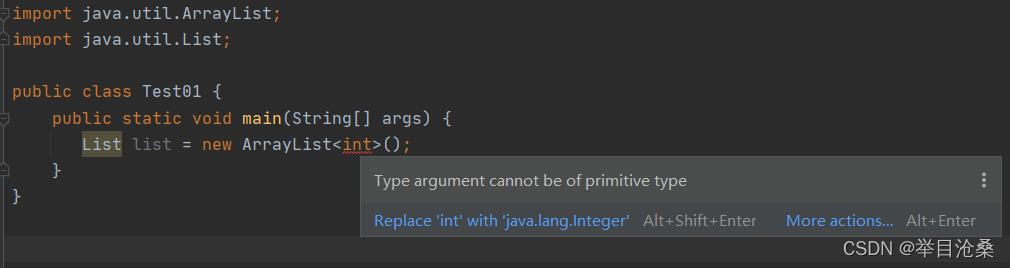
本质上是一种可以存放任意类型对象的容器(可以结合泛型存储指定的类型)
1.Java集合的长度根据元素的大小可变化 2.Java集合只能存放引用类型数据,不能存放基本数据类型 3.Java可以通过包装类将基本数据类型转换为对象类型存放在集合中(自动封箱机制) 4.Java集合中实际存放的只是对象的引用,每个集合元素都是一个引用变量,实际内容都存放在堆内存或者方法区中
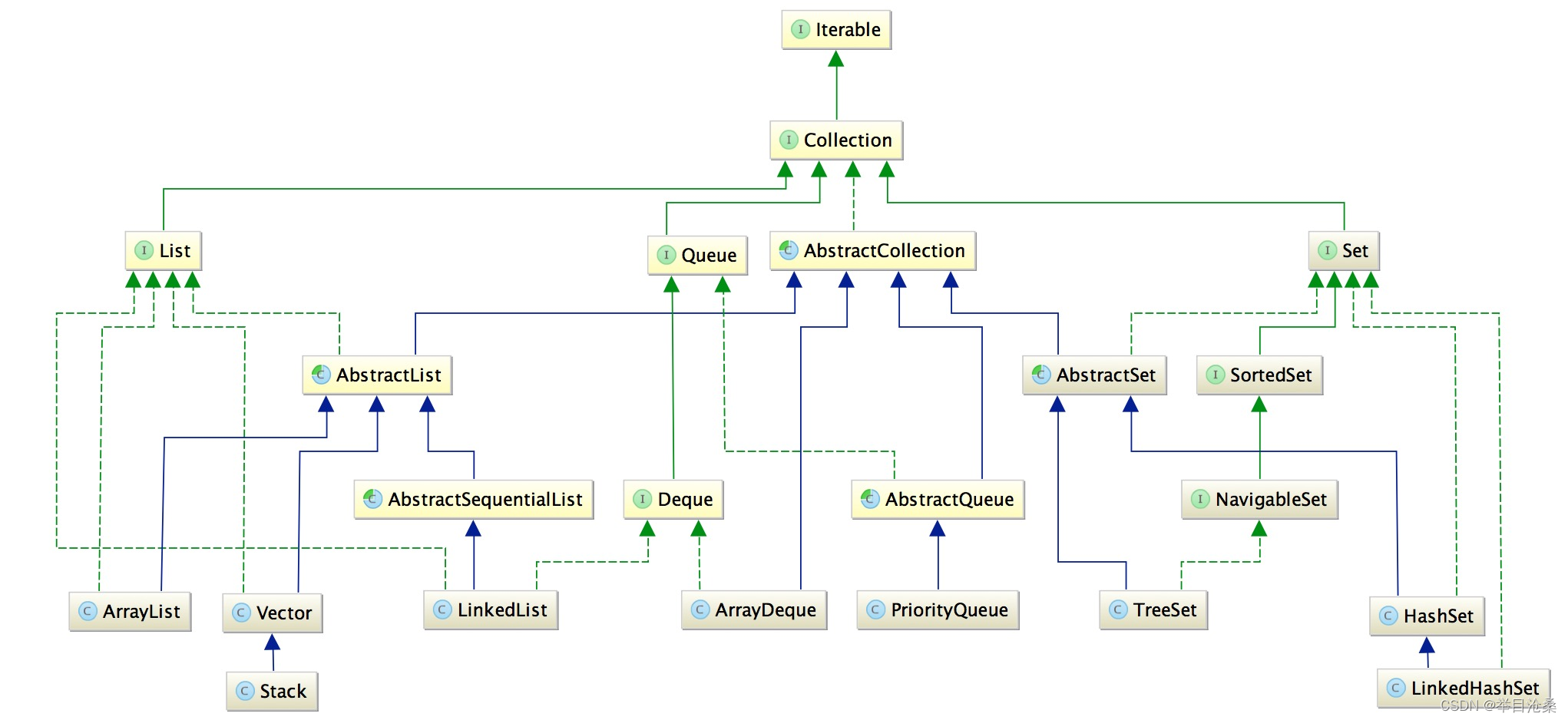
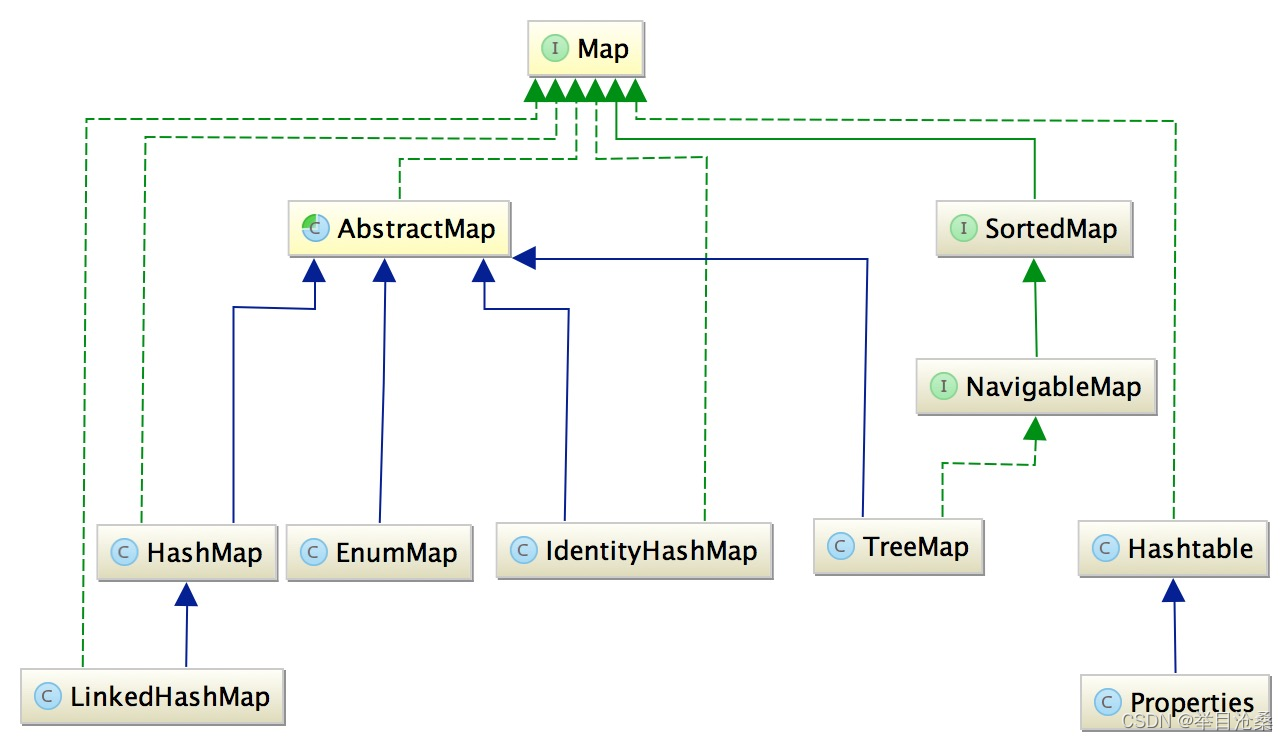
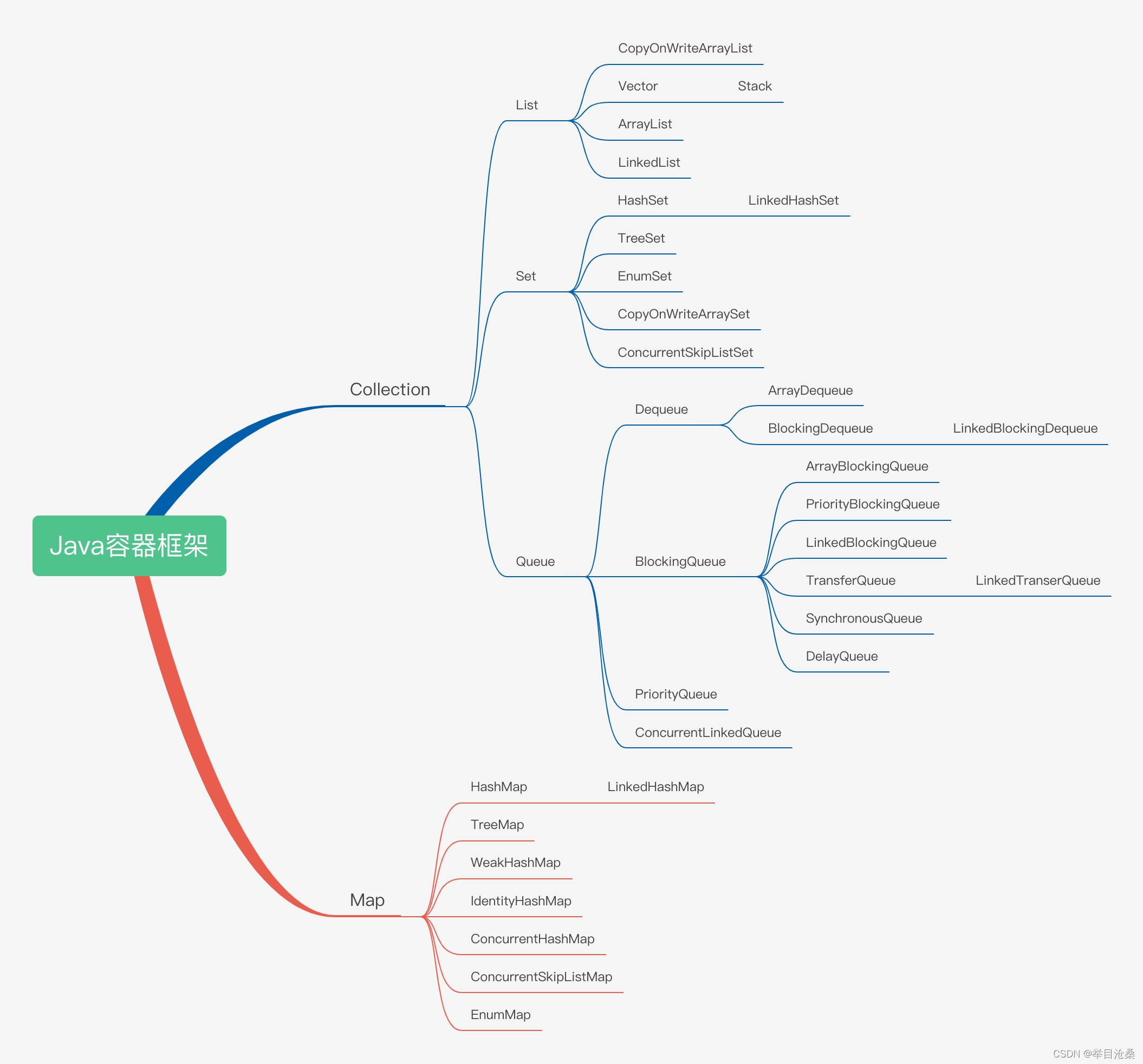
1.架构图 2.集合按照其存储结构分为两大类
1.单列集合Collection
2.双列集合Map
1.Collection是单列集合类的根接口 2.其继承自Iterable接口(为对象使用迭代器Iterator提供统一调用) 3.Collection包含多个子接口,其中比较重要的有
1.List接口
2.Set接口
3.Queue接口
4.AbstractCollection抽象类
public interface Iterable < T > {
Iterator < T > iterator ( ) ;
default void forEach ( Consumer < ? super T > ) {
Objects . requireNonNull ( action) ;
for ( T t : this ) {
action. accept ( t) ;
}
}
default Spliterator < T > spliterator ( ) {
return Spliterators . spliteratorUnknownSize ( iterator ( ) , 0 ) ;
}
}
1.Iterable接口的核心方法是iterator(),该方法的作用是返回一个Iterator对象,为Java对象提供迭代支持 2.Iterable接口也提供forEach方法用来迭代元素,执行消费器的accept方法 3.Iterable接口提供获取Spliterator可分割迭代器方法,用以支持集合的并发遍历 4.iterable接口主要是为了获取iterator从而获取迭代器的能力,附带了一个foreach()方法
public interface Iterator < E > {
boolean hasNext ( ) ;
E next ( ) ;
