







10. 理解索引下推
看下如下SQL:
select * from employee where name like '小%' and age=28 and sex='0';
其中,name和age为联合索引(idx_name_age)。
如果是Mysql5.6之前,在idx_name_age索引树,找出所有名字第一个字是“小”的人,拿到它们的主键id,然后回表找出数据行,再去对比年龄和性别等其他字段。如图:
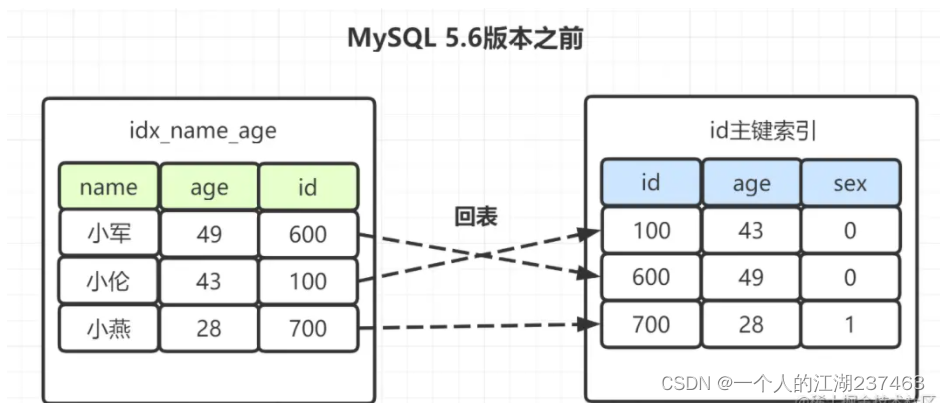
这时候我们会感觉奇怪,idx_name_age(name,age)是联合索引,为什么选出包含“小”字后,不再顺便看下年龄age再回表呢,所以在MySQL 5.6就引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
因此,MySQL5.6版本之后,选出包含“小”字后,顺表过滤age=28
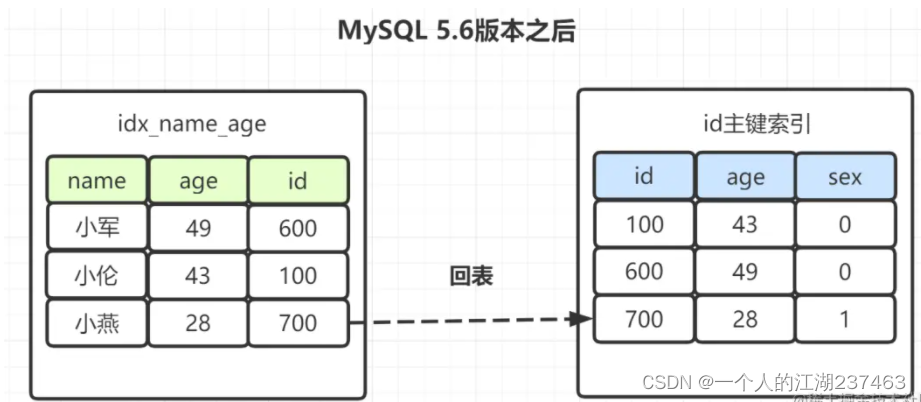
其实就一句话:在搜索引擎中提前判断对应的搜索条件是否满足,满足了再去回表,通过减少回表次数进而提高查询效率。
11. 大表如何添加索引
如果一张表数据量级是千万级别以上的,如何给这张表添加索引?
要注意一点:给表添加索引的时候,是会对表加锁的。如果不谨慎操作,有可能出现生产事故的。可以参考以下步骤:
- 创建一张和原表结构一样的空表,只是表名不一样;
create table tb_name_tmp like tb_name;
- 把新建的空表非主键索引都删掉,因为这样在往新表导数据的时候效率会很快(因为除了必要的主键以外,不用再去建立其它索引数据了)
alter tb_name_tmp drop index index_name;
- 从旧表往主表里导数据,如果数据太大,建议分批导入,只需确保无重复数据就行,因为导入数据太大,会很占用资源(内存,磁盘io, cpu等),可能会影响旧表在线上的业务。我是每批次100万条数据导入,基本上每次都是在 20s左右;
insert into tb_name_tmp select * from tb_name where id between start_id and end_id;
- 数据导完后,再对新表进行添加索引;
create index index_name on tb_name_tmp(column_name);
- 当大部分数据导入后,索引也建立好了,但是旧表数据量还是会因业务的增长而增长,这时候为了确保新旧表的数据一至性和平滑切换,建议写一个脚本,判断当旧表的数据行数与新表一致时,就切换。我是以 max(id)来判断的。
table tb_name to tb_name_tmp1;
table tb_name_tmp to tb_name;
12. 如何知道语句是否走索引查询?
可以采用explain关键字查看SQL的执行计划,就可以知道是否命中索引。
当explain与SQL一起使用时,MySQL将显示来自优化器的有关语句执行计划的信息。

