









概要
本人看网课大家都使用win+vmware虚拟机配置,用mac的少得可怜甚至于还没开始就结束了…,前两天刚摸索完docker于是直接尝试docker容器化hadoop集群 一开始以为难度跟docker里装redis集群一样简单hhhh,结果一步一个bug!配了两天终于搞定了 现做个学习记录。
整体配置流程分为两部分 docker容器调节+配置文件修改
1.首先确定好linux环境 本人使用centos 这里就有几个小坑!,docker里最新的centos8 yum源本身就有问题 需要替换成阿里源镜像 换好后本人在配置到时间同步时 安装到chrony无法启动 直接寄。后续看到有人说使用centos7.3没这个问题但是这应该是在虚拟机里安装的,docker里要么是7,要么是7.9再就是8 版本。于是本人使用centos7 尝试但依旧无法启动chrony,最终尝试7.9 仍无法启动 但是系统自带ntpd时间同步 于是直接使用它调整系统时间 其实就是往后推8小时 UST 换成CST时区。
确定好centos版本后还需要下载java和hadoop依赖包
下载地址:java 8 | hadoop
这里选择jdk8 和 hadoop3.4.0 本人已开始选的jdk22 结果到最后配置好启动时发现yarn无法启动 查看log报错java无法初始化 没办法重新下载安装一遍。。。
接下来开始正式配置:
第一步--------------------------------------------------------------------------------------------------
拉取镜像:
docker pull centos:7.9.2009
运行镜像生成容器:
docker run -itd --name hadoop01 -p 2201:22 -p 8088:8088 -p 9000:9000 -p 50070:50070 --privileged=true centos:7.9.2009 /usr/sbin/init
运行后查看 docker ps

成功!
需要注意这里 实际上配置的就是第一台hadoop01 端口号必不可少因为后续hdfs yarn启动需要配置对应的端口号访问 如果这里不加端口映射主机无法访问。
-p:表示端口映射,这很重要,可以方便本机在外部访问web网页 需要设置容器和本机的相关端口映射。
-i:表示运行的容器。
-t:表示容器启动后会进入其命令行。加入这两个参数后,容器创建就能登录进去。即分配一个伪终端。
-d: 在run后面加上-d参数,则会创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器,如果只加-i -t两个参数,创建后就会自动进去容器)。
–name :为创建的容器命名。
–privileged:为true时赋予容器内root用户真正的root权限,否则root为普通用户,默认为flase。
/usr/sbin/init: 使容器启动后可以使用systemctl方法。
第二步---------------------------开始安装jdk 和 hadoop------------------------------------------
首先创建一个文件目录mkdir /home/download 把下载的压缩包从主机传入该目录
/xxx/xxx/取决于你宿主机存放压缩包的目录。
docker cp /xxx/xxx/jdk-8u411-linux-aarch64.tar.gz hadoop01:/home/download/
docker cp /xxx/xxx/hadoop-3.4.0.tar.gz hadoop01:/home/download/
传好后开始解压 指定解压路径为/usr/local
cd /home/download/
tar -zxvf jdk-8u411-linux-aarch64.tar.gz -C /usr/local/
解压完成后进入解压路径 把路径名称修改为jdk 后续hadoop的解压路径也修改为hadoop 方便配置环境变量。
cd /usr/local/
mv jdk1.8.0_411/ jdk
接着修改bashrc环境变量文件 在里面配置环境变量这样每次启动环境变量就能自动配置好。
vim /etc/bashrc 进入修改
#在末尾添加以下内容
#jdk environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
source /etc/bashrc 修改完成后运行此命令生效
完成上述这些步骤就可以保存一下 把Hadoop01容器导出为镜像 方便配置另外两台hadoop02 hadoop03
#导出镜像
docker commit -m "first hadoop machine" -a "claem" hadoop01 新镜像名:tag名
#查看镜像列表
docker images
#创建相同容器
docker run -itd --name hadoop02 -p 2202:22 -p 50090:50090 --privileged=true 新镜像名:tag名 /usr/sbin/init
docker run -itd --name hadoop03 -p 2203:22 --privileged=true 新镜像名:tag名 /usr/sbin/init
创建好容器并进入容器后在容器内终端使用hostname xxx可以修改容器root对应的名称,我们在三台机器上分别对应运行。
hostname hadoop01
hostname hadoop02
hostname hadoop03
第三步------------------------配置hadoop前置运行条件----------------------------------------
首先要确保三台hadoop服务器在同一网络内,这就需要我们把三台服务器所在的容器连接到同一网络,在docker内创建容器时如果不使用-net的话默认加入bridge桥接网络 所以我们需要在docker里单独创建一个桥接网络让三台容器加入即可
#查看docker 存在的网段
docker network ls
#创建名为bigdata的新网段
