







目录
SQL Server中的模糊查询LIKE
在SQL Server中,当我们想实现模糊查询时,可能我们首先想到的是使用LIKE语句,其次是使用全文搜索(即Full-Text Search),如下所示是通过LIKE语句对表Person.EmailAddress中的EmailAddress字段进行模糊查询:
--使用微软官方示例数据库AdventureWorks2008R2
SELECT *
FROM Person.EmailAddress
WHERE EmailAddress LIKE '%mary%'通常,当表的总记录达数十万时,LIKE的执行效率将明显下降。那么我们是否真的正确认识LIKE语句,本文将描述如何正确使用SQL Server中的LIKE语句进行模糊查询。
LIKE的匹配格式及正确使用
虽然在SQL Server中LIKE语句可使用如下4种通配符:
%
_
[]
[^]
但实际总结后,LIKE语句总共如下4种格式:
%HyperWang%
%HyperWang
HyperWang%
Hyper%Wang
注意通配符%的位置。
为了更好的理解这4种匹配格式,我们修改上述sql代码,并在执行后查看IO统计信息与实际执行计划:
--检查表中的索引情况
sp_helpindex [Person.EmailAddress]
-----------------------------------------------------------| index_name | index_description | index_keys |
|---|---|---|
| IX_EmailAddress_EmailAddress | nonclustered located on PRIMARY | EmailAddress |
| PK_EmailAddress_BusinessEntityID_EmailAddressID | clustered, unique, primary key located on PRIMARY | BusinessEntityID, EmailAddressID |
表格所示,表Person.EmailAddress中的EmailAddress建有非聚集索引。执行修改后的sql代码:
--匹配mary在中间的记录
SELECT EmailAddress
FROM Person.EmailAddress
WHERE EmailAddress LIKE '%mary%'
--匹配mary在尾部的记录
SELECT EmailAddress
FROM Person.EmailAddress
WHERE EmailAddress LIKE '%mary'
--匹配以mary开头的记录
SELECT EmailAddress
FROM Person.EmailAddress
WHERE EmailAddress LIKE 'mary%'
--匹配以ma开头,ry结尾的记录
SELECT EmailAddress
FROM Person.EmailAddress
WHERE EmailAddress LIKE 'ma%ry'其中以格式mary%的效率最好,以index seek方式使用非聚集索引IX_EmailAddress_EmailAddress(如下图所示)。
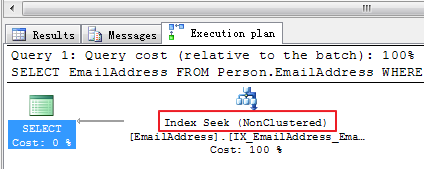
(43 row(s) affected)
表 ‘EmailAddress’。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
而%mary与%mary%的效率最差,IO开销最高,且以index scan方式使用非聚集索引
(0 row(s) affected)
表 ‘EmailAddress’。扫描计数 1,逻辑读取 186 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
因此当我们使用LIKE进行模糊查询时,应尽量使用mary%格式,避免%mary%的格式,同时建立有效的非聚集索引。
参考资料
LIKE (Transact-SQL)
https://msdn.microsoft.com/en-us/library/ms179859(v=sql.105).aspxImproving SQL Server Performance
https://msdn.microsoft.com/en-us/library/ff647793.aspx















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









