






一、简介#
NodeManager(NM)中的状态机分为三类:Application、Container 和 LocalizedResource,它们均直接或者间接参与维护一个应用程序的生命周期。
- 当 NM 收到某个 Application 的第一个 container 启动命令时,它会创建一个「Application状态机」来跟踪该应用程序在该节点的状态;
- 每个container都有一个独立的「container状态机」;
- Application 运行所需资源(jar,文件等)的下载过程则由「LocalizedResource状态机」维护和跟踪。
二、三类状态机#
一)Application 状态机#
NM 上的 Application 维护的信息是 RM 端 Application 信息的一个子集,这有助于统一管理节点上同一个 Application 的所有 Container(例如记录每个 Application 在该节点上运行的 Container 列表,以及杀死一个 Application 的所有 Container 等)。
实现这一功能的类是 nodemanager/containermanager/application/ApplicationImpl,它维护了一个 Application 状态机。需要注意的是,NM 上 Application 的生命周期与 RM 上 Application 的生命周期是一致的。
// 截取 ApplicationImpl 中一部分状态机的代码
private static StateMachineFactory<ApplicationImpl, ApplicationState,
ApplicationEventType, ApplicationEvent> stateMachineFactory =
new StateMachineFactory<ApplicationImpl, ApplicationState,
ApplicationEventType, ApplicationEvent>(ApplicationState.NEW)
// Transitions from NEW state
.addTransition(ApplicationState.NEW, ApplicationState.INITING,
ApplicationEventType.INIT_APPLICATION, new AppInitTransition())
.addTransition(ApplicationState.NEW, ApplicationState.NEW,
ApplicationEventType.INIT_CONTAINER,
INIT_CONTAINER_TRANSITION)
// Transitions from INITING state
.addTransition(ApplicationState.INITING, ApplicationState.INITING,
ApplicationEventType.INIT_CONTAINER,
INIT_CONTAINER_TRANSITION)
.addTransition(ApplicationState.INITING,
EnumSet.of(ApplicationState.FINISHING_CONTAINERS_WAIT,
ApplicationState.APPLICATION_RESOURCES_CLEANINGUP),
ApplicationEventType.FINISH_APPLICATION,
new AppFinishTriggeredTransition())