default void remove ( ) {
throw new UnsupportedOperationException ( "remove" ) ;
}
default void forEachRemaining ( Consumer < ? super E > ) {
Objects . requireNonNull ( action) ;
while ( hasNext ( ) )
action. accept ( next ( ) ) ;
}
}
1.iterator接口是为了定义遍历集合的规范,也是一种抽象,把在不同集合的遍历方式抽象出来,这样遍历时无需知道不同集合的内部结构 2.Iterator提供了集合和流操作等的遍历方式,是迭代器模式的应用 3.迭代器接口的函数比较简单,具体的实现交给子类实现 4.Iterator和Iterable的区别(为什么有Iterator还需要Iterable)
1.很多集合不直接实现Iterator接口,而是实现Iterable
2.Iterator接口的核心方法next()或者hashNext()等严重依赖于指针,即是迭代的目前的位置
3.如果Collection直接实现Iterator接口,那么集合对象就拥有了指针的能力,内部不同方法传递,就会让next()方法互相受到阻挠,只有一个迭代位置,互相干扰
4.Iterable 每次获取迭代器,就会返回一个从头开始的不会和其他的迭代器相互影响
1.List接口是Collection的子接口 2.List的存储特点
1.元素可以重复 2.元素可以为null 3.元素有序(存入和取出的顺序一致) 4.有下标(线性存储可以通过索引访问集合中的元素) 3.List接口的子类需要实现其抽象方法,具体API可查看List接口
1.ArrayList继承了AbstractList抽象类实现了List接口,说明ArrayList继承了AbstractList抽象类的一些方法以及需要实现两者的抽象方法 3.ArrayList类实现了RandomAccess接口,说明ArrayList可以对元素进行快速随机访问 4.ArrayList类实现了Serializable接口,说明ArrayList可以被序列化 5.ArrayList类实现了Cloneable接口,说明ArrayList可以被复制 6.ArrayList类在JDK1.2版本发布,线程不安全,但是效率高(线程安全和效率冲突) public class ArrayList < E > extends AbstractList < E > implements List < E > , RandomAccess , Cloneable , java. io. Serializable{
