







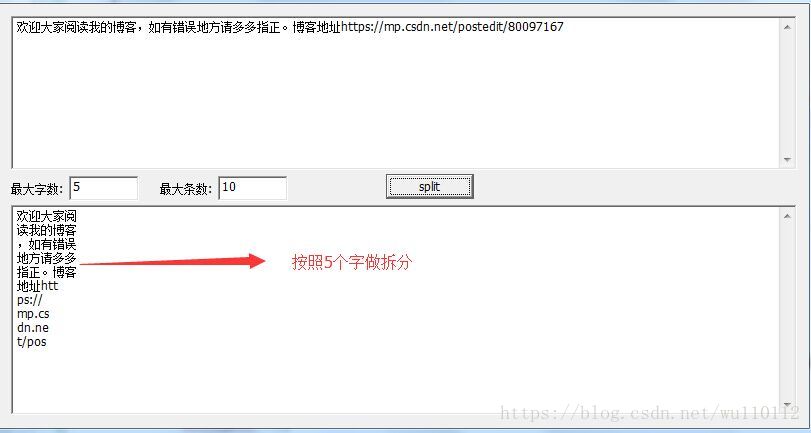
UFT8和UCS2互转效API使用进行拆分字数如图
/*
* 函数:
* utf8_to_ucs2(utf8转ucs2)
* 参数:
* utf8:utf8数据
* utf8_lenght:utf8数据长度
* ucs2:保存ucs2数据空间
* ucs2_lenght:保存ucs2数据空间长度
* 返回值:
* 返回转换后的ucs2字节长度
* 备注:
* ucs2等于NULL或utf8_lenght小于0都会作为统计不做赋值操作
* ssdwujianhua 2018/04/26
*/
unsigned int utf8_to_ucs2(const char * utf8, unsigned int utf8_lenght, char *ucs2, unsigned int ucs2_lenght)
{
if ( utf8_lenght < 1 && utf8_lenght > ucs2_lenght)
{
return 0;
}
unsigned int utf8_pos = 0; //字节偏移位置
unsigned int ucs2_pos = 0;
bool bcount = true; //是否统计
if(ucs2 != NULL || ucs2_lenght < 0)
{
bcount = false;
}
while(true)
{
if((utf8[utf8_pos]&0x80)==0) //1字节
{
if( !bcount )
{
ucs2[ucs2_pos]=0;
ucs2[ucs2_pos+1]=utf8[utf8_pos]&0x7f;
}
utf8_pos+=1;
ucs2_pos+=2;
}
else if((utf8[utf8_pos]&0xe0)==0xc0)//2字节
{
if(!bcount)
{
ucs2[ucs2_pos]=(utf8[utf8_pos]&0x1f)>>2;
ucs2[ucs2_pos+1]=((utf8[utf8_pos]&0x03)<<6)|(utf8[utf8_pos+1]&0x3f);
}
utf8_pos+=2;
ucs2_pos+=2;
}
else if((utf8[utf8_pos]&0xf0)==0xe0)//3字节
{
if(!bcount)
{
ucs2[ucs2_pos]=((utf8[utf8_pos]&0x0f)<<4)|((utf8[utf8_pos+1]&0x3f)>>2);
ucs2[ucs2_pos+1]=((utf8[utf8_pos+1]&0x03)<<6)|(utf8[utf8_pos+2]&0x3f);
}
utf8_pos+=3;
ucs2_pos+=2;
}
else
{
return -1;
}
if ( utf8_pos >= utf8_lenght)
{
if(!bcount)
ucs2[ucs2_pos]='\0';
break;
}
}
return ucs2_pos;
}
/*
* 函数:
* ucs2_to_utf8
* 参数:
* ucs2:ucs2数据
* ucs2_lenght:ucs2数据长度
* utf8:保存utf8数据空间
* utf8_lenght:保存utf8数据空间长度
* 返回值:
* 返回转换后的utf8字节长度
* 备注:
* uft8等于NULL或utf8_lenght小于0都会作为统计不做赋值操作
* ssdwujianhua 2018/04/26
*/
unsigned int ucs2_to_utf8(const char *ucs2, unsigned int ucs2_lenght, char * utf8, unsigned int utf8_lenght)
{
if ( utf8_lenght < 1 && (utf8_lenght > ucs2_lenght))
{
return 0;
}
unsigned int utf8_pos = 0; //字节偏移位置
unsigned int ucs2_pos = 0;
bool bcount = true; //是否统计
if(utf8 != NULL || utf8_lenght < 0)
{
bcount = false;
}
while(true)
{
if (ucs2[ucs2_pos] == 0x00 && ucs2[ucs2_pos+1] <= 0x7f) //2个字节转成一个字节
{
if(!bcount)
{
utf8[utf8_pos]=ucs2[ucs2_pos+1]&0x7f;
}
ucs2_pos+=2;
utf8_pos+=1;
}
else if ((ucs2[ucs2_pos]&0xf8)==0)//两个字节处理
{
if(!bcount)
{
utf8[utf8_pos]=0xc0|((ucs2[ucs2_pos]&0x07)<<2)|((ucs2[ucs2_pos+1]&0xc0)>>6);
utf8[utf8_pos+1]=0x80|ucs2[ucs2_pos+1]&0x3f;
}
ucs2_pos+=2;
utf8_pos+=2;
}
else//三个字节处理
{
if(!bcount)
{
utf8[utf8_pos]=0xe0|((ucs2[ucs2_pos]&0xf0)>>4);
utf8[utf8_pos+1]=0x80|((ucs2[ucs2_pos]&0x0f)<<2)|((ucs2[ucs2_pos+1]&0xc0)>>6);
utf8[utf8_pos+2]=0x80|ucs2[ucs2_pos+1]&0x3f;
}
ucs2_pos+=2;
utf8_pos+=3;
}
if (ucs2_pos >= ucs2_lenght )
{
if(!bcount)
utf8[utf8_pos] = '\0';
break;
}
}
return utf8_pos;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









