






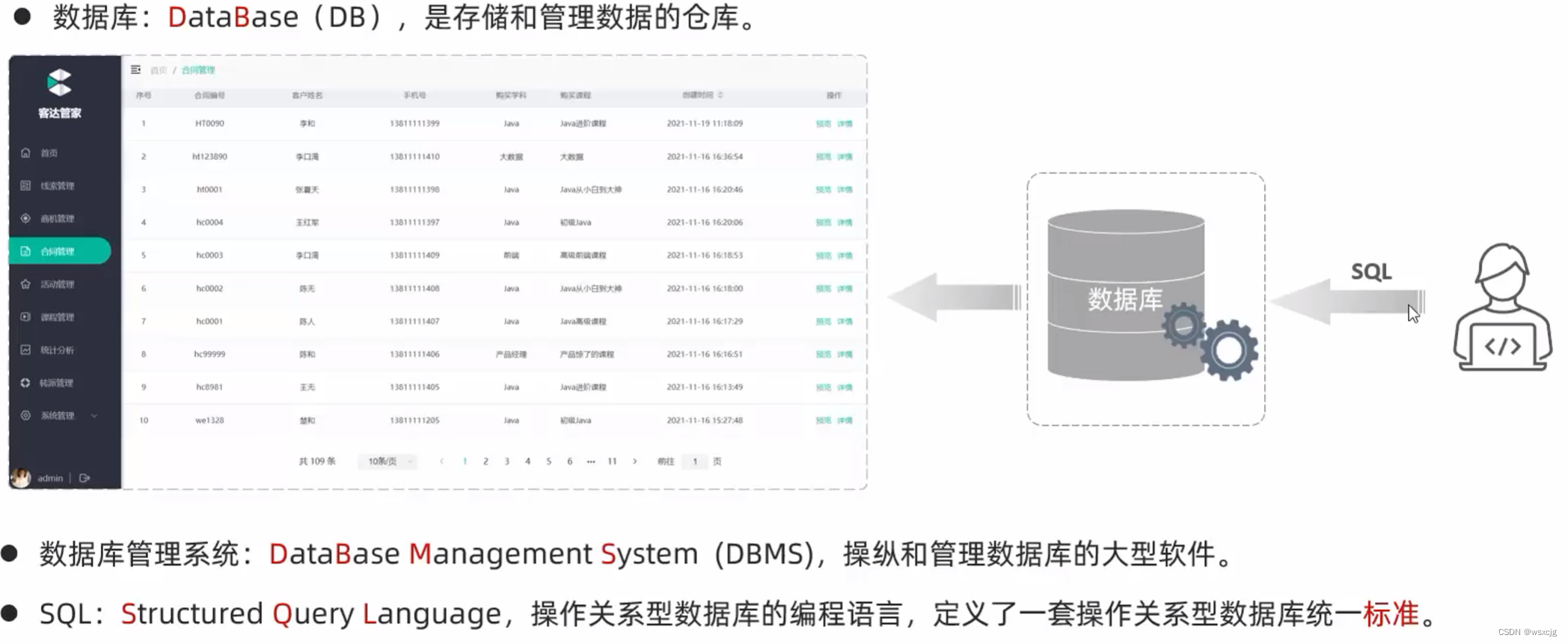
数据库:
MySQL数据模型:
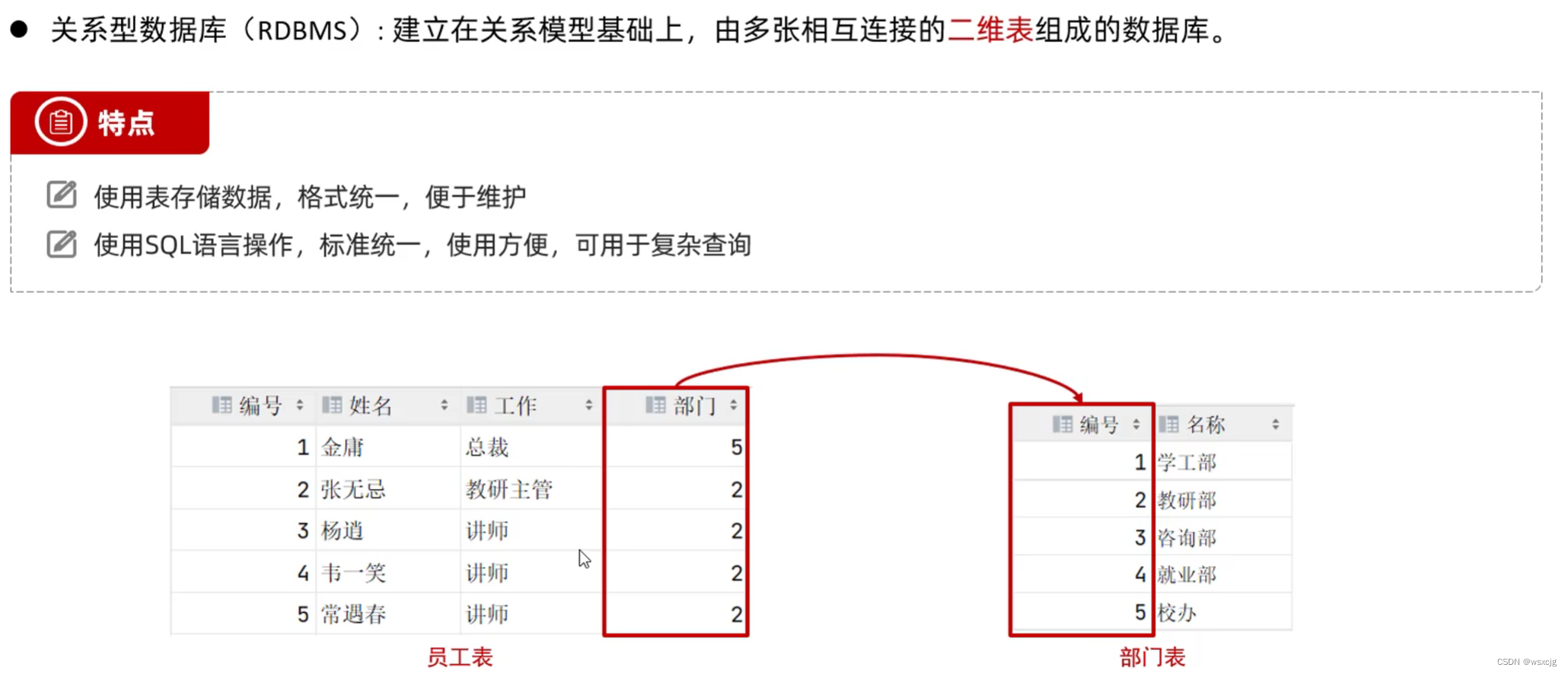
MySQL是关系型数据库。