.addTransition(ApplicationState.INITING, ApplicationState.INITING,
ApplicationEventType.APPLICATION_CONTAINER_FINISHED,
CONTAINER_DONE_TRANSITION)
.addTransition(ApplicationState.INITING, ApplicationState.INITING,
ApplicationEventType.APPLICATION_LOG_HANDLING_INITED,
new AppLogInitDoneTransition())
.addTransition(ApplicationState.INITING, ApplicationState.INITING,
ApplicationEventType.APPLICATION_LOG_HANDLING_FAILED,
new AppLogInitFailTransition())
.addTransition(ApplicationState.INITING, ApplicationState.RUNNING,
ApplicationEventType.APPLICATION_INITED,
new AppInitDoneTransition())
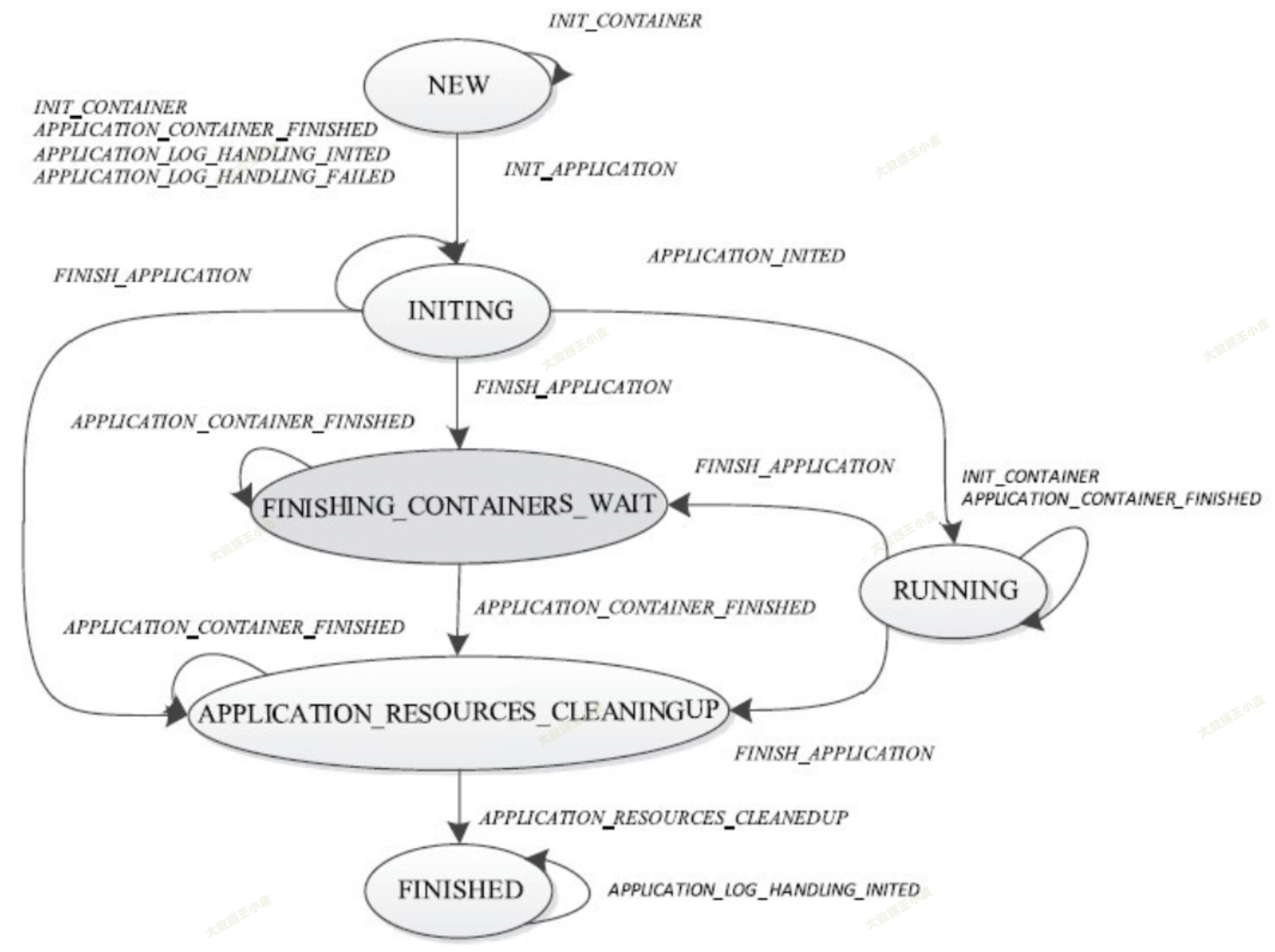
下面进行具体介绍:
1、基本状态#
- NEW:状态机初始状态,每个 Application 对应一个状态机,而每个状态机的初始状态均为 NEW。
- INITING:Application 处于初始化状态,即创建日志目录和工作目录,创建 AppLogAggregator 对象等。
- FINISHING_CONTAINERS_WAIT:等待回收 Container 占用的资源时所处的状态。当 Application 状态机收到 FINISH_APPLICATION 事件后,会向各个 Container 发送 KILL 命令以回收它们占用的资源。
- APPLICATION_RESOURCES_CLEANINGUP:Application 的所有 Container 占用的资源被收回后,它将处于 APPLICATION_RESOURCES_CLEANINGUP 状态。
- RUNNING:Application 初始化(完成创建日志目录和工作目录,创建 AppLog-Aggregator 等工作)完成后,将进入 RUNNING 状态。
- FINISHED:Application 将占用的各种文件资源发送给文件删除服务 DeletionService(该服务会异步删除文件,避免产生性能问题)后,进入 FINISHED 状态,表示运行完成。
2、基本事件#
- INIT_APPLICATION:NM 收到来自某个 Application 的第一个 Container 后,会触发一个 INIT_APPLICATION 事件,同时使 Application 状态由初始状态 NEW 转换为 INITING。
- APPLICATION_INITED:Application 初始化完成后将触发一个 APPLICATION_INITED 事件。Application 初始化主要工作是初始化各类必需的服务组件(比如日志记录组件 LogHandler、资源状态追踪组件
LocalResourcesTrackerImpl等),供后续 Container 使用,通常由 Application 的第一个 Container 完成。 - FINISH_APPLICATION:NodeManager 收到 ResourceManager 发送的待清理的 Application 列表后,会向这些 Application 发送一个 FINISH_APPLICATION 事件