一般来说,我们需要重点关注type、rows、filtered、extra、key。
12.1 type
type表示连接类型,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- system:这种类型要求数据库表中只有一条数据,是const类型的一个特例,一般情况下是不会出现的。
- const:通过一次索引就能找到数据,一般用于主键或唯一索引作为条件,这类扫描效率极高,,速度非常快
- eq_ref:常用于主键或唯一索引扫描,一般指使用主键的关联查询
- ref : 常用于非主键和唯一索引扫描。
- ref_or_null:这种连接类型类似于ref,区别在于MySQL会额外搜索包含NULL值的行
- index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。
- unique_subquery:类似于eq_ref,条件用了in子查询
- index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值。
- range:常用于范围查询,比如:between … and 或 In 等操作
- index:全索引扫描
- ALL:全表扫描
12.2 rows
该列表示MySQL估算要找到我们所需的记录,需要读取的行数。对于InnoDB表,此数字是估计值,并非一定是个准确值。
12.3 filtered
该列是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
12.4 extra
该字段包含有关MySQL如何解析查询的其他信息,它一般会出现这几个值:
- Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于order by语句
- Using index :表示是否用了覆盖索引。
- Using temporary: 表示是否使用了临时表,性能特别差,需要重点优化。一般多见于group by语句,或者union语句。
- Using where : 表示使用了where条件过滤.
- Using index condition:MySQL5.6之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
12.5 key
该列表示实际用到的索引。一般配合possible_keys列一起看。
13. Hash 索引和 B+树区别是什么?设计索引如何抉择?
- B+树可以进行范围查询,Hash 索引不能。
- B+树支持联合索引的最左侧原则,Hash 索引不支持。
- B+树支持 order by 排序,Hash 索引不支持。
- Hash 索引在等值查询上比 B+树效率更高。(但是索引列的重复值很多的话,Hash冲突,效率降低)。
- B+树使用 like 进行模糊查询的时候,like 后面(比如%开头)的话可以起到优化的作用,Hash 索引根本无法进行模糊查询。
14. 索引有哪些优缺点?
优点:
- 索引可以加快数据查询速度,减少查询时间
- 唯一索引可以保证数据库表中每一行的数据的唯一性
缺点:
- 创建索引和维护索引要耗费时间
- 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间
- 以表中的数据进行增、删、改的时候,索引也要动态的维护。
15. 聚簇索引与非聚簇索引的区别
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。它表示索引结构和数据一起存放的索引。非聚簇索引是索引结构和数据分开存放的索引。
分不同的引擎:
在MySQL的InnoDB存储引擎中, 聚簇索引与非聚簇索引最大的区别,在于叶节点是否存放一整行记录。聚簇索引叶子节点存储了一整行记录,而非聚簇索引叶子节点存储的是主键信息,因此,一般非聚簇索引还需要回表查询。
- 一个表中只能拥有一个聚集索引(因为一般聚簇索引就是主键索引),而非聚集索引一个表则可以存在多个。
- 一般来说,相对于非聚簇索引,聚簇索引查询效率更高,因为不用回表。
而在MyISM存储引擎中,它的主键索引,普通索引都是非聚簇索引,因为数据和索引是分开的,叶子节点都使用一个地址指向真正的表数据。















 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