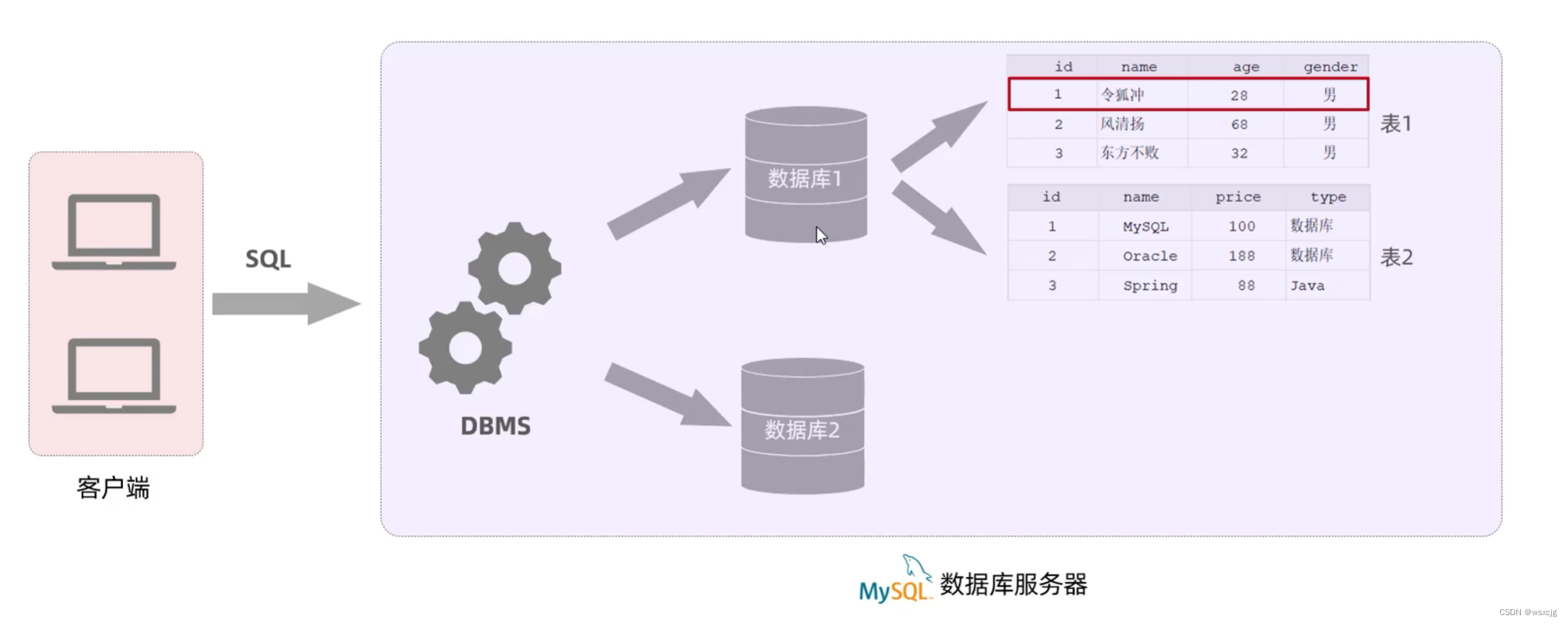
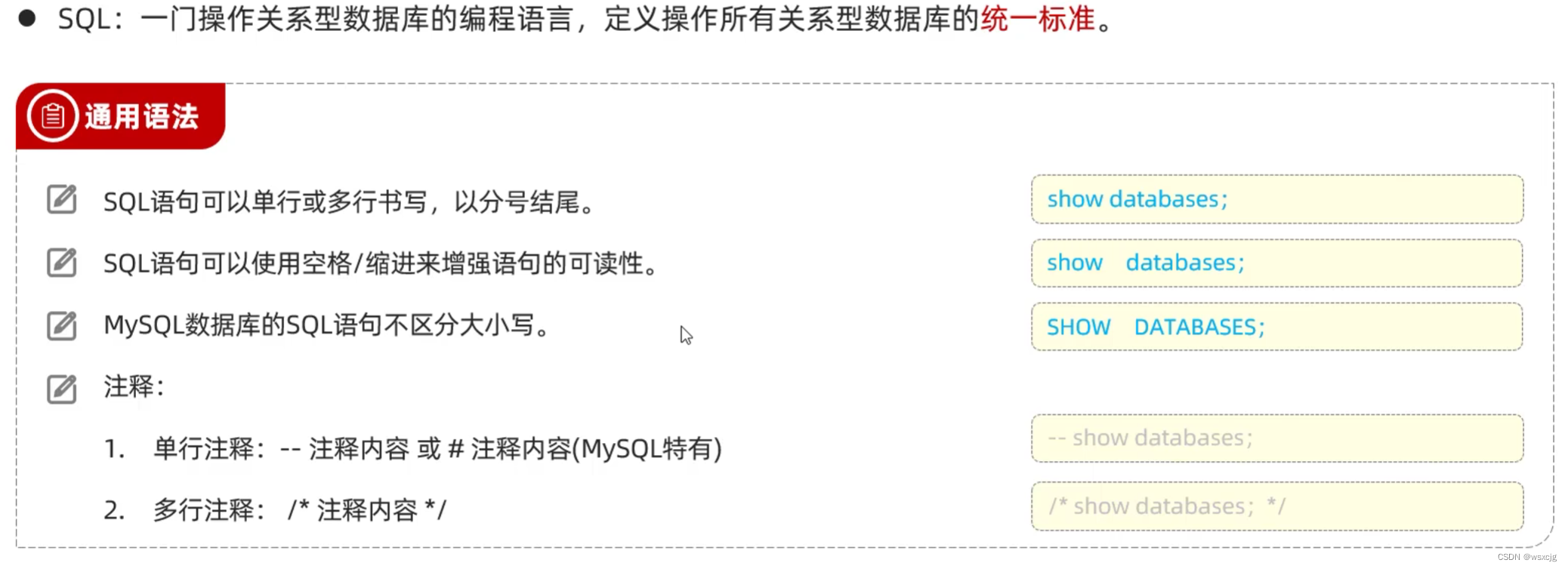
SQL:
简介
分类:
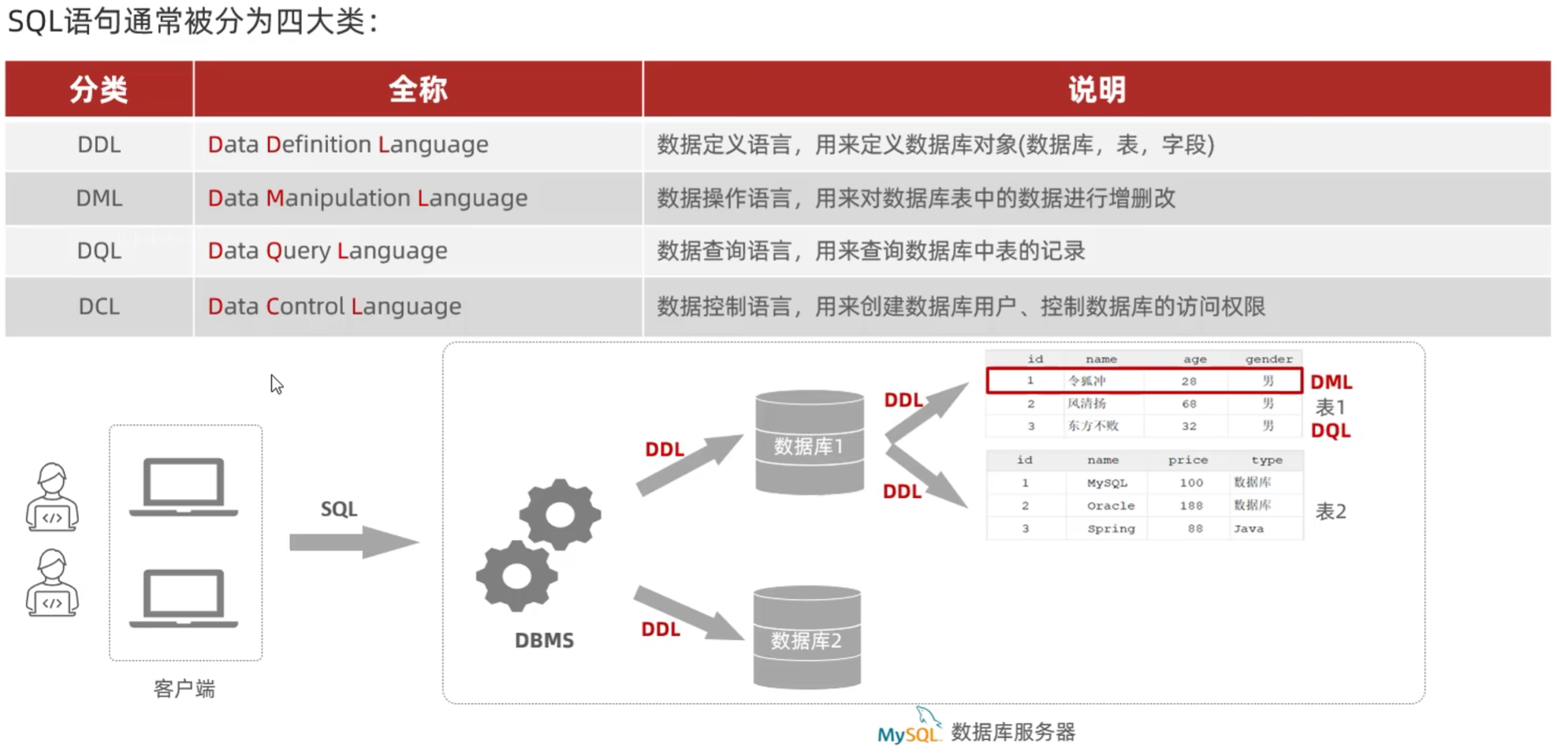
数据库设计-DDL
对数据库操作:

表操作:
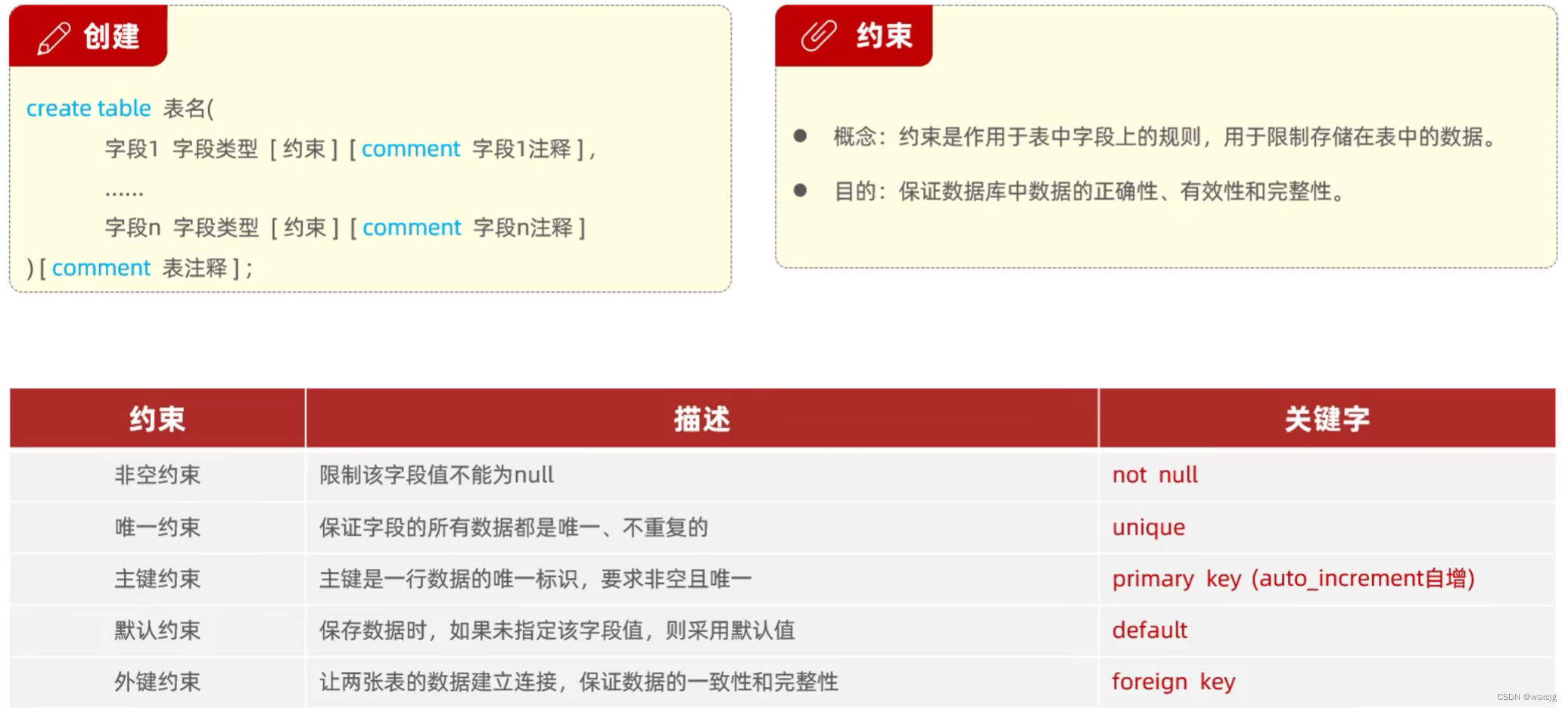



小练习:
创建下表
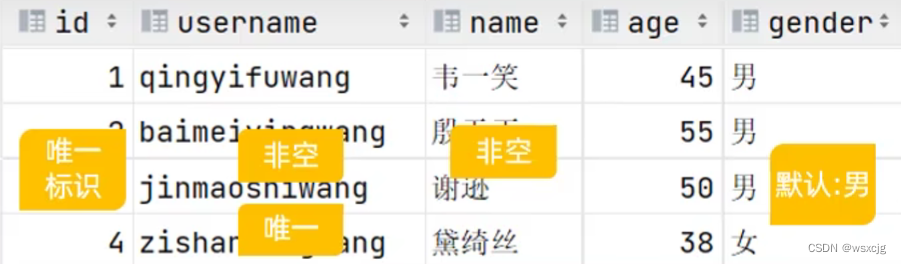
SQL代码:
create table tb_user
(
id int primary key auto_increment comment 'ID,唯一标识',
username varchar(20) not null unique comment '用户名,非空,唯一',
name varchar(10) not null comment '姓名,非空',
age int comment '年龄',
gender char(1) default '男' comment '默认:男'
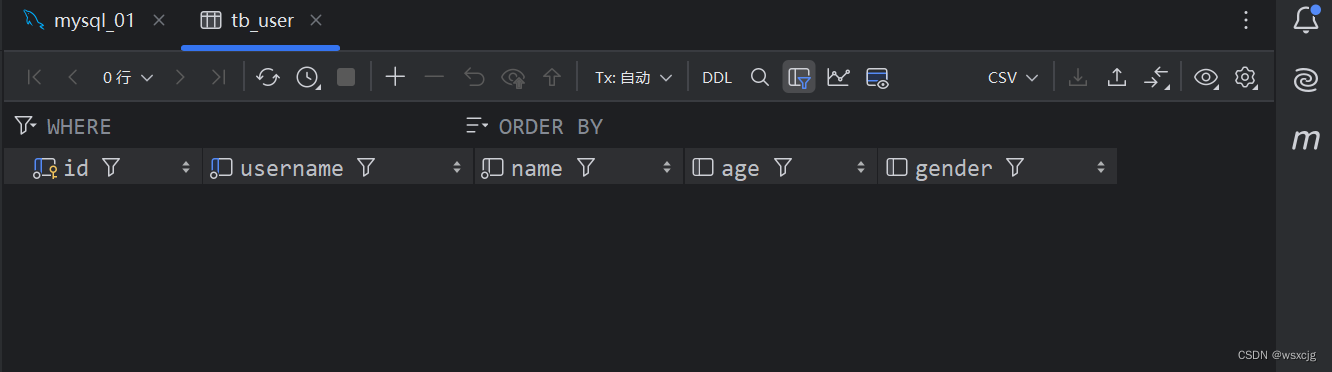
) comment '用户表'运行结果:
数据类型:
MySQL中的数据类型有很多,主要分为三类:数值类型,字符串类型,日期事件类型。
数值类型:
| 分类 | 类型 | 大小(byte) | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 | 备注 |
| 数值类型 | tinyint | 1 | (-128,127) | (0,255) | 小整数值 | |
| smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 | ||
| mediumint | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 | ||
| int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 | ||
| bigint | 8 | (-2^63,2^63-1) | (0,2^64-1) | 极大整数值 | ||
| float | 4 | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 | float(5,2):5表示整个数字长度,2 表示小数位个数 | |
| double | 8 | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 | double(5,2):5表示整个数字长度,2 表示小数位个数 | |
| decimal | 小数值(精度更高) | decimal(5,2):5表示整个数字长度,2 表示小数位个数 |
字符串类型:
| 分类 | 类型 | 大小 | 描述 | |||||
| 字符串类型 | char | 0-255 bytes | 定长字符串 | char(10): 最多只能存10个字符,不足10个字符,占用10个字符空间 | AB | 性能高 | 浪费空间 | |
| varchar | 0-65535 bytes | 变长字符串 | varchar(10): 最多只能存10个字符,不足10个字符, 按照实际长度存储 | ABC | 性能低 | 节省空间 | ||
| tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 | ||||||
