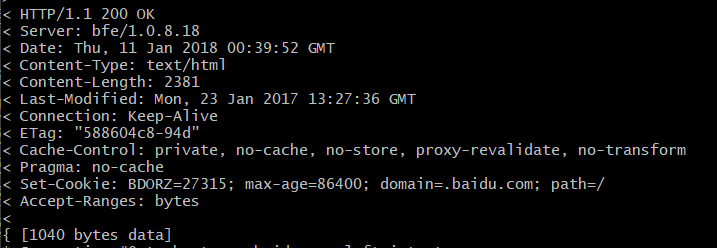
其中第一行:HTTP协议/协议版本号1.1 状态码200 状态解释OK
第二行的bfe指的是百度的前端服务器,后边….标识
date指的是访问时间
响应的格式
1. 响应包括四个部分,其中第四部分可以很长很长。。
2. 第一部分是协议/版本号 状态码 状态解释
3. 第二部分是key: value。其中Content-Length是第四部分的长度,Content-Type标注了第四部分的格式,遵循MIME规范。浏览器按照此格式对第四部分的内容进行解析。
4. 第三部分是回车,用来区分第二部分和第四部分。
5. 第四部分是要下载的内容——HTML网页。
用Chrome查看响应
1. 打开Chrome浏览器
2. 输入网址
3. 单击第一个请求
4. 查看Response Headers,点击view source。你可以看到响应的前两部分。
5. 查看Response或者Preview,可以看到响应的第四部分。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