- APPLICATION_CONTAINER_FINISHED:该 Application 的一个 Container 运行完成(可能运行失败,也可能运行成功)后将触发一个 APPLICATION_CONTAINER_FINISHED 事件。
- APPLICATION_RESOURCES_CLEANEDUP:Application 所有 Container 占用的资源被清理完成(比如占用的临时目录)后将触发一个 APPLICATION_RESOURCES_CLEANEDUP 事件
- INIT_CONTAINER:NodeManager 收到 ApplicationMaster 通过 RPC 函数
ContainerManagementProtocol#startContainer发送的启动 Container 的请求后,会触发一个 INIT_CONTAINER 事件。
二)Container 状态机#
Container 状态机维护一个 container 运行的全部状态,包含 11 个状态和 10 个事件,实现类是 nodemanager/containermanager/container/ContainerImpl.java。下面是状态转化的图:
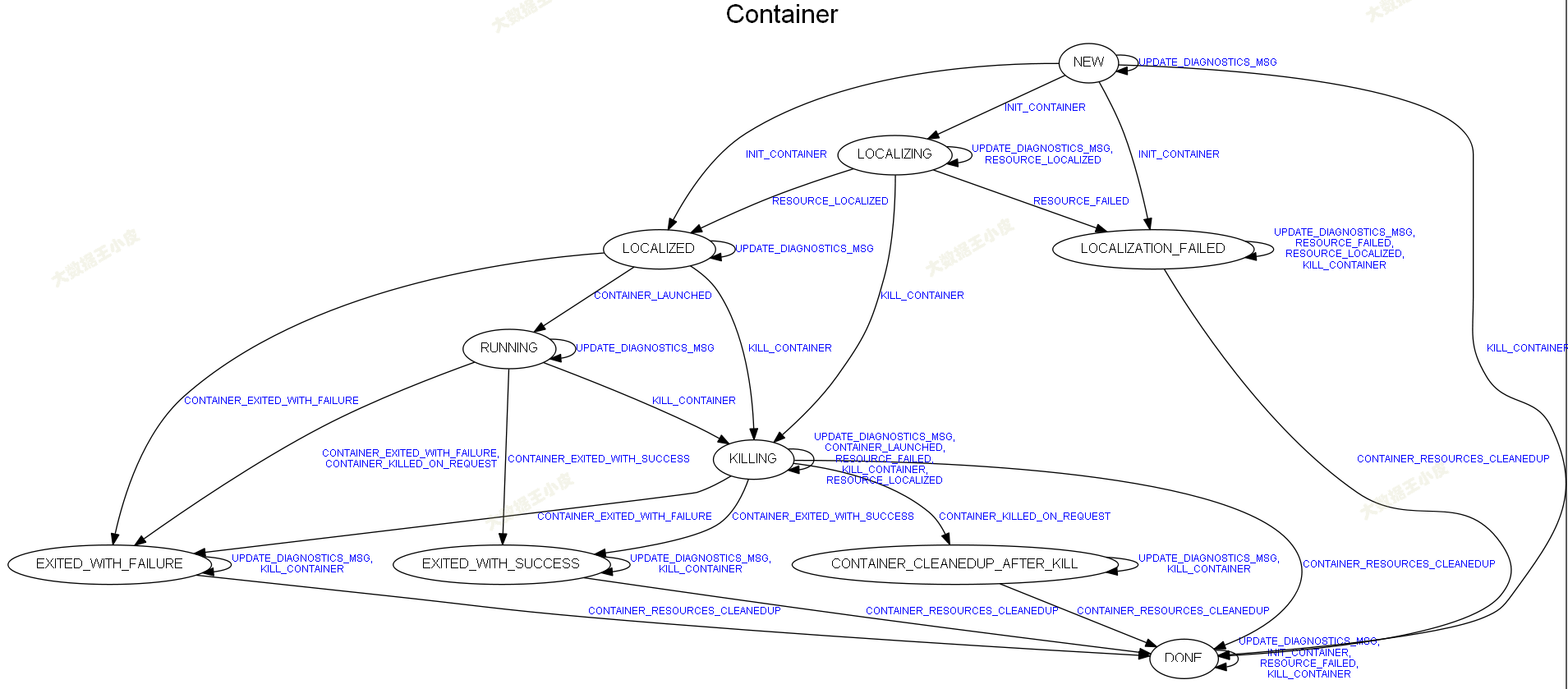
1、基本状态#
- NEW:状态机初始状态,每个 Container 对应一个状态机,而每个状态机的初始状态均为 NEW。
- LOCALIZING:Container 运行之前,需从 HDFS 上下载依赖的文件资源,Container 正在下载文件时所处的状态称为 LOCALIZING。
- LOCALIZED:运行 Container 所需的文件资源已经全部下载(缓存)到本地后,将进入该状态。
- LOCALIZATION_FAILED:由于文件损坏、磁盘损坏等原因,Container 下载资源失败(这将导致依赖该资源的所有 Container 运行失败),此时 Container 所处的状态为 LOCALIZATION_FAILED。
- RUNNING:ContainerLaunch 组件为 Container 创建工作目录和构造执行脚本,并通知 ContainerExecutor 执行该脚本,使得 Container 进入 RUNNING 状态。
- EXITED_WITH_SUCCESS:ContainerExecutor 启动 Container 执行脚本后,阻塞直到脚本正常退出执行,此时 Container 将处于 EXITED_WITH_SUCCESS 状态。
- DONE:Container 正常退出执行后,首先需清理它占用的各种临时文件,一旦清理完成后,Container 状态将转移为完成状态 DONE。
- KILLING:Container 正在被杀死时所处的状态,通常是由于内存超量使用被监控线程杀死,或者 ResourceManager 和 ApplicationMaster 主动杀死 Container。
- EXITED_WITH_FAILURE:Container 在执行过程中异常退出后所处的状态,通常是由于 Container 内部原因导致,比如程序 bug、硬件故障等。
2、基本事件#
- INIT_CONTAINER:NodeManager 收到来自 ApplicationMaster 的启动 Container 的请求,则会创建一个 Container 对象,并触发一个 INIT_CONTAINER 事件,使 Container 状态由初始状态 NEW 转换为 LOCALIZING。