private static final long serialVersionUID = 8683452581122892189L ;
private static final int DEFAULT_CAPACITY = 10 ;
private static final Object [ ] EMPTY_ELEMENTDATA = {
} ;
private static final Object [ ] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {
} ;
transient Object [ ] elementData;
private int size;
public ArrayList ( int initialCapacity) {
if ( initialCapacity > 0 ) {
this . elementData = new Object [ initialCapacity] ;
} else if ( initialCapacity == 0 ) {
this . elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException ( "Illegal Capacity: " +
initialCapacity) ;
}
}
public ArrayList ( ) {
this . elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList ( Collection < ? extends E > ) {
elementData = c. toArray ( ) ;
if ( ( size = elementData. length) != 0 ) {
if ( elementData. getClass ( ) != Object [ ] . class )
elementData = Arrays . copyOf ( elementData, size, Object [ ] . class ) ;
} else {
this . elementData = EMPTY_ELEMENTDATA;
}
}
public void trimToSize ( ) {
modCount++ ;
if ( size < elementData. length) {
elementData = ( size == 0 )
? EMPTY_ELEMENTDATA
: Arrays . copyOf ( elementData, size) ;
}
}
public void ensureCapacity ( int minCapacity) {
int minExpand = ( elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
? 0
: DEFAULT_CAPACITY;
if ( minCapacity > minExpand) {
ensureExplicitCapacity ( minCapacity) ;
}
}
private void ensureCapacityInternal ( int minCapacity) {
if ( elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math . max ( DEFAULT_CAPACITY, minCapacity) ;
}
ensureExplicitCapacity ( minCapacity) ;
}
private void ensureExplicitCapacity ( int minCapacity) {
modCount++ ;
if ( minCapacity - elementData. length > 0 )
grow ( minCapacity) ;
}
private static final int MAX_ARRAY_SIZE = Integer . MAX_VALUE - 8 ;
private void grow ( int minCapacity) {
int oldCapacity = elementData. length;
int newCapacity = oldCapacity + ( oldCapacity >> 1 ) ;
if ( newCapacity - minCapacity < 0 )
newCapacity = minCapacity;
if ( newCapacity - MAX_ARRAY_SIZE > 0 )
newCapacity = hugeCapacity ( minCapacity) ;
elementData = Arrays . copyOf ( elementData, newCapacity) ;
}
private static int hugeCapacity ( int minCapacity) {
if ( minCapacity < 0 )
throw new OutOfMemoryError ( ) ;
return ( minCapacity > MAX_ARRAY_SIZE) ?
