










java中用String类表示字符串,是lang包里面使用频率很高的一个类,今天我们就来深入源码解析。事例和特性均基于java8版本。
基础知识
String内部使用char[]数组实现,是不可变类。
public final class String implements java.io.Serializable,Comparable<String>,CharSequence private final char value[]; //String的内部表示,不可变
private int hash; // Default to 0 ,String的哈希值
String实现了Serializable接口,表明其可被序列化。在java中Serializable接口只是一个标记接口,该接口没有任何方法定义。只要在类定义时标明实现该接口,JVM会自动处理。
String还实现了Comparable比较器接口,我们在TreeMap的排序及比较器问题文章提过,它是一个类的内部比较接口。一般的值类及集合类均实现了此接口。比较规则为等于返回0,大于返回正值而小于返回负值。
在此接口文档中特别强调,此接口的实现需与equals()方法行为一致。即 保证
a.compareTo(b)==0满足的同时a.equals(b)==true也必须满足。
该接口实现如下:
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}代码逻辑比较简单,就是按字符的ASCII码逐一比较两字符串。
CharSequence接口是所有字符序列的父接口,String、StringBuffer、StringBuilder等字符序列均实现了此接口。该接口定义了对字符序列对基本操作,具体如下:
int length();
char charAt(int index);
CharSequence subSequence(int start, int end);
public String toString();
public default IntStream chars(){}
public default IntStream codePoints() {}前面几个接口定义获取长度、随机读取字符、获取子序列的方法,后两个是java8的default方法,提供关于Stream的操作,这里暂且不管。
方法汇总
String类有字符操作的各种方法。我们先对其进行分类,再一一分析其用途。
1. 构造函数
public String() :空构造函数
public String(byte[ ] bytes):通过byte数组构造字符串对象。
public String(byte bytes[], String charsetName)
public String(byte byte public String(byte bytes[], int offset, int length)s[], Charset charset)
public String(char[ ] value):通过char数组构造字符串对象。
public String(char value[], int offset, int count)
public String(StringBuffer buffer):通过StringBuffer数组构造字符串对象。
public String(StringBuilder builder): 通过StringBuilder数组构造字符串对象。 关于构造函数大致就这几类:除了默认构造函数外、还有通过char[]、byte[]、String、StringBuffer、StringBuilder作为参数的构造函数。(这些参数的其他版本没有全部列出)。
1⃣️ 通过char[]构造字符串
字符串内部由char[]表示,使用它作为参数构造理所当然。
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}// Arrays.copyOf
public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength]; //创建了新char[]数组
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength)); //将数据拷贝到新数组
return copy; //返回新数组。
} 可见String(char value[]) 构造函数不会使用传进来的char[],而是新建一个char[]并返回。这样即使改变了参数char[],也不会影响String。如以下示例:
//示例1
public class StringTest {
public static void main(String[] args) {
final char[] value = {'a', 'b', 'c'};
String str =new String(value);
value[0]='b'; //传入数组改变
System.out.println(str); //abc ,字符串不变
}
}System.arraycopy是一个native`方法,基本功能就是复制数组。暂且不管。
2⃣️通过StringBuffer和StringBuilder构造
String 、StringBuffer、 StringBuilder 同属CharSequence接口的实现类。内部表示也均使用char[]。StringBuffer和StringBuilder可以理解为可变的字符串版本。只是前者同步而后者非同步而已。
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}StringBuilder与此相似,只是没有synchronized块。Arrays.copyOf()表明仍然是重新创建char[]后复制返回。
看了以上3种字符串的构造方式,你可能会疑问,为什么它们都要重新复制一份char数组而不是直接利用参数传来的呢?比如这样:
public String(char value[]) {
this.value =value;
}
原因其实就是我们前面说的,保持String的不可变性。如果按上面这样写,在外面改变了char[]数组,String也会跟着改变。那上面的示例1最后String会变成bbc,这样的String不是我们需要的。
3⃣️用String对象初始化
有一点例外的是,使用String参数构造String时直接使用此String参数,这是利用了String本身的不可变性。
public String(String original) {
//将参数字符串的char[]和hash直接赋给目标String
this.value = original.value;
this.hash = original.hash;
}参数original本身不可变,所以这样写是安全的。
你可能会以为,这样构造的话两个字符串岂不共用同一块char[]数组?
可以进行测试
public static void main(String[] args) {
String str1 = new String("abc");
String str2 = new String(str1);
System.out.println(str1 == str2);
}输出结果为false,我当时很奇怪,这是为什么?