docker network create hadoop-cluster-1
# 三台容器连入bigdata网段
docker network connect hadoop-cluster-1 hadoop01
docker network connect hadoop-cluster-1 hadoop02
docker network connect hadoop-cluster-1 hadoop03
#断开三台容器与bridge的连接
docker network disconnect bridge hadoop01
docker network disconnect bridge hadoop02
docker network disconnect bridge hadoop03
这样三台容器间就可以相互ping通 但是宿主机还不能和容器间ping通
这里可以参考我上一片文章Mac宿主机无法ping通docker容器这里就不做过多讲述啦。
接下来对每台机器配置SSH免密登陆
yum -y install passwd openssh-server openssh-clients
systemctl status sshd
systemctl start sshd
systemctl enable sshd #让sshd服务开机启动
ss -lnt #检查22端口号是否开通
注意 这里如果ss -lnt报错 bash: ss: command not found 说明没有下载ss对应的命令包,使用下方命令安装即可。ps:centos8自带了但是7没有带。。。
sudo yum install iproute # iproute包包含了ss命令及其他网络工具
接下来在三台容器里分别配置密码 嫌麻烦统一配置000000
passwd root
三台机器都安装好后 每台机器上都修改hosts文件 这样三台hadoop服务器的ip每台容器都存放一遍 后面可以直接识别。
vim /etc/hosts
#在文件后添加
172.19.0.2 hadoop01
172.19.0.3 hadoop02
172.19.0.4 hadoop03
设置免密登陆
ssh-keygen -t rsa #连续回车直到完成
[root@hadoop01 ~] cd .ssh/
[root@hadoop01 ~] ls
每台容器上都拷贝一下三台hadoop服务器的密匙
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
最后到了最坑的地方 三台机器的时间同步,这里我直接选择修改容器内部时间,改的和宿主机一样就可以了,三台hadoop服务器同步修改。
# 进入容器
docker exec -it <container_id> bash
# 执行
ln -snf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo "Asia/Shanghai" > /etc/timezone
第四步-------------------------配置hadoop----------------------------------------------------------
解压hadoop3.4.0压缩包 还是老地方。
tar -zxvf hadoop-3.4.0.tar.gz -C /usr/local
解压好后记得修改解压目录hadoop3.4.0 —> hadoop 然后配置环境变量
cd /etc/profile.d/ 进入该目录
touch my_env.sh 创建hadoop环境变量配置文件
vim my_env.sh 进入修改
#在其末尾添加
#HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#让修改后的文件生效
source /etc/profile
#测试是否成功 查看版本
hadoop version
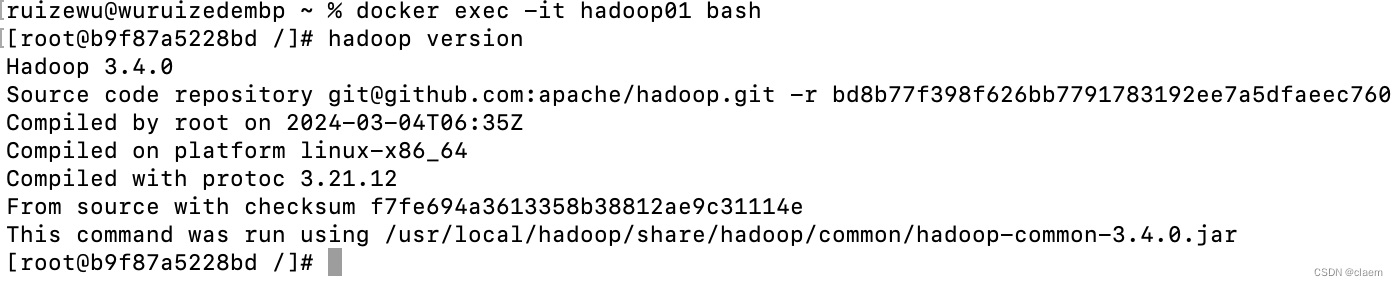
成功后给另外两台容器上分发hadoop文件和刚刚创建的环境变量文件
cd /usr/local/
scp -r hadoop/ hadoop02:$PWD
scp -r hadoop/ hadoop03:$PWD
scp /etc/profile hadoop02:/etc/
scp /etc/profile hadoop03:/etc/
source /etc/profile #在hadoop02上执行
source /etc/profile #在hadoop03上执行
my_env.sh需要创建一个脚本文件来分发
首先找到全局环境变量 使用echo $PATH查找到 /usr/local/bin
cd /usr/local/bin
vim xsync
#编写如下脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
for host in hadoop01 hadoop02 hadoop03
do
echo ==================== $host ====================
for file in $@
do
if [ -e $file ]
then
pdir=$(cd -P $(dirname $file); pwd)
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
#修改脚本xysnc 赋予执行权限
chmod +x xsync
#测试脚本
xsync /usr/local/bin
#将脚本复制/bin目录,以便全局调用
cp xsync /bin/
#同步环境变量配置 进入./bin目录下执行
xsync /etc/profile.d/my_env.sh
#最后hadoop01 hadoop02 hadoop03 都执行
source /etc/profile
到这里可以说完成65%了,接下来在三台服务器上我们需要做的就是修改hadoop的配置文件,例如指定 namenode在哪台服务器上 secondnamenode在哪台服务器,resourcemanager/nodemanager又在哪台服务器,修改配置文件来确定这些细节方面 最后能运行起来就成功!