Integer . MAX_VALUE :
MAX_ARRAY_SIZE;
}
}
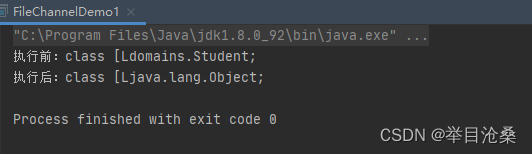
public static void main ( String [ ] args) {
Student [ ] students = new Student [ ] {
new Student ( "小明" , 18 ) ,
new Student ( "小李" , 19 ) ,
new Student ( "小张" , 21 )
} ;
Object [ ] objects = students;
System . out. println ( "执行前:" + objects. getClass ( ) ) ;
if ( objects. getClass ( ) != Object [ ] . class ) {
objects = Arrays . copyOf ( objects, objects. length, Object [ ] . class ) ;
}
System . out. println ( "执行后:" + objects. getClass ( ) ) ;
}
源码分析:
1.serialVersionUID :
1.应用于JAVA序列化机制,Java序列化通过判断类的serialVersionUID来验证版本是否一致
2.进行反序列化时,JVM会把传来的字节流中的serialVersionUID于本地相应实体类的serialVersionUID进行比较
3.如果相同说明是一致的,可以进行反序列化,否则会出现反序列化版本一致的异常,即InvalidCastException
4.因此赋予当前类一个固定的serialVersionUID,反序列化后即使改变也不会改变serialVersionUID,即被JVM认为是同一个class文件,不会出现版本不一致的问题
5.具体可参考JAVA SE文章中的序列化和反序列化
2.ArrayList容器底层是由数组实现
1.该数组的类型是Object类型,由transient修饰阻止被序列化,因此集合允许null的存在
2.其默认最小容量为10,由静态常量DEFAULT_CAPACITY指定,其和size不同,size表示当前集合元素个数,而capacity表示当前集合能存储多少个元素
3.ArrayList的构造函数
1.针对不同的构造函数,ArrayList使用不同的静态常量Object数组,且使用int类型的size表示数组中元素的个数
2.无参构造ArrayList()函数的使用静态常量数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA
3.有参构造ArrayList(int initialCapacity)函数
1.如果初始化容量>0则使用new关键字创建指定大小的Object数组
2.如果初始化容量=0则使用静态常量数组EMPTY_ELEMENTDATA
3.否则抛出异常IllegalArgumentException
4.此时集合没有元素size为0,但是elementData为初始化容量initialCapacity
4.有参构造ArrayList(Collection<? extends E> c)函数
1.首先通过toArray()方法将集合转换为Object类型的数组并将其引用赋值给elementData
2.如果集合的容量不为0且不是Object[]类型,则调用 Arrays.copyOf()方法将原对象数组的数组类型转化为Object[]的数组类型,以便更好的存储
3.否则使用静态常量数组EMPTY_ELEMENTDATA
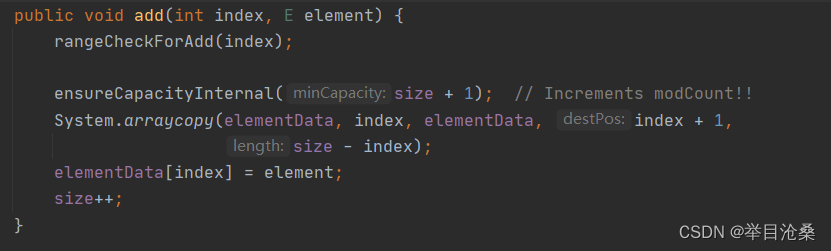
4.add()方法
1.带下标的add(int index, E element)方法比不带下标的add(E e)方法多了一个下标检验和数组复制方法
2.首先调用ensureCapacityInternal(int minCapacity)方法确定容量是否足够添加数据,如果当前集合为空,则赋予默认容量10
3.然后调用ensureExplicitCapacity(int minCapacity)方法确定容量是否需要扩容
4.如果最小容量大于集合的长度则需要扩容,调用grow(int minCapacity)方法进行扩容
5.首先将集合容量扩充到原来的1.5倍,如果此时容量还不足则直接当前将所需容量设置为集合的容量
6.判断当前容量是否小于指定的最大容量,如果大于则赋予2的31次方-1的最大容量,最后调用Arrays.copyOf(T[] original, int newLength)方法扩容数组
5.trimToSize()方法
1.由于集合中元素个数的size和表示集合容量的elementData.length可能不同,在不太需要增加集合元素的情况下容量有浪费
2.可以使用trimToSize()方法减小elementData的大小,其中modCount是继承自AbstractList中的字段,用来记录数组修改的次数,数组每修改一次,modCount加一
3.然后判断集合中元素个数是否小于集合的容量,如果小于再判断元素个数是否为0
4.如果为0就使用EMPTY_ELEMENTDATA对elementData进行初始化,否则使用Arrays工具类中的copyof方法进行数组复制,大小为size
6.ensureCapacity()方法
1.保证数组能够包含给定参数的个数,即如果有需要就扩大数组的容量
2.首先检查elementData是否是DEFAULTCAPACITY_EMPTY_ELEMENTDATA
3.如果是则使用默认容量10,如果不是将minExpand设置为0
4.然后比较minCapacity和minExpand的大小,如果所需最小容量大于最小扩展,则需要调用方法进行数组扩容
7.ensureCapacityInternal()方法
1.首先将minCapacity和默认大小10比较,将较大值设置为最小容量
2.然后调用ensureExplicitCapacity()方法判断是否需要扩容
8.ensureExplicitCapacity()方法
1.首先记录数组修改的次数的modCount先加1
2.然后将所需最小容量和集合当前长度进行比较
3.如果需要扩容则调用grow()方法进行扩容
9.grow()方法
1.实际的扩容方法
