







 本文详细探讨了多线程环境下volatile关键字的作用,包括为何多线程会导致线程不安全,内存屏障、JMM(Java内存模型)的概念,以及volatile如何确保可见性和防止重排序。同时,解释了内存屏障的使用,volatile的局限性,以及happens-before原则在并发编程中的重要性。
本文详细探讨了多线程环境下volatile关键字的作用,包括为何多线程会导致线程不安全,内存屏障、JMM(Java内存模型)的概念,以及volatile如何确保可见性和防止重排序。同时,解释了内存屏障的使用,volatile的局限性,以及happens-before原则在并发编程中的重要性。
为什么多线程会造成线程不安全
cpu缓存
由于磁盘io、内存io耗费时间比较多,为了提高cpu利用率,做了3级cpu缓存,L1、L2、L3

- 这就会导致多核cpu中操作不同数据,对其它cpu中内容是不可见的
- 比如cpu1从内存中读取了i=1,进行i+1操作
- 当这个操作的内容还没有放到内存中时,cpu2读取的i还是等于1
于是cpu为了解决这个问题引入了总线锁和缓存锁

- 总线锁:锁内存与cpu之间交互的过程,粗粒度锁,一旦锁住整个内存都被锁住
- 缓存锁:只锁住cpu操作的这个缓存
缓存行
这里还要提一下缓存行的概念:缓存是一行一行的,操作系统每次取数据都是一段一段的去拿的,64位的操作系统,每次是64个字节,当去int i和j在一行时,那么每次加缓存锁都会讲i和j都锁住了,于是这里就出现了对齐补充,让每个变量都是自己一行从而解决缓存锁的问题
总线锁效率太低,而缓存锁,还是需要将缓存同步到内存中,于是诞生了缓存一致性协议(MESI)
- M(Modify[ˈmɒdɪfaɪ]) 表示共享数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的数据和主内存中的数据不一致
- E(Exclusive[ɪkˈskluːsɪv]) 表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
- S(Shared[ʃerd]) 表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存数据一致
- I(Invalid[ˈɪnvəlɪd]) 表示缓存已经失效
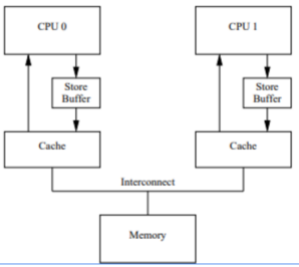
为了执行这个协议于是创建了storebuffer,在完成修改后调用异步的storebuff去完成主内存的信息修改
为什么要是异步的,还是为了提高cpu的利用率,但是异步还是会产生不可见问题
重排序
重排序指的是从源代码到编译器重拍序,指令从排序到cpu重排序,来提高运行速度
x=0;y=0;
a=0;b=0;
Thread t1=new Thread(()->{
a=1;x=b;
//重排序后x=b;a=1;
});
Thread t2=new Thread(()->{
b=1;y=a;
//y=a;b=1;
});
/**
* 可能的结果:
* 1和1
* 0和1
* 1和0
* ----
* 0和0
*/
内存屏障
为了解决这种不可见的安全问题,从硬件层面提供了内存屏障
相当于在操作的前后取消重排序,并且每次操作完都要立马写入内存,且读取的时候重新从内存中读取最新的值
JMM
jmm是软件层面的屏障通过封装后去调用硬件的屏障
有3种:loadload,storeload,fullload:全屏障
volatile是怎么解决可见性和重排序的
通过调用封装调用fullload,来完成内容的可见性
但是他只能解决可见性不能解决原子性
比如线程A和线程B同时读取了i的值为1,这时线程A修改i为1,线程B修改i为2还是会出现问题
可见性到底是什么,原子性呢
原子性:指的是操作不可分割,要么都成功要都失败
可见性:指的是操作对外可以看见,但是不能干预
有序性:程序执行的顺序按照代码的先后顺序执行
happensbefore原则
1.程序运行顺序规则
单一线程下,运行结果不能改变
2.volatile规则
对于 volatile 修饰的变量的写的操作, 一定 happen-before 后续对于 volatile 变量的读操作;
3.传递性规则,
如果 1 happens-before 2; 3happensbefore 4; 那么传递性规则表示: 1 happens-before 4;
4.join规则
如果线程 A 执行操作ThreadB.join()并成功返回,
那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join()操作成功返回
5.start原则
如果线程 A 执行操作 ThreadB.start(),
那么线 程 A 的 ThreadB.start()操作 happens-before 线程 B 中 的任意操作
6.监视器锁的规则
对一个锁的解锁,happens-before 于 随后对这个锁的加锁















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