修改hadoop配置文件
要实现完全分布式的配置,需要配置以下文件:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
在Hadoop安装完成后,会在$HADOOP_HOME/share路径下,有若干个*-default.xml文件,这些文件中记录了默认的配置信息。同时,在代码中,我们也可以设置Hadoop的配置信息。 这些位置配置的Hadoop,优先级为: 代码设置 > *-site.xml > *-default.xml
本次部署的集群规划如下:
| Node | Applications |
|---|---|
| hadoop01 | NameNode&DataNode&ResourceManager&NodeManager |
| hadoop02 | SecondaryNameNode&DataNode&NodeManager |
| hadoop03 | DataNode&NodeManager |
1.core-site.xml
# cd $HADOOP_HOME/etc/hadoop/
# vim core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
属性解释:
1.fs.defaultFS:
HDFS对外提供服务的主机及端口号;
端口也可以省略不写。
2.hadoop.tmp.dir:
指定的HDFS文件存储的目录;
2.hdfs-site.xml
# cd $HADOOP_HOME/etc/hadoop/
# vim hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:50070</value>
</property>
</configuration>
1.dfs.namenode.name.dir:
fsimage存储的位置
2.dfs.datanode.data.dir:
块的存储位置
3.dfs.replication:
HDFS为了保证属性不丢失,会保存块的副本
4.dfs.blocksize:
块大小,在hadoop1.x版本中为64M,在hadoop2.x的版本汇总默认128M
5.dfs.namenode.secondary.http-address:
指定secondarynamenode的节点服务器位置
6.dfs.namenode.http-address:
webui查看时的地址端口
3.mapred-site.xml
# cp mapred-site.xml.template mapred-site.xml docker里没有该文件就不执行该命令
# vim mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
4.yarn-site.xml
# vim yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>
5.hadoop-env.sh
# 配置hadoop运行的jdk环境路径
vim hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
6.yarn-env.sh
# 配置yarn运行的jdk环境路径
vim yarn-site.sh
# some Java parameters
export JAVA_HOME=/usr/local/jdk