后来了解java内存模型后才知道:
- 这样构造的确共用同一块char数组。
- new关键字表明为对象新创建内存空间(准确说是在java堆中创建对象)。
于是上述内存模型就像这样:
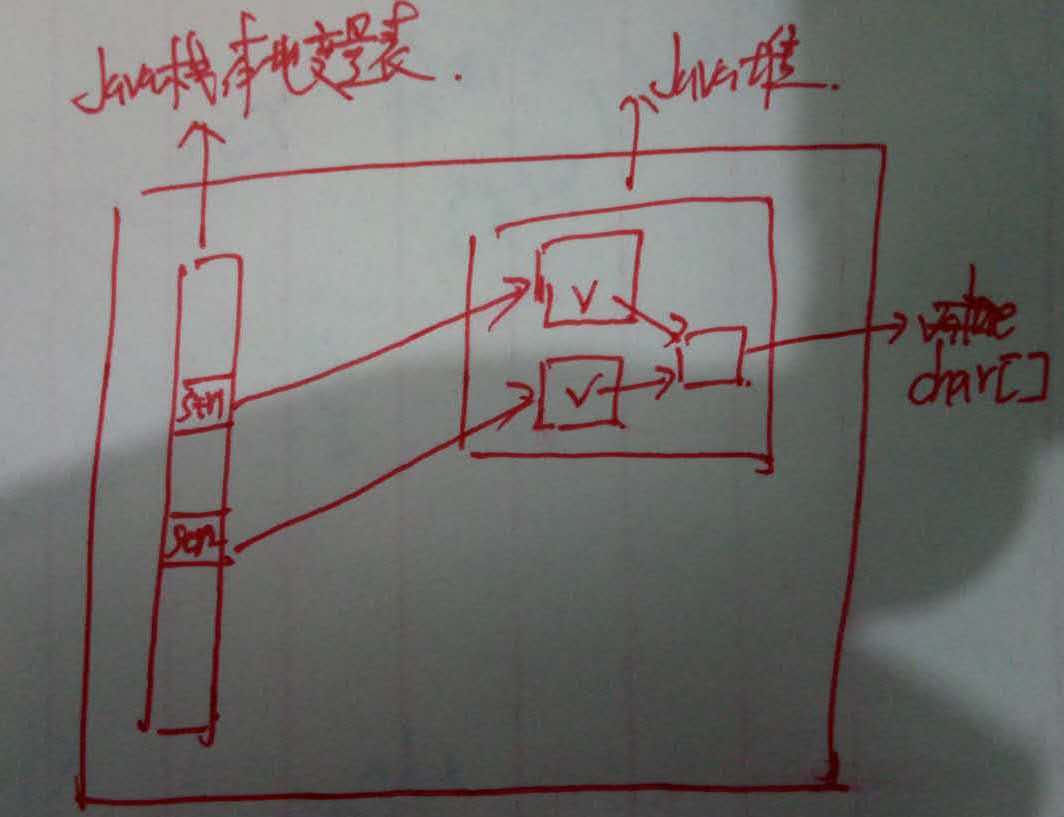
两个字符串引用指向两块不同的内存空间,str1==str2必定为false。而字符串内部的char[] 数组(图中的v)指向同一块char[]数组。
4⃣️使用byte[]构造String
提到字节数组,就不能不提编码了。事实上,编码解码大多是针对byte[]与char[]进行的。这是不做详细介绍,可以看深入分析 Java 中的中文编码问题。将char[]按一定规则转为byte[]为编码,将byte[]转为char[]为解码。编码解码必须使用同一套字符集,否则会出现乱码。
public void test()throws Exception {
String str ="abc";
byte [] bytes = {48,57,65,97}; //用不大于127的数字构造字节数组
String str1 = new String(bytes,"ASCII"); // 指定编码集
System.out.println("str1 = " + str1); // 09Aa
String str3 = "你好,世界!";
byte[] bytes2 = str3.getBytes("UTF-8"); //获取一句汉字字节数组
String str_zh = new String(bytes2,"UTF-8");
String str_zh2 = new String(bytes2,"ISO-8859-1");
System.out.println("str_zh = " + str_zh); //你好,世界!
//编码解码不一致,会出现乱码
System.out.println("str_zh2 = " + str_zh2); //ä½ å¥½ï¼Œä¸–ç•Œï¼
//用不支持中文的字符集编码,也会有乱码
byte [] bytes3 = str3.getBytes("ASCII");
String str_zh3 = new String(bytes3,"ASCII");
System.out.println("str_zh3 = " + str_zh3); //??????
}知识点:
1. new String(byte[],String)或new String(byte[]) 等方法将字节数组转为字符串。getBytes(String)将字符串转为字节数组。
2. 编码和解码的字符集要一致,否则会出现乱码。
2. 重写的Object方法(equals和hashCode)
String 重写了equals()方法和hashCode方法。
对于equals() 是逐一比较每个字符,若都相等则为真否则为假。
//String 的equals()源码
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}对于hashCode方法,使用公式s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]。使用31作为基数的原因在于31是素数。解释在stackoverflow
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}3 . indexOf()及lastIndexOf()方法
indexOf系列的公共方法有:
indexOf(int ch)
indexOf(int ch,int fromIndex)
indexOf(String str)
indexOf(String str,int fromIndex)lastIndexOf(int ch)
lastIndexOf(int ch,int fromIndex)
lastIndexOf(String str)
lastIndexOf(String str,int fromIndex)
indexOf()系列功能为根据单个字符或一段字符串求出其在整字符串第一次的索引位置,若不存在则为-1。
public int indexOf(int ch, int fromIndex) {
final int max = value.length; //字符串长度
if (fromIndex < 0) { //fromIndex,从字符串哪里查起
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}indexOf(String str)内部实现。
source 表示源字符串,sourceOffset源字符串起始位置,sourceCount源字符串长度, 即可对源字符串截取
target目标字符串,targetOffset目标字符串起始位置,targetCount目的字符串长度。fromIndex从截取后的源字符串的指定索引查找。
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset]; //获取目标字符串第一个字符,以下先查找出第一个字符,若存在则继续比较
int max = sourceOffset + (sourceCount - targetCount); //max = 源字符串长度-目标字符串长度
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* 查找第一个字符. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* 匹配到第一个字符,开始试图匹配目的字符串其他字符*/
if (i <= max) {
int j = i + 1; //从第二字符开始
int end = j + targetCount - 1;
//第二次比较
for (int k = targetOffset + 1; j < end && source[j] == target[k]; j++, k++);
if (j == end) { //如果全部比完
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}上述算法可普遍应用于从大字符串查找小字符串的情景中。基本思路就是先查找小字符串的首字符,若找到则继续查找剩下的字符。
lastIndexOf()算法与此类似,只是从后向前查找。
后记:本来想一篇写完的,没想到废话有点多(只是想说清楚啊=_=),居然写这么长了。只好分2篇了,余下那篇抽空补上吧。
祝大家双十一(☆☆)Y(^^)Y……















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