- RESOURCE_LOCALIZED:Container 成功从 HDFS 下载一种资源到本地(缓存),会触发一个 RESOURCE_LOCALIZED 事件。注意,一个 Container 可能需要下载多种资源,因此,该事件可能使 Container 维持在 LOCALIZING 状态或者进入新状态 LOCALIZED(所有资源均下载完成)。
- CONTAINER_LAUNCHED:ContainerLaunch 调用函数 ContainerExecutor#launchContainer 成功启动后,会触发一个 CONTAINER_LAUNCHED 事件,使得 Container 从 LOCALIZED 状态转换为 CONTAINER_LAUNCHED 状态。需要注意的,由于函数 ContainerExecutor#launchContainer 是阻塞的,所以它要等到 Container 退出执行后才会退出,因此,该事件将在该函数调用之后发出。
- CONTAINER_EXITED_WITH_SUCCESS:Container 正常退出(执行 Container 实际上是执行一个 Shell 脚本,正常结束运行后会返回 0),会触发一个 CONTAINER_EXITED_WITH_SUCCESS 事件。
- CONTAINER_RESOURCES_CLEANEDUP:NodeManager 清理完成 Container 使用的各种临时目录(主要是删除分布式缓存中的临时数据),此时会触发一个 CONTAINER_RESOURCES_CLEANEDUP 事件,使得 Container 从 EXITED_WITH_SUCCESS 状态转换为 DONE 状态。
- RESOURCE_FAILED:Container 本地化过程中抛出异常,会触发一个 RESOURCE_FAILED 事件,导致 Container 失败。
- KILL_CONTAINER:在多种场景下会触发产生 KILL_CONTAINER 事件,包括 ResourceManager 要求 NodeManager 杀死一个 Container;Container 使用的内存量超过约定值,被监控线程杀死;ApplicationMaster 要求 NodeManager 杀死一个 Container(通过 RPC 函数 ContainerManagementProtocol#stopContainer)。
- CONTAINER_EXITED_WITH_FAILURE:Container 异常退出(运行过程中抛出 Throwable 异常)时,会触发一个 CONTAINER_EXITED_WITH_FAILURE 事件。
三)LocalizedResource 状态机#
下载是在从 init 状态转移到 downloading 状态时,会发一个 REQUEST_RESOURCE_LOCALIZATION 事件。这个事件是会发给 ResourceLocalizationService,ResourceLocalizationService 根据资源的类型和可见性确定路径并下载他。下载是异步的(并且每个 application 对应着自己的下载线程),每个下载会对应一个 callable 的 FSDownload。
状态机如下图所示,非常简单,不再具体介绍。
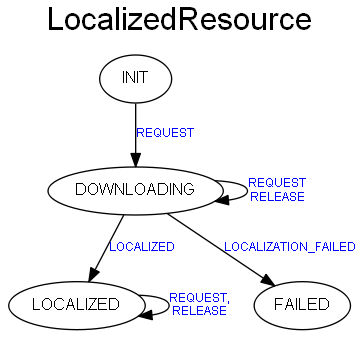
三、小结#
本篇文章对 NodeManager 中三类状态机进行了介绍,其主要都是维护一个应用程序的生命周期。无需强行记忆,知道有这三类状态机,遇到问题再对应查看即可。
















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