2.首先将容量增加为原来的1.5倍(位移运算符,左移一位代表乘以2,右移一位代表除以2)
3.如果还不够则用直接使用所需的容量minCapacity
4.ArrayList设置了数组的最大长度MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8,即Intger最大范围-8,Intger类型的最大范围为2的31次方-1
5.如果新容量超过MAX_ARRAY_SIZE,则调用函数hugeCapacity(minCapacity)检查是否溢出
6.如果新容量没有超过MAX_ARRAY_SIZE,则调用Arrays.copyOf()方法进行复制
10.hugeCapacity()方法
1.首先判断最小容量是否小于0,如果小于0则抛出OutOfMemoryError()
2.如果没有内存溢出则判断是否超过MAX_ARRAY_SIZE,如果超过则赋予Integer类型的最大值,如果没有超过,则直接赋予MAX_ARRAY_SIZE
11.多线程的使用场景中,使用线程安全的CopyOnWriteArrayList
1.LinkedList继承了AbstractSequentialList抽象类实现了List接口,说明LinkedList继承了AbstractSequentialList抽象类的一些方法以及需要实现两者的抽象方法 2.LinkedList实现了实现了Deque(双端队列)接口,说明LinkedList支持队列操作 3.LinkedList类实现了Serializable接口,说明LinkedList可以被序列化 4.LinkedList类实现了Cloneable接口,说明LinkedList可以被克隆 5.ArrayList类在JDK1.2版本发布,线程不安全,但是效率高(线程安全和效率冲突) public class LinkedList < E > extends AbstractSequentialList < E > implements List < E > , Deque < E > , Cloneable , java. io. Serializable{
transient int size = 0 ;
transient Node < E > ;
transient Node < E > ;
public LinkedList ( ) {
}
public LinkedList ( Collection < ? extends E > ) {
this ( ) ;
addAll ( c) ;
}
. . .
private static class Node < E > {
E item;
Node < E > ;
Node < E > ;
Node ( Node < E > , E element, Node < E > ) {
this . item = element;
this . next = next;
this . prev = prev;
}
}
}
源码分析:
1.LinkedList提供了三个无法被序列化的成员变量
1.size:为链表的元素个数
2.first:为链表的头节点
3.last:为链表的尾节点
2.LinkedList提供了静态内部类Node
1.用来定义存储的数据结构,一个Node代表一个数据节点,可用泛型指定范围
2.其中Node类包含next和prev两个属性,prev代表前一个节点,prev代表后一个节点,其属于典型的双向链表
3.LinkedList容器底层由双向链表实现,因此插入删除效率高,查找效率低
4.链表不存在类似数组容量不足的问题,所以没有扩容的方法
3.LinkedList的构造函数
1.LinkedList()无参构造方法是一个空方法,其创建的是一个空的集合,此时的size为0,first和last都指向null
2.LinkedList(Collection<? extends E> c)有参构造
1.首先调用无参构造初始化一个空的集合
2.然后调用addAll(Collection<? extends E> c)方法将集合中的元素都加入其中
4.add(E e)方法
1.调用linkLast(E e)方法链接对象E作为最后一个元素,然后返回true
5.linkLast(E e)
1.实际添加元素的方法
2.首先获取最后一个节点并将其赋给一个常量Node对象l
3.然后创建一个新的节点,该节点的前一个节点为Node对象l,后一个节点为null
4.然后把这个新节点赋予最后一个节点引用
5.判断最后一个节点是否是null,即该集合是否为空,如果为空,则将新节点作为first,否则将新节点作为集合最后节点的下一个节点
6.集合大小size加1,并将修改记录modCount加1
1.Vector继承了AbstractList抽象类实现了List接口,说明Vector继承了AbstractList抽象类的一些方法以及需要实现两者的抽象方法 2.Vector类实现了RandomAccess接口,说明Vector可以对元素进行快速随机访问 3.Vector类实现了Serializable接口,说明Vector可以被序列化 4.Vector类实现了Cloneable接口,说明Vector可以被克隆 5.Vector类在JDK1.0版本发布,线程安全,但是效率低(线程安全和效率冲突)
public class Vector < E > extends AbstractList < E > implements List < E > , RandomAccess , Cloneable , java. io. Serializable{
protected Object [ ] elementData;
protected int elementCount;
protected int capacityIncrement;
private static final long serialVersionUID = - 2767605614048989439L ;
public Vector ( int initialCapacity, int capacityIncrement) {
super ( ) ;
if ( initialCapacity < 0 )
throw new IllegalArgumentException ( "Illegal Capacity: " +
initialCapacity) ;