7.workers
# hadoop3.0之前的版本叫 slaves
vim workers
hadoop01
hadoop02
hadoop03
分发配置文件 让三台hadoop服务器配置文件都更新成修改的
cd $HADOOP_HOME/etc/
scp -r hadoop/ hadoop02:$PWD
scp -r hadoop/ hadoop03:$PWD
格式化 在hadoop01服务器上运行 该服务器是主服务器 (master)
PS:如果之前格式化过集群,需要删除上次配置的hadoop.tmp.dir属性对应位置的tmp文件夹,hadoop.tmp.dir属性值见core-site.xml文件
hdfs namenode -format
格式化信息解读:
- 生成一个集群唯一标识符:clusterid
- 生成一个块池唯一标识符:blockPoolId
- 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录 - 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
- 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。
启动集群
-
启动脚本
– start-dfs.sh :用于启动hdfs集群的脚本
– start-yarn.sh :用于启动yarn守护进程
– start-all.sh :用于启动hdfs和yarn -
关闭脚本
– stop-dfs.sh :用于关闭hdfs集群的脚本
– stop-yarn.sh :用于关闭yarn守护进程
– stop-all.sh :用于关闭hdfs和yarn -
单个守护进程脚本
– hadoop-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
– hadoop-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
例:
hadoop-daemon.sh [start|stop] [namenode|datanode|secondarynamenode]– yarn-daemons.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
– yarn-daemon.sh :用于单独启动或关闭hdfs的某一个守护进程的脚本
例:
yarn-daemon.sh [start|stop] [resourcemanager|nodemanager]
注意! 如果哪台机器的相关守护进程没有开启,那么,就查看哪台机器上的守护进程对应的日志log文件,注意,启动脚本运行时提醒的日志后缀是*.out,而我们查看的是*.log文件。此文件的位置:${HADOOP_HOME}/logs/里
查看web端 hdfs 和 yarn
HDFS: http://hadoop01的容器ip:50070

YARN: http://hadoop01的容器ip:8088
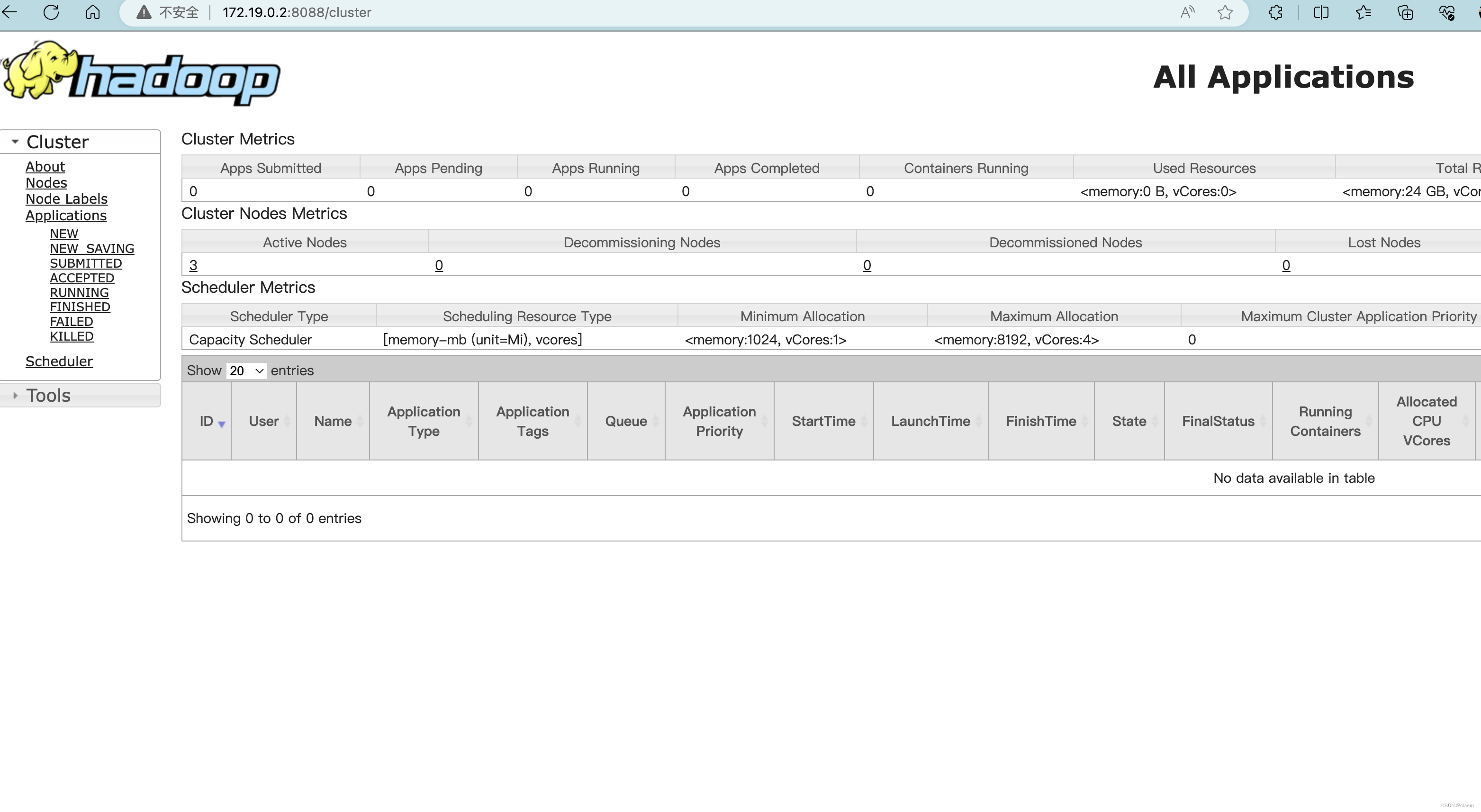
成功!!!















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