| tinytext | 0-255 bytes | 短文本字符串 | ||||||
| blob | 0-65 535 bytes | 二进制形式的长文本数据 | ||||||
| text | 0-65 535 bytes | 长文本数据 | phone char(11) | |||||
| mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 | username varchar(20) | |||||
| mediumtext | 0-16 777 215 bytes | 中等长度文本数据 | ||||||
| longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 | ||||||
| longtext | 0-4 294 967 295 bytes | 极大文本数据 |
日期时间类型:
| 分类 | 类型 | 大小(byte) | 范围 | 格式 | 描述 |
| 日期类型 | date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 | |
| year | 1 | 1901 至 2155 | YYYY | 年份值 | |
| datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 | |
| timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
设计表流程:
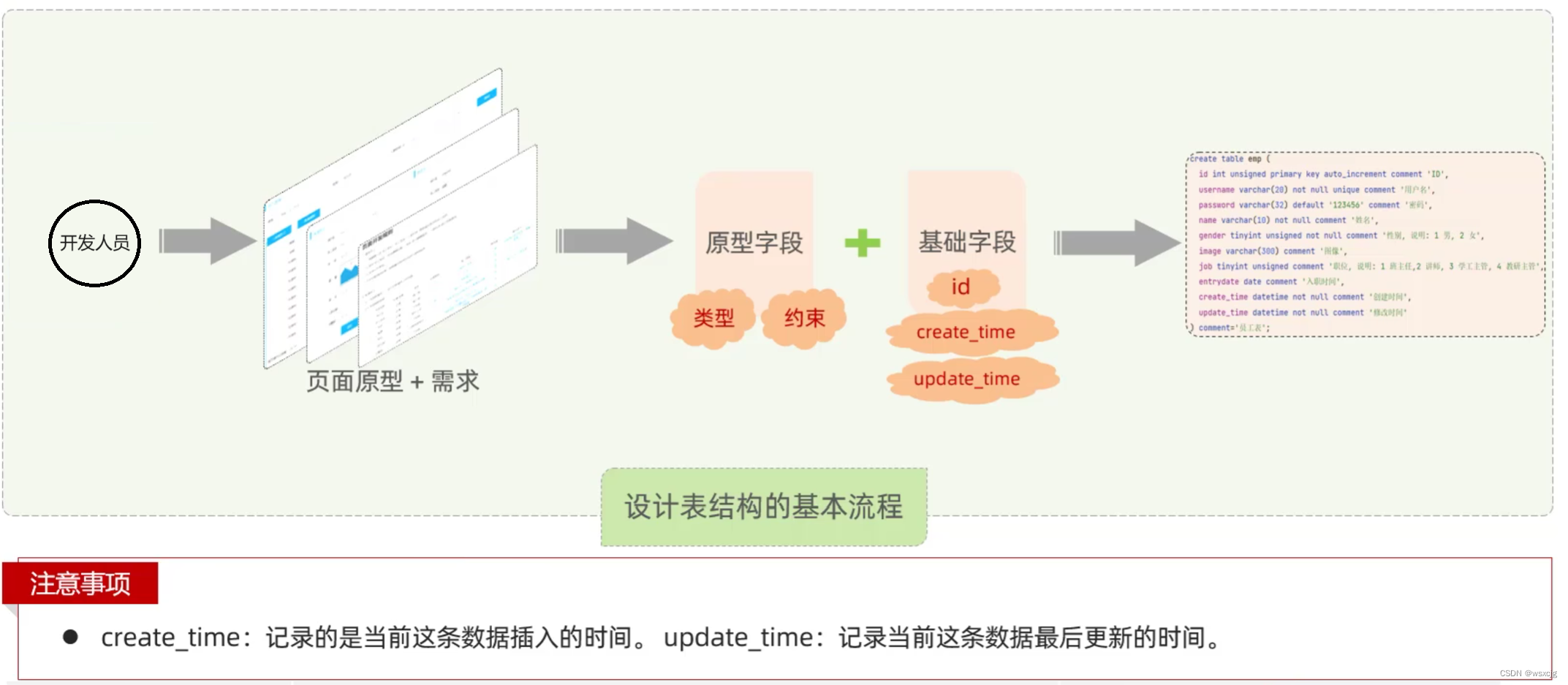
根据下面需求设计表
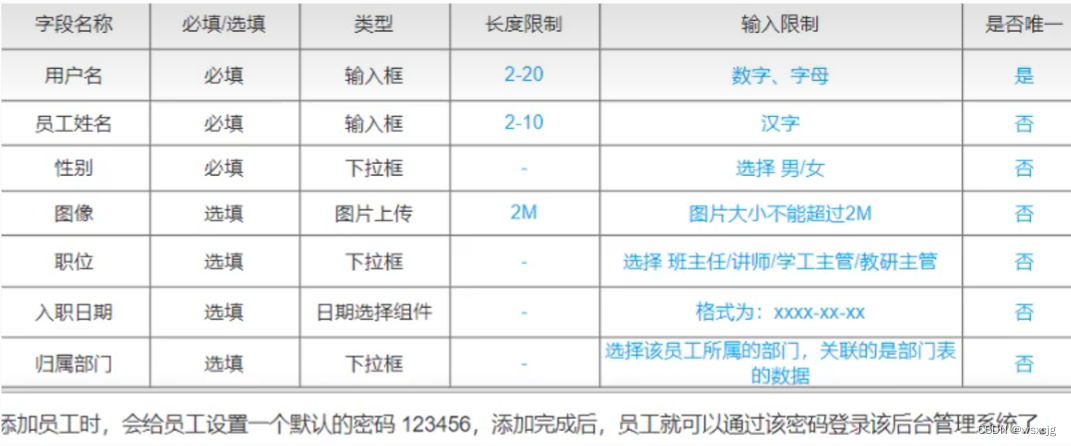
SQL代码:
CREATE TABLE `tb_emp` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'ID',
`username` varchar(20) NOT NULL COMMENT '用户名',
`password` varchar(32) DEFAULT '123456' COMMENT '密码,默认123456',
`name` varchar(10) NOT NULL COMMENT '员工姓名',
`gender` tinyint unsigned NOT NULL COMMENT '性别 1:男 2:女',
`image` varchar(30) DEFAULT NULL COMMENT '图像',
`position` tinyint unsigned DEFAULT NULL COMMENT '职位 1:班主任 2:讲师 3:学工主管 4:校验主管',
`joined_time` date DEFAULT NULL COMMENT '入职日期',
`create_time` datetime NOT NULL COMMENT '创建日期',
`update_time` datetime NOT NULL COMMENT '更新日期',
PRIMARY KEY (`id`),
UNIQUE KEY `tb_emp_pk_2` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci数据库操作:
DML:
添加数据:

注意事项:

代码演示:
-- 为tb_emp表的username,name,gender字段插入值
insert into tb_emp(username,name,gender,create_time,update_time) values('han','han',1,now(),now());
-- 为tb_emp表的所有字段插入值
insert into tb_emp values(null,'jq','123','han',1,'1.jpg',1,'2000-10-10',now(),now());
-- 批量为tb_emp表的username,name,gender字段插入值
insert into tb_emp(username,name,gender,create_time,update_time) values
('ma','han',1,now(),now()),('zhao','han',1,now(),now());更新数据

注意事项:
![]()
代码演示:
-- 将tb_emp表的ID为1员工的姓名name字段更新为‘张三’
update tb_emp
set name = '张三',
update_time = now()
where id = 1;
-- 将tb_emp表的所有员工的入职日期更新为‘2010-01-01’
update tb_emp
set joined_time='2010-01-01',
update_time = now();删除操作:

注意事项:

代码演示:
-- 删除tb_emp表中ID为1的员工
delete
from tb_emp
where id = 1;
-- 删除tb_emp表中的所有员工
delete
from tb_emp;DQL:

基本查询:

注意事项:

代码演示:
-- 查询指定字段name,entrydate 并返回
select name, entrydate
from tb_emp;
-- 查询所有字段并返回
-- 推荐
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp;
-- 不推荐
select *
from tb_emp;
-- 查询所有员工的name,entrydate 并起别名(姓名,入职日期)
select name as '姓名', entrydate as '入职日期'
from tb_emp;
-- 查询已有的员工关联了哪几种职位(不要重复)
select distinct job
from tb_emp;条件查询:

运算符:

代码演示:
-- 查询姓名为杨逍的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name = '杨逍';
-- 查询id小于等于5的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where id <= 5;
-- 查询没有分配职位的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job is null;
-- 查询有职位的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job is not null;
-- 查询密码不等于'123456'的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where password != '123456';
-- 查询入职日期在'2000-01-01'(包含)到'2010-01-01'(包含)之间的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where entrydate between '2000-01-01' and '2010-01-01';
-- 查询入职日期在'2000-01-01'(包含)到'2010-01-01'(包含)之间且性别为女的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where entrydate between '2000-01-01' and '2010-01-01'
and gender = 2;
-- 查询职位是2(讲师),3(学工主管),4(校验主管)的员工信息
-- 第一种写法
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job = 2 or job = 3 or job = 4;
-- 第二种写法
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job in (2,3,4);
-- 查询姓名为两个字的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '__';
-- 查询姓'张'的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '张%';分组查询:
这里先讲解聚合函数,再讲解分组查询。
聚合函数:

注意事项:

代码演示:
-- 统计该企业员工的数量
-- 1.count(字段)
select count(id)
from tb_emp;
-- 2.count(常量)
select count('1')
from tb_emp;
-- 3.count(*)--推荐
select count(*)
from tb_emp;
-- 统计该企业最早入职的员工
select min(entrydate)
from tb_emp;
-- 统计该企业最迟入职的员工
select max(entrydate)
from tb_emp;
-- 统计该企业员工ID的平均值
select avg(id)
from tb_emp;
-- 统计该企业员工的ID之和
select sum(id)
from tb_emp;分组查询:

注意事项:

代码演示:
-- 根据性别分组,统计男性和女性员工的数量
select gender,count(*)
from tb_emp
group by gender;
-- 先查询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*)
from tb_emp
where entrydate <= '2015-01-01'
group by job
having count(*) >= 2;★where与having的区别
1.执行时机不同:where是分组前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询:

排序方式:

注意事项:

代码演示:
-- 根据入职时间,对员工进行升序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate;
-- 根据入职时间,对员工进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate DESC;
-- 根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate, update_time DESC;
分页查询:

注意事项:

代码演示:
-- 从起始索引0开始查询员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 0,5;
-- 查询第一页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 0,5;
-- 查询第二页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 5,5;
-- 查询第三页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 10,5;案例:
下面给出三个案例,案例中还用到了这两个函数
if函数和case函数

代码演示:
-- 查找 名字里有张,性别男,入职日期在2000-01-01到2015-12-31之间的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '%张%'
and gender = 1
and entrydate between '2000-01-01' and '2015-12-31'
order by update_time DESC
limit 10,10;
-- 员工性别统计
select if(gender = 1, '男性员工', '女性员工') as 性别,count(*)
from tb_emp
group by gender;
-- 员工职位统计
select
(case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管'
when 4 then '教研主管' else '未分配职位' end) 职位,count(*)
from tb_emp
group by job;多表设计:
一对多:
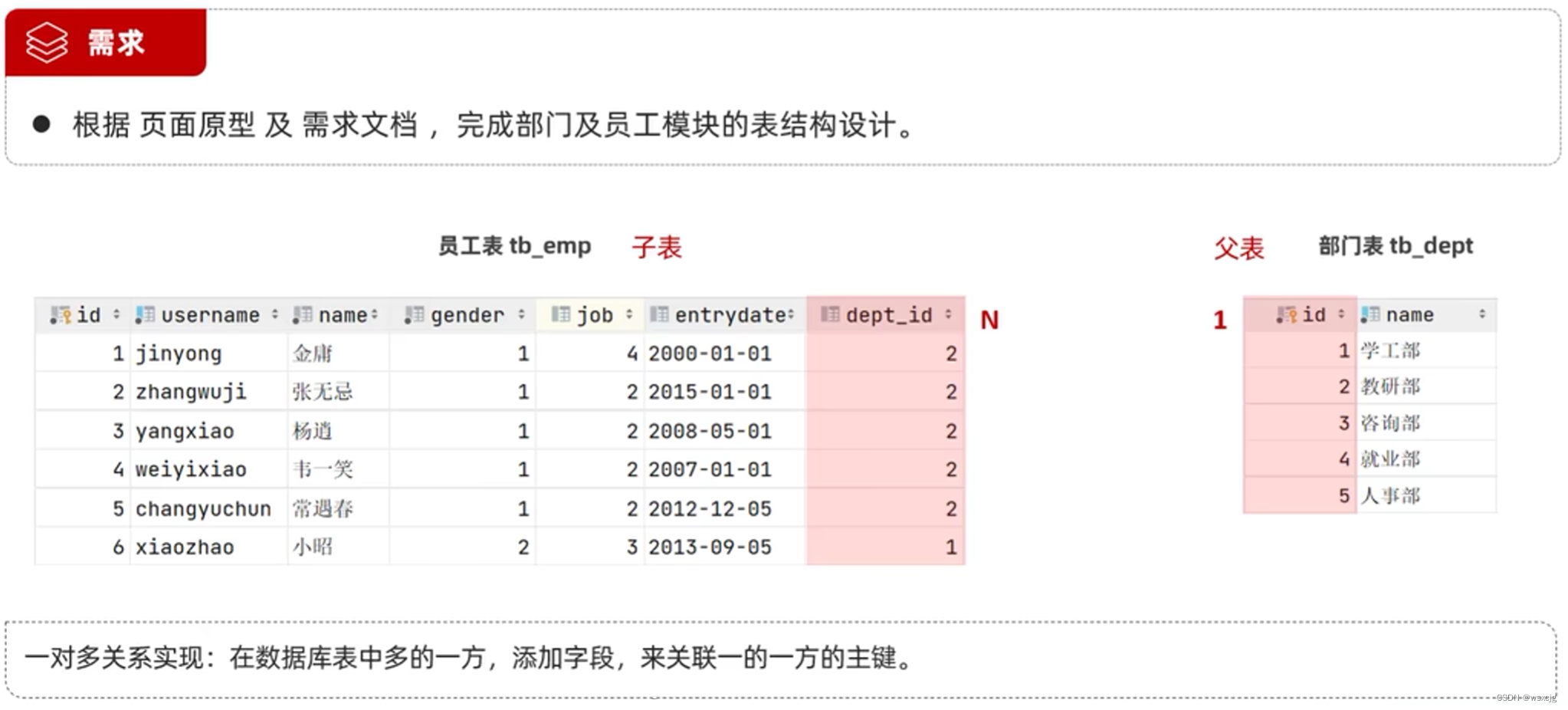
多表问题分析:


外键约束:


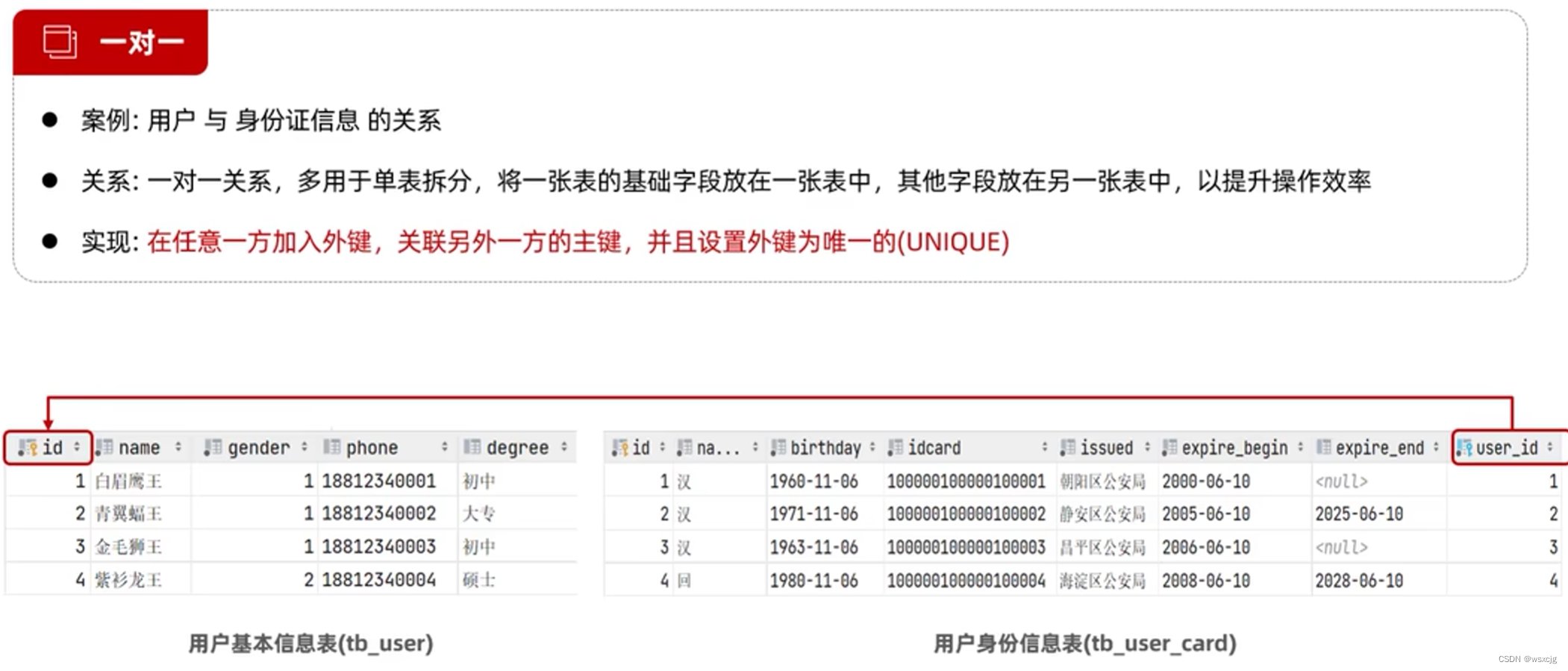
一对一:
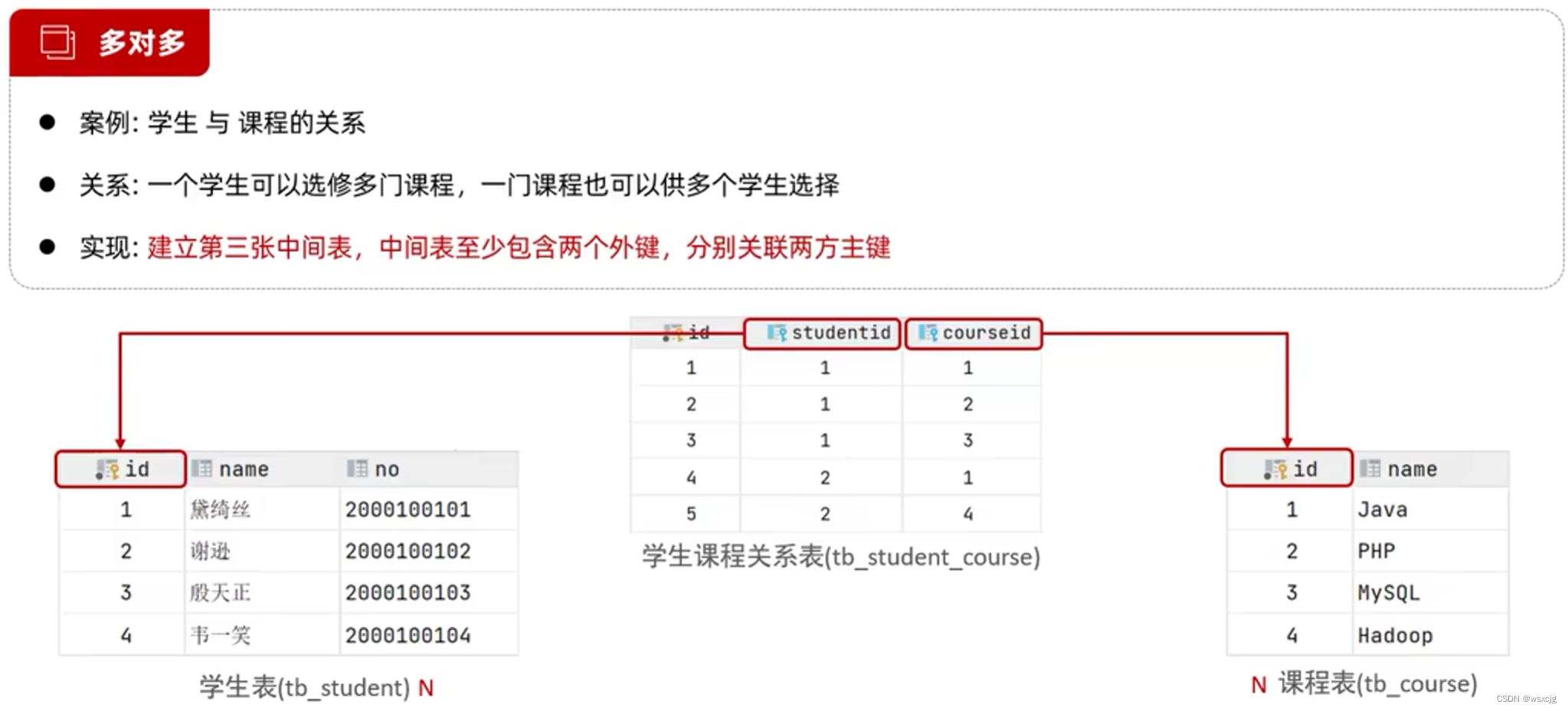
多对多:
小结:

多表查询:
从多张表中查询数据
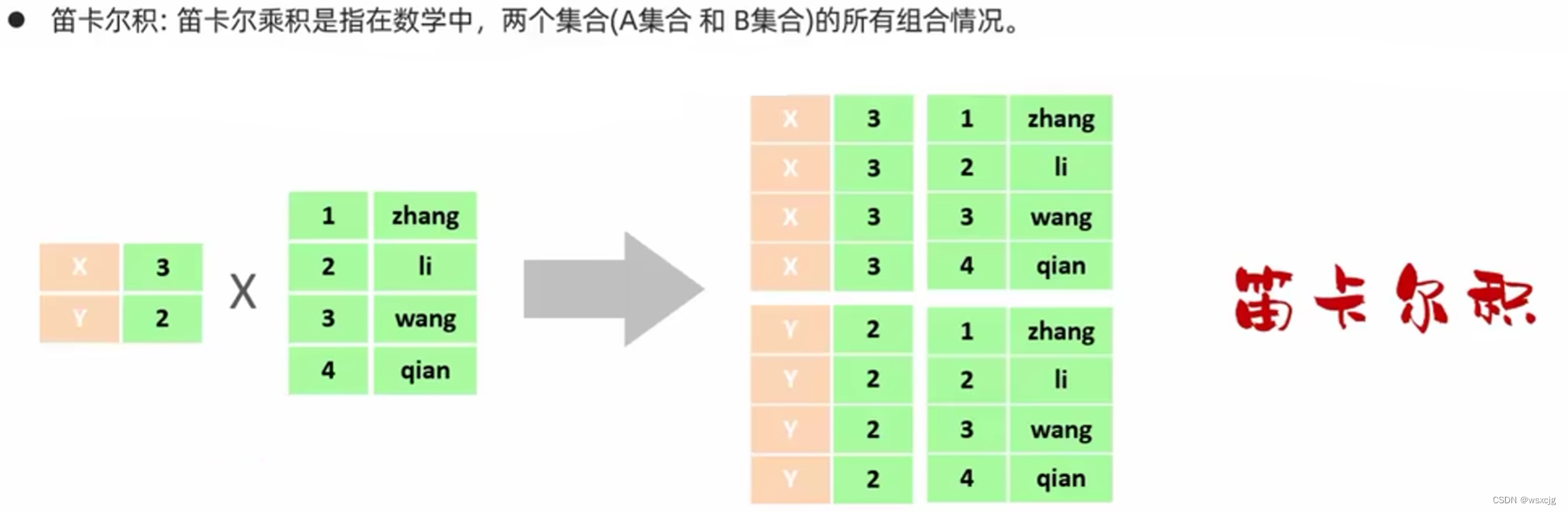
笛卡尔积:
直接在from后加入多个表会出现这多个表的笛卡尔积个数据,在多表查询时,需要消除无效的笛卡尔积。
连接方式:

内连接:

代码演示:
-- 查询员工的姓名,及所属的部门名称(隐式内连接实现)
select tb_emp.name, tb_dept.name
from tb_emp,
tb_dept
where tb_emp.dept_id = tb_dept.id;
-- 起别名 --简洁
select e.name,d.name
from tb_dept d,tb_emp e
where d.id = e.dept_id;
-- 查询员工的姓名,及所属的部门名称(显式内连接实现)
select tb_emp.name, tb_dept.name
from tb_emp
join tb_dept
on tb_emp.dept_id = tb_dept.id;外连接:

代码演示:
-- 查询员工表所有员工的姓名和对应的部门名称(左外连接)
select e.name,d.name
from tb_emp e
left join tb_dept d
on e.dept_id = d.id;
-- 查询部门表所有部门名称和对应的员工的姓名(右外连接)
select e.name,d.name
from tb_emp e
right join tb_dept d
on e.dept_id = d.id;子查询:
标量子查询:

代码演示:
-- 查询教研部的所有员工信息
select *
from tb_emp
where dept_id = (select id
from tb_dept
where name = '教研部');
-- 查询在方东白入职之后的员工信息
select *
from tb_emp
where entrydate > (select entrydate
from tb_emp
where name = '方东白');列子查询

代码演示:
-- 查询教研部和咨询部的所有员工信息
select *
from tb_emp
where dept_id in (select id
from tb_dept
where name in ('教研部', '咨询部'));行子查询:

代码演示:
-- 查询与韦一笑的入职日期及职位都相同的员工信息
select *
from tb_emp
where (entrydate, job) = (select entrydate, job
from tb_emp
where name = '韦一笑');表子查询:

代码演示:
-- 查询入职日期是2006-01-01之后的员工信息,及其部门名称
select e.*, d.name
from (select *
from tb_emp
where entrydate > '2006-01-01') e,
tb_dept d
where e.dept_id = d.id;案例:
-- 1. 查询价格低于 10元 的菜品的名称 、价格 及其 菜品的分类名称 .
select d.name,d.price,c.name
from dish d,category c
where d.category_id = c.id
and d.price < 10;
-- 2. 查询所有价格在 10元(含)到50元(含)之间 且 状态为'起售'的菜品名称、价格 及其 菜品的分类名称 (即使菜品没有分类 , 也需要将菜品查询出来).
select d.name,d.price,c.name
from dish d
left join category c
on d.category_id = c.id
where d.price between 10 and 50
and d.status = 1;
-- 3. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格 .
select c.name, max(d.price)
from category c,
dish d
where c.id = d.category_id
group by c.id;
-- 4. 查询各个分类下 状态为 '起售' , 并且 该分类下菜品总数量大于等于3 的 分类名称 .
select c.name
from category c,
dish d
where c.id = d.category_id
and d.status = 1
group by c.name
having count(*) >= 3;
-- 5. 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数).
select s.name, s.price, d.name, d.price, sd.copies
from dish d,
setmeal_dish sd,
setmeal s
where d.id = sd.dish_id
and sd.setmeal_id = s.id
and s.name = '商务套餐A';
-- 6. 查询出低于菜品平均价格的菜品信息 (展示出菜品名称、菜品价格).
select d.name, d.price
from dish d
where d.price < (select avg(d.price)
from dish d);事务:
使用场景:
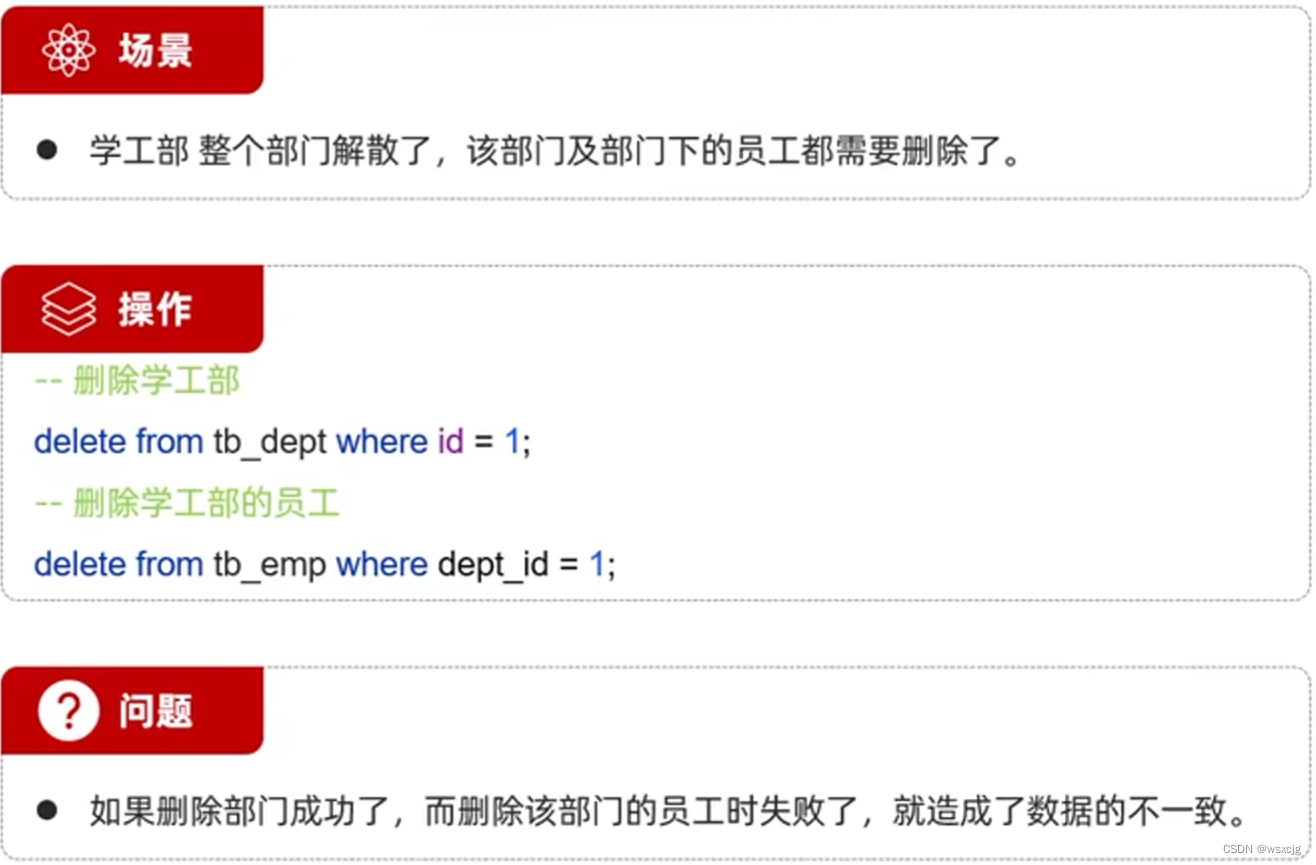
介绍:

操作:

★事物的四大特性(ACID):

索引:

优缺点:

索引的缺点到目前影响已经很小,因为第一点企业的磁盘空间很大,索引占用的空间与之相比很小,第二点数据查询业务基本占总体业务的百分之九十,所以降低增删改效率影响也不大。
结构:

思考:为什么索引结构不采用二叉搜索树和红黑树?
答:因为在大数据情况下,树的层次深,检索速度慢
B+Tree(多路平衡搜索树):
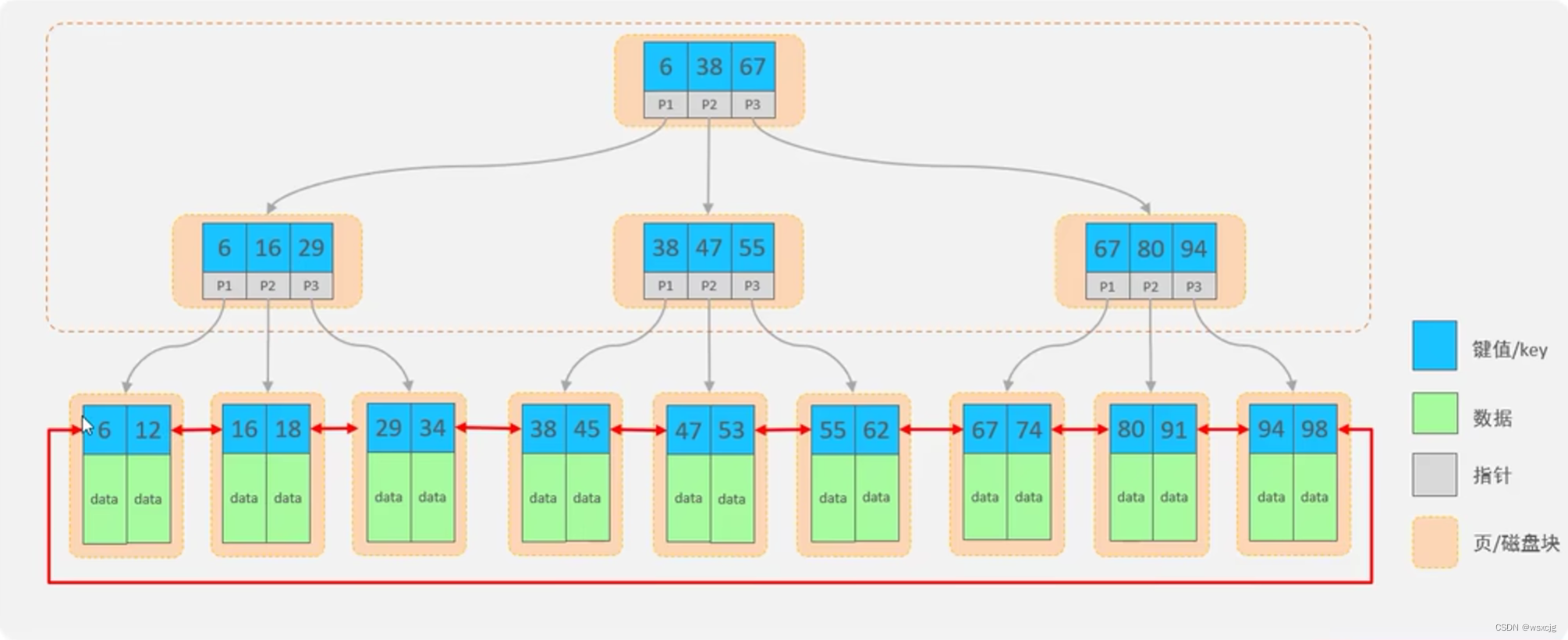
特点:

代码演示:
-- 创建:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询:查询tb_emp表的索引信息
show index from tb_emp;
-- 删除:删除tb_emp表中的name字段的索引
drop index idx_emp_name on tb_emp;注意事项:

主键索引性能最高















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