this . elementData = new Object [ initialCapacity] ;
this . capacityIncrement = capacityIncrement;
}
public Vector ( int initialCapacity) {
this ( initialCapacity, 0 ) ;
}
public Vector ( ) {
this ( 10 ) ;
}
public Vector ( Collection < ? extends E > ) {
elementData = c. toArray ( ) ;
elementCount = elementData. length;
if ( elementData. getClass ( ) != Object [ ] . class )
elementData = Arrays . copyOf ( elementData, elementCount, Object [ ] . class ) ;
}
public synchronized void copyInto ( Object [ ] anArray) {
System . arraycopy ( elementData, 0 , anArray, 0 , elementCount) ;
}
public synchronized void trimToSize ( ) {
modCount++ ;
int oldCapacity = elementData. length;
if ( elementCount < oldCapacity) {
elementData = Arrays . copyOf ( elementData, elementCount) ;
}
}
public synchronized void ensureCapacity ( int minCapacity) {
if ( minCapacity > 0 ) {
modCount++ ;
ensureCapacityHelper ( minCapacity) ;
}
}
private void ensureCapacityHelper ( int minCapacity) {
if ( minCapacity - elementData. length > 0 )
grow ( minCapacity) ;
}
private static final int MAX_ARRAY_SIZE = Integer . MAX_VALUE - 8 ;
private void grow ( int minCapacity) {
int oldCapacity = elementData. length;
int newCapacity = oldCapacity + ( ( capacityIncrement > 0 ) ?
capacityIncrement : oldCapacity) ;
if ( newCapacity - minCapacity < 0 )
newCapacity = minCapacity;
if ( newCapacity - MAX_ARRAY_SIZE > 0 )
newCapacity = hugeCapacity ( minCapacity) ;
elementData = Arrays . copyOf ( elementData, newCapacity) ;
}
private static int hugeCapacity ( int minCapacity) {
if ( minCapacity < 0 )
throw new OutOfMemoryError ( ) ;
return ( minCapacity > MAX_ARRAY_SIZE) ?
Integer . MAX_VALUE :
MAX_ARRAY_SIZE;
}
源码解析:
1.Vector底层是由数组实现
1.该数组类型Object,与ArrayList不同的是其可以被序列化
2.与ArrayList不同Vector用elementCount表示实际存储的元素个数
3.capacityIncrement属性表示每次扩充的容量
2.Vector的构造函数
1.Vector()无参构造实际调用Vector(int initialCapacity)有参构造,并默认初始值为10
2.Vector(int initialCapacity)有参构造实际调用Vector(int initialCapacity, int capacityIncrement)有参构造,并默认初始增量为0
3.Vector(int initialCapacity, int capacityIncrement)有参构造
1.默认调用父类AbstractList的无参构造
2.然后判断初始化容量是否非法,如果非法则抛出IllegalArgumentException异常
3.通过new新建一个容量为initialCapacity的Object数组且将其引用赋给elementData
4.最后将增量赋值给capacityIncrement
4.Vector(Collection<? extends E> c)有参构造
1.将集合转换为Object数组
2.将数组的长度赋值给elementCount
3.判断集合的类型是否为Object[],如果不是通过调用Arrays.copyOf()方法将其转换为Object类型的数组,方便存储
3.ensureCapacity(int minCapacity)方法
1.确保容量,如果所需最小容量大于0,则记录修改次数加1
2.然后调用ensureCapacityHelper(minCapacity)方法
4.ensureCapacityHelper(int minCapacity)方法
1.如果所需最小容量大于当前集合容量,则调用grow()方法进行扩容
5.grow(minCapacity)方法
1.首先将集合的长度复制给oldCapacity
2.如果扩容的增量大于0,则扩容后大小为原容量+所需扩容的增量,否则扩容后大小为原容量的两倍
3.如果新的容量还是小于所需最小容量,则直接把新的容量设置为所需最小容量
4.如果新的容量大于设置的最大数组容量则检查是否内存溢出,如果没有溢出则赋值Intger类型最大值
5.最后调用Arrays.copyOf()扩容数组并将其引用赋值给elementData
6.add(E e)方法
1.首先将记录修改次数的modCount加1
2.然后确保容量是否足够,如果不足则扩容
3.将elementData数组的末尾的值设置为e,并将集合元素个数elementCount加1
7.注意Vector和ArrayList最大的不同是Vector的方法部分使用了synchronized加锁,多线程安全但效率低
1.Set接口是Collection的子接口,表示唯一对象的集合 2.Set的存储特点
1.元素不可以重复 2.元素可以为null 3.元素无序(存入和取出的顺序不一致) 4.无下标(不可以指定位置访问)
1.HashSet继承了AbstractSet抽象类实现了Set接口 2.HashSet类实现了Serializable接口,说明HashSet可以被序列化 3.HashSet类实现了Cloneable接口,说明HashSet可以被克隆 4.HashSet类在JDK1.2版本发布,线程不安全 public class HashSet < E > extends AbstractSet < E > implements Set < E > , Cloneable , java. io. Serializable{
static final long serialVersionUID = - 5024744406713321676L ;
private transient HashMap < E , Object > ;
private static final Object PRESENT = new Object ( ) ;
public HashSet ( ) {
map = new HashMap < > ( ) ;
}
public HashSet ( Collection < ? extends E > ) {
map = new HashMap < > ( Math . max ( ( int ) ( c. size ( ) / .75f ) + 1 , 16 ) ) ;
addAll ( c) ;
}
public HashSet ( int initialCapacity, float loadFactor) {
map = new HashMap < > ( initialCapacity, loadFactor) ;
}
public HashSet ( int initialCapacity) {
map = new HashMap < > ( initialCapacity) ;
}
}
源码分析:
1.HashSet的内部实际使用HashMap存储数据,HashSet本质是操作HashMap的key,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap 2.HashSet中的集合元素实际上由HashMap的key保存,而HashMap的value则存储了一个PRESENT,它是一个Object类型的静态常量,即定义一个虚拟的Object对象作为HashMap的value 3.HashSet不能存放null值,因为add时会调用compare()方法,此时会调用对象的compareTo()方法进行比较从而会抛出NullPointerException
4.注意:试图把某个类的对象当成HashMap的key或试图将这个类的对象放入HashSet中保存时,需要重写该类的equals(Object obj)方法和hashCode()方法
1.因为HashSet底层使用的是HashMap
2.HashMap添加元素的时候,先调用key的hashCode方法得到key的哈希值 ,然后通过key的哈希值经过移位等运算算出该元素在table中的存储位置
3.如果位置目前没有任何元素,则该元素可以直接存储在该位置上
4.否则会调用该key的equals方法与该位置的key再比较一次
5.如果equals方法返回的是true,那么该位置上的元素视为重复元素,直接覆盖,如果返回的是false,则添加元素
5.重写hashcode原因
1.通过HashMap中的源码可以看到HashSet在进行添加底层使用到了hash方法,而hash值的获取实际上是在hashCode基础上的一系列操作 2.如果不重写hashcode,用的则是从Object继承下来的hashCode,而这个hashCode每次new一个对象就会有不同的值;所以就造成了上面的对象中的内容即使一样 但还是被认为是不同的元素,因为每次存入时都是new了一个新对象,就造成了hash值一直不同
6.重写equals原因:
因为hash值毕竟只是一个逻辑值,不同的对象有几率出现相同的hash值(称为哈希碰撞)。如果不同的对象出现了相同的hash值就需要使用equals进行再次判断,才能确保两个对象是否相同
1.LinkedHashSet继承了HashSet类实现了Set接口 2.LinkedHashSet类实现了Serializable接口,说明HashSet可以被序列化 3.LinkedHashSet类实现了Cloneable接口,说明HashSet可以被复制 4.LinkedHashSet类在JDK1.4版本发布,线程不安全 public class LinkedHashSet < E > extends HashSet < E > implements Set < E > , Cloneable , java. io. Serializable{
private static final long serialVersionUID = - 2851667679971038690L ;
public LinkedHashSet ( int initialCapacity, float loadFactor) {
super ( initialCapacity, loadFactor, true ) ;
}
public LinkedHashSet ( int initialCapacity) {
super ( initialCapacity, .75f , true ) ;
}
public LinkedHashSet ( ) {
super ( 16 , .75f , true ) ;
}
public LinkedHashSet ( Collection < ? extends E > )










 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









